Working Backwards - プレスリリースから始める社内勉強会
この記事はさくらインターネット Advent Calendar 2023 5日目の記事です。
こんにちは、さくらインターネットの山本です。去年に引き続きSRE室という部署で働いています。
最近は
- 某プロダクトのOpenTelemetry対応の一環としてSigNozを試験導入/運用
- ログ解析基盤のDBをMariaDBからClickHouseに移行
- 新規プロダクトチームへスクラムを導入
- チームが自立自走できるようにするためのチーム運営支援
というあたりを担当しておりました。
今回の記事について
今回はチーム運営支援の一環としてファシリテーション/ファシリテーショングラフィックについての社内勉強会を企画した時にWorking Backwardsという考え方を取り入れてみたのでその体験談を投稿いたします。
「Working Backwards」とは
Working Backwardsとはこちらの記事によると
Working Backwardsでは「お客様は誰ですか?」 から始まる5つの質問を通じて、本当に必要なサービスを企画・開発していく。
具体的にはプレスリリースを書くことでこれからつくるプロダクトやサービスを明確にし、FAQを作成することでより具体的な体験として考えるための手法である。
(引用元: Amazonのイノベーションを支える「Working Backwards」とは?)
とのことです。
ファシリテーション勉強会を開催するにあたり@zembutsuさんに相談したところこの手法を使ってみてはどうか?とアドバイスいただいたため早速使ってみることにしました。
「プレスリリース」と「FAQ」を通じて企画を考える
今回は社内勉強会のため実際にプレスリリースを出すわけではないですが、参加者を募る際には勉強会についてのアナウンスを行いますのでそれをプレスリリースと見なすことにしました。
まずはじめにお客様を「全社員のうちファシリテーションを学びたい方々」とし、「望ましい顧客体験とは何か?」というところから考えてみました。
「望ましい顧客体験」を考えてみる
せっかく参加するなら1人で読書するだけでは得られないものが欲しいな、とか 今感じている問題を解決できたら嬉しいな、すぐに業務に役に立つ/業務が改善できるものだと嬉しいな、などと考えた結果以下2つを望ましい顧客体験と定義しました。
- 座学だけではなく体験や実践ができること
- 業務に直接役立つ学びがあること
「望ましい顧客体験」から逆算して詳細を考えてみる
次に定義した望ましい顧客体験を実現するために必要な要素を考えてみました。
座学だけではなく体験や実践ができること
- 教師−生徒という関係だと座学みたいになりそうだから「学びたい人たちが集まって自分たちで学ぶ」ようにしよう
- なるべく一人一人がたくさんの体験/実践を出来るように少人数のグループ制にしよう
業務に直接役立つ学びがあること
- 何を目指す勉強会なのか明確にしよう
- ファシリテーションが役に立つようなシチュエーションを詳細にイメージできるようにしよう
- 具体的なツールの使い方についても学べる/体験できるようにしよう
「FAQ」を考えて詳細を詰める
次に「自分が勉強会に参加するのであれば何が気になるか?」という視点からFAQを考えて詳細を詰めることにしました。 ここではオーソドックスに5W1Hの視点を用いました。
Why: なぜ?
What:何を?
- Q: この勉強会に参加すると何を得られるのですか?
When: いつ?
Q: どれくらいの期間なのか?
- A: 毎週1回/全8回を想定
Q: どのくらいの時間を使うのか?
- A: 勉強会が毎回1時間とすると全8回で8時間、事前に教材を読む時間として2時間程度、合計10時間程度
Where: どこで?
- Q: この勉強会はどこで開催されるのですか?
- A: 弊社ではリモートワークを前提とした働き方を採用しているためこれに合わせフルリモートで開催
Who:だれが?
- Q: 参加するためにどのような資格(役職/職位)が必要ですか?
How:どのように?
Q: 具体的にどのような進め方をするのですか?イメージができないと不安/怖いです
- A: 全8回を想定、人数としては5〜20人程度を想定しており、5人程度に分かれてグループワークする
Q: 事前に何か準備が必要ですか?
- A: 事前に書籍を購入する
Q: 教材はどのように買えば良いですか?費用負担は誰がしますか?
- A: 各自で購入 & 費用は会社負担(各自で経費精算する)
Q: 読書は業務時間内に行っても良いですか?
- A: OK、ただし上長とは相談しておくこと
これらを盛り込んでプレスリリースを作成
次にここまでに考えた望ましい顧客体験やその詳細、FAQを元にプレスリリースの文面を作成しました。
【告知】ファシリテーション勉強会の開催について
# 概要と目的
ミーティング/会議に参加していてこのような問題を感じたことはありませんか?
- 司会者が一方的に話すだけ、静かで居心地が悪い
- 発言があっても質疑応答のみになっている
- 一部の人だけが発言している
- 自分が参加する意義を感じられない
- 議論はしているが議題があちこちに飛んでしまい、今何を議論しているのかわからなくなることがある
この勉強会では上記のような問題の解決を目指すために、ファシリテーションについて学び、実践し、
ファシリテーターとしてのマインドセットやスキル、ツールの活用方法などを習得することを目指します。
# この勉強会で学べること
- ファシリテーションのマインドセット
- ファシリテーション・グラフィックをはじめとしたファシリテーションのスキル
- Miroなどのオンラインホワイトボードの使い方
# 想定参加者
どなたでもご参加いただけます。役職や職位、所属部門などの制限はありません。
- 会議をより実り多いものにしたい方
- チームメンバーにもっと積極的に会議/MTGに参加してほしいと感じているチームリーダー/マネージャー
- 会議で発言しにくさを感じているチームメンバー
人数は5~20人程度を想定しています。1グループ5人程度に分かれてワークを行う予定です。
# 参加方法
- 次のURLからご参加ください。 https://example.com/xxx
- 連絡用にSlackの #xxx にご参加ください。
- 当日はZoomでご参加ください。
- 不明点があれば@xxxまたは@yyyまでお問い合わせください。
# 教材と教材費について
教材として以下を利用します。
- ファシリテーション・グラフィック[新版] 議論を「見える化」する技法 (堀公俊, 加藤彰)
各自で購入して経費精算してください。
経費精算時の予算コードはxxxをご利用ください。
# 勉強会の進め方
毎週1回/全8回を予定しています。各回は1時間の予定です。
- 第1回: オリエンテーション
- 第2回: 読書会 & 共有会 (1周目)
- 第3回: 実践会(1周目)
- 第4回: ふりかえり会(1周目)
- 第5回: 読書会 & 共有会(2周目)
- 第6回: 実践会(2周目)
- 第7回: ふりかえり会(2周目)
- 第8回: 全体のふりかえり会
# その他注意点
- この勉強会は講習(先生−生徒の関係)ではありません。各自が自分自身で学ぶことを重視します。
- この勉強会は学んだことの共有/議論/実践の場です。
- 読書は上長と相談の上で業務時間中に行なってください。
募集開始 〜 開催
作成したプレスリリースを用いて実際に参加者を募集をしてみました。

当初は10人くらい集まれば十分かなと思っていたのですが、予想に反し上限の20人を超える参加申し込みがありました。
想定参加者や目指す姿を書いておいたからか参加者の熱量は高く、とても充実した勉強会を開催できました。
ふりかえり
勉強会を開催しようとした当初は毎週集まって輪読会をする、くらいのぼんやりとしたイメージしか持てていなかったのですが、 プレスリリースやFAQを作成することを通じて半強制的に具体的なイメージを持てました。
例えばグループ分けについて当初は考え至っていなかったのですが、参加者目線で「座学だけではなく体験や実践ができること」を実現するために何が必要か考えたところ大人数ではファシリテーターをやる機会がなかなか回ってこないという問題に気付き少人数のグループ制にするというアイディアを思いつきました。
今回はあまり関係なかったですが、参加者目線から考えることで企画者がやりたいことと参加者の求めることのギャップにも気付けるというあたりはアジャイルなプロダクト開発ととても相性が良さそうに感じました。
おわりに
社内勉強会にWorking Backwardsという考え方を取り入れてみた体験談をお届けしました。
何かの参考になれば幸いです。
今回は以上です。お読みいただきありがとうございました。
参考文献
![ファシリテーション・グラフィック[新版] 議論を「見える化」する技法 (日本経済新聞出版)](https://m.media-amazon.com/images/I/41U6WwnGlzL._SL500_.jpg "ファシリテーション・グラフィック[新版] 議論を「見える化」する技法 (日本経済新聞出版)")
opentelemetry-go: exec.Commandで外部コマンドを呼ぶ時にトレースコンテキストを伝搬させる
exec.Commandで外部コマンドを起動する時にトレースコンテキストを伝搬させてみました
今回のコード例
環境変数+propagation.TraceContextを利用することで伝搬させてみました。
解説
httpやgRPCの場合のコンテキスト伝搬
こちらの記事にあるように、呼び出す側/呼び出される側の両方で以下のようにPropagatorを設定した上でotelhttpやotelgrpcなどのインターセプターを利用します。
otel.SetTextMapPropagator(
propagation.NewCompositeTextMapPropagator(
propagation.TraceContext{},
propagation.Baggage{},
),
)
exec.Commandで外部コマンドを起動する時にはotelhttpやotelgrpcのようなインターセプターがありませんので自前でInject/Extractする必要があります。
どうやってトレースコンテキストを渡す?
W3C TraceContextのような仕様がないか探したのですが、いくつかの実装はあるものの仕様としてはまだない模様でした。
そこで参考としてequinix-labs/otel-cliでの環境変数経由でトレースコンテキストを参照する部分の実装をみたところ、
となっていました。
これならpropagation.TraceContextの実装が使えるのでは?
上記の仕様で渡すのであればpropagation.TraceContextが使えそうです。
propagation.TraceContextは引数で渡されたpropagation.TextMapCarrierに対して読み書きを行います。
環境変数をなんらかの形でラップしてpropagation.TextMapCarrierの形にした上でInject/Extractを呼べばなんとかできそうです。
やってみた
改めて今回のコード例はこちらに置いています。
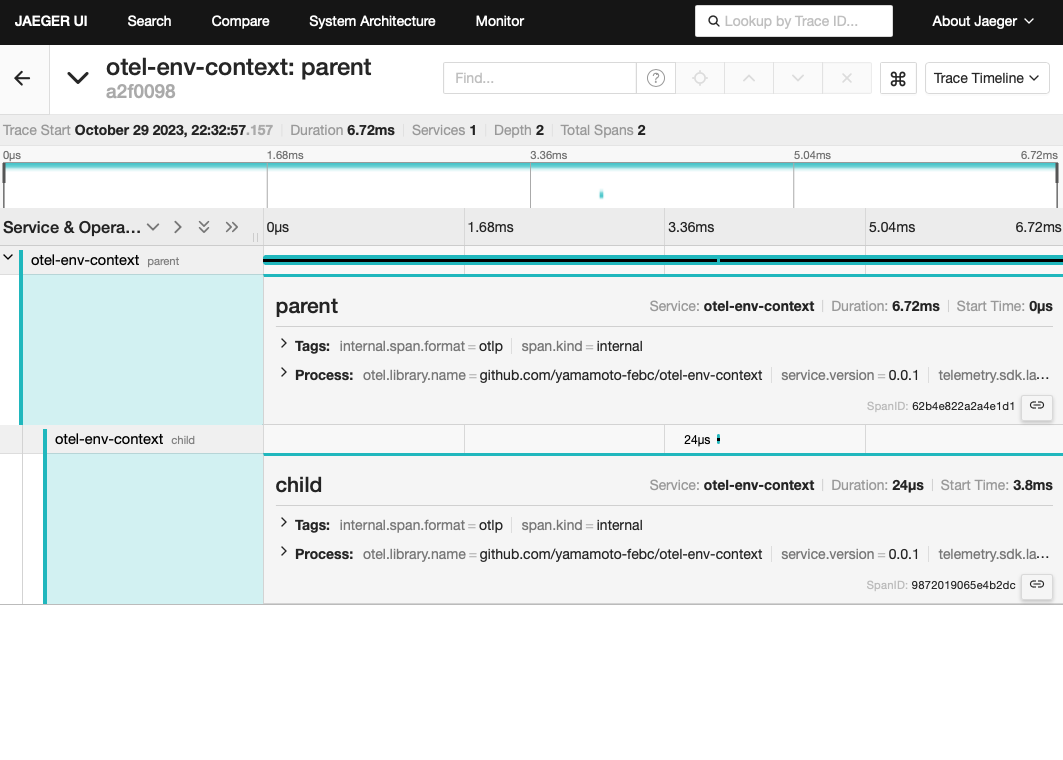
親コマンド側では以下のようにotel.GetTextMapPropagator().Inject()した上で環境変数を組み立てています。
https://github.com/yamamoto-febc/otel-env-context/blob/6db0d50cbf473c8c3095413657da234a57c63ddb/cmd/otel-parent/main.go#L47-L51
// 親コマンド側 // Propagatorに指定されているpropagation.TraceContextを用いてトレースコンテキストをenvCarrierに書き出し envCarrier := propagation.MapCarrier{} otel.GetTextMapPropagator().Inject(ctx, envCarrier) // 書き出したトレースコンテキストを環境変数に設定 for _, key := range envCarrier.Keys() { cmd.Env = append(cmd.Env, key+"="+envCarrier.Get(key)) }
子コマンド側ではotel.GetTextMapPropagator().Extract()してあげます。
https://github.com/yamamoto-febc/otel-env-context/blob/4f30a8c453d64b567eecae2301226327114f1a5e/cmd/otel-child/main.go#L27-L33
// 子コマンド側 envCarrier := propagation.MapCarrier{ "traceparent": os.Getenv("traceparent"), "tracestate": os.Getenv("tracestate"), } // 環境変数からトレースコンテキストを抽出 parentCtx := otel.GetTextMapPropagator().Extract(context.Background(), envCarrier) // トレース開始 ctx, span := otel.Tracer(instrumentationName).Start(parentCtx, "child")
これでいい感じにトレースコンテキストの伝搬ができてるはずです。
終わりに
もっといいやり方があれば是非教えてください。
以上です。
参考にしたサイト
christina04.hatenablog.com blog.cybozu.io www.w3.org github.com

オープンソースAPMのSigNoz + さくらのクラウド オブジェクトストレージ
はじめに
最近お仕事でSigNozを使ってみました。
その中でSigNoz(が使っているClickHouse)のCold Storageとしてさくらのクラウド オブジェクトストレージを使ってみましたので利用手順などのメモを残しておきます。
SigNozとは
オープンソースのAPM & オブザーバビリティツールとのことです。
GitHubリポジトリのdescriptionには以下のように書かれています。
SigNoz is an open-source APM.
It helps developers monitor their applications & troubleshoot problems,
an open-source alternative to DataDog, NewRelic, etc. 🔥 🖥.
👉 Open source Application Performance Monitoring (APM) & Observability tool
DataDogやNewRelicの代替という位置付けを狙っているようですね。
OpenTelemetryに対応しており、メトリクス・トレース・ログをまとめて見ることが出来ます。
GIGAZINEでも紹介されていました。
類似のプロダクトとしてはhyperdxやuptraceなどがあります。
(uptraceはgo言語向けのORMであるBunを開発しているところです)
- hyperdx: http://hyperdx.io
- uptrace: http://uptrace.dev
なおSigNoz CloudというSaaS形態での利用も可能ですが、今回は手元にインストールして利用するOSS版を利用しました。
SigNozのシステム構成
SigNozのドキュメントによると以下のような構成とのことです。
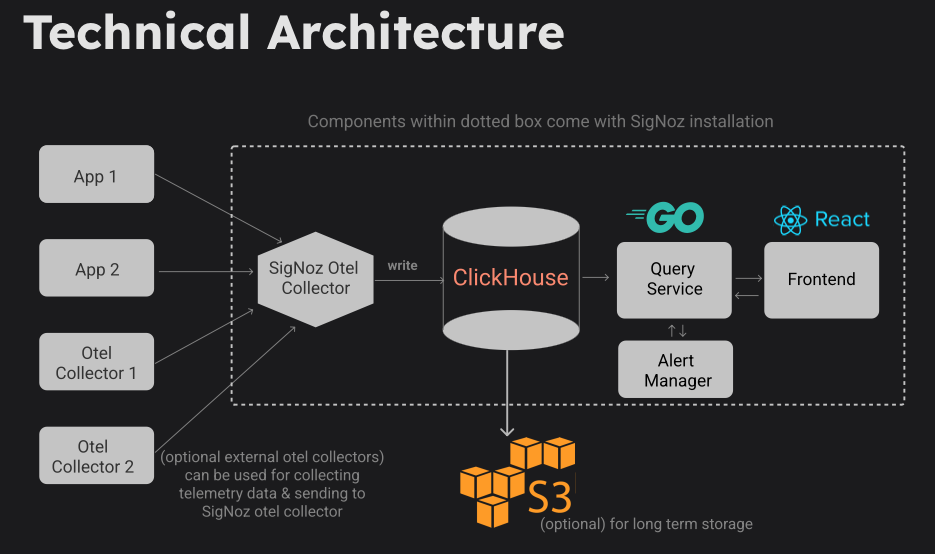
SigNoz Otel Collectorに送信されたデータをClickHouseに書き込むという構成です。
ClickHouseのディスクとしてS3(互換含む)を用いることも可能です。
参考: SigNoz docs: Retension Period
今回はS3の代わりにさくらのクラウド オブジェクトストレージを使ってみました。
SigNoz + さくらのクラウド オブジェクトストレージ
利用までの手順
SigNoz + ClickHouseのディスクとしてさくらのクラウド オブジェクトストレージを使うための手順は以下の通りです。
- さくらのクラウド オブジェクトストレージ側の準備
- SigNozのインストール/セットアップ(今回はdocker composeを利用)
- ClickHouseの設定(設定ファイルの編集)
- SigNozダッシュボード上から保存期間(Retention Period)を設定
さくらのクラウド オブジェクトストレージ側の準備
バケット & 各種操作をするためのパーミッションを作成します
詳細はさくらのクラウド オブジェクトストレージのドキュメントを参照してください。
参考: https://manual.sakura.ad.jp/cloud/objectstorage/about.html#id8
パーミッション作成時に表示される「アクセスキーID」と「シークレットアクセスキー」を控えておいてください。
後ほどClickHouseの設定時に利用します。
SigNozのインストール/セットアップ(docker compose)
SigNozのセットアップを行います。今回はdocker composeを使います。
以下のドキュメントに従いSigNozのリポジトリをクローン、設定ファイルを編集した上でdocker compose upを実行という流れです。
参考: https://signoz.io/docs/install/docker/
クローン
# クローン git clone -b main https://github.com/SigNoz/signoz.git && cd signoz/deploy/docker/clickhouse-setup
ClickHouseの設定(設定ファイルの編集)
ClickHouseの設定ファイルを編集しさくらのクラウド オブジェクトストレージを使えるようにします。
カレントディレクトリであるclickhouse-setup配下にclickhouse-storage.xmlというファイルがありますので以下のように編集します。
{バケット名}と{アクセスキーID}、{シークレットアクセスキー}は置き換えてください。
<?xml version="1.0"?> <clickhouse> <storage_configuration> <disks> <default> <keep_free_space_bytes>10485760</keep_free_space_bytes> </default> <s3> <type>s3</type> <endpoint>https://s3.isk01.sakurastorage.jp/{バケット名}//</endpoint> <access_key_id>{アクセスキーID}</access_key_id> <secret_access_key>{シークレットアクセスキー}</secret_access_key> <region>jp-north-1</region> <no_sign_request>false</no_sign_request> </s3> </disks> <policies> <tiered> <volumes> <default> <disk>default</disk> </default> <s3> <disk>s3</disk> <perform_ttl_move_on_insert>0</perform_ttl_move_on_insert> </s3> </volumes> </tiered> </policies> </storage_configuration> </clickhouse>
次にdocker-compose.yamlを編集し、volume指定部分でのclickhouse-storage.xmlのところのコメントアウトを解除します。
@@ -107,7 +107,7 @@ services:
- ./clickhouse-users.xml:/etc/clickhouse-server/users.xml
- ./custom-function.xml:/etc/clickhouse-server/custom-function.xml
- ./clickhouse-cluster.xml:/etc/clickhouse-server/config.d/cluster.xml
- # - ./clickhouse-storage.xml:/etc/clickhouse-server/config.d/storage.xml
+ - ./clickhouse-storage.xml:/etc/clickhouse-server/config.d/storage.xml
- ./data/clickhouse/:/var/lib/clickhouse/
- ./user_scripts:/var/lib/clickhouse/user_scripts/
SigNozの起動
あとはDocker Composeで起動します。
docker compose up -d
起動したらhttp://localhost:3301でダッシュボードにアクセスできるはずです。
SigNozダッシュボード上から保存期間(Retention Period)を設定
あとはどれくらいの期間がすぎたらS3に移動させるかを設定します。
ダッシュボードからSettings(localhost:3301であれば http://localhost:3301/settings )を開いて設定します。
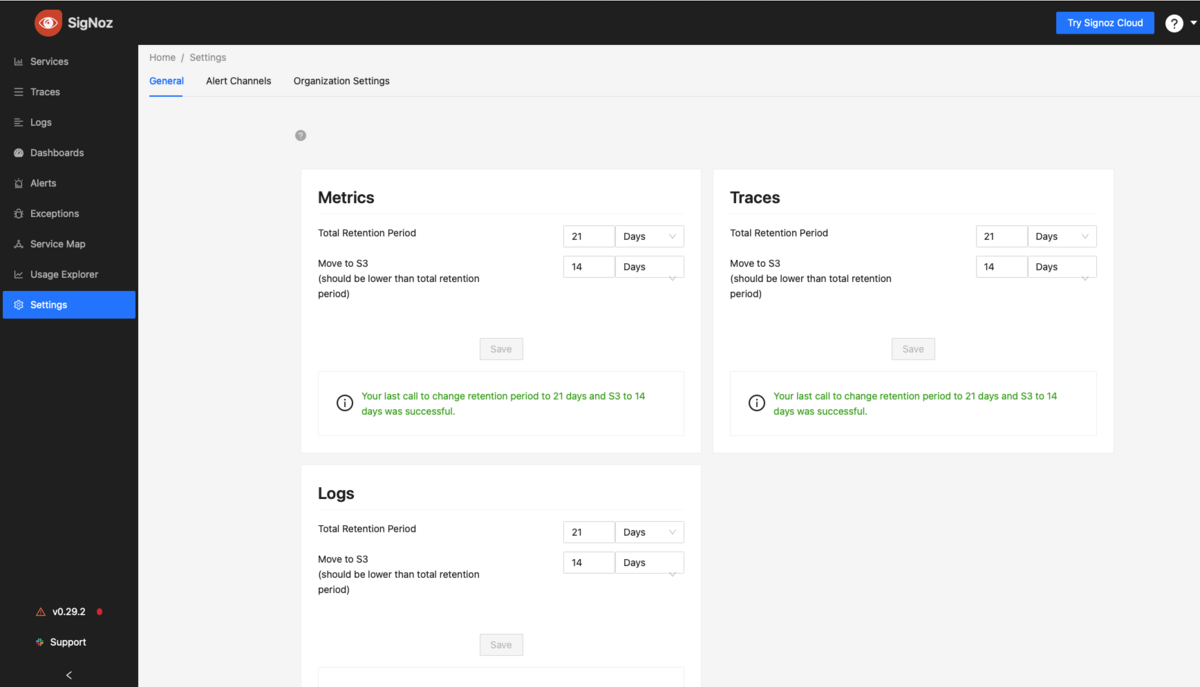
この例ではトータルの保存期間を21日、14日をすぎたらS3に移動させるという設定になっています。
これでSigNoz + さくらのクラウド オブジェクトストレージが使えるようになりました。
終わりに
SigNozはメトリクス・トレース・ログを一箇所で見える環境を手軽に作れるというあたりが魅力的だと思います。
気になるのはデータ量についてですが、オブジェクトストレージをCold Storageとして活用することでコストを押さえつつデータの増加にも耐えられそうです。
これからもう少し使い込んでみようと思います。
以上です。
Mailosaurでメール送信のE2Eテスト
最近MailosaurというSaaSを使ってメール送信機能をテストしてみましたので、備忘がてら紹介メモを残しておきます。
Mailosaurとは?
Mailosaurとは Email and SMS testing platformだそうです。
メールがちゃんと送れているか?だとかメール本文/添付ファイルなどは意図通りか?をテストするのに便利な機能が提供されています。
Mailosaurってなんて読むの?
以下の動画をみたところ、カタカナだと「メイラソー」のように呼ばれていました。
どんなことができるの?
EメールやSMS関連のテストを行うための様々な便利機能が提供されています。
詳細は以下のドキュメントに記載されています。
例えばEメール関連ですと以下のような機能が提供されています。(上位プランのみの機能も含まれます)
テスト用メールボックスの提供
任意の名前@サーバID.mailosaur.netのようなメールアドレスが提供されます。このアドレス向けにテストしたいメールを送ることで、送信できているかや内容が正しいかなどをコードから確認することが可能です。
API経由でのメール送信/転送/返信
APIを用いて送信/転送/返信が行えます。
これによりユーザーからのメールを契機にスタートするようなプロセスなどもE2Eテストが行えます。
単純なテキストだけでなく添付ファイルなどにも対応しており、多彩なシナリオに対応できそうです。
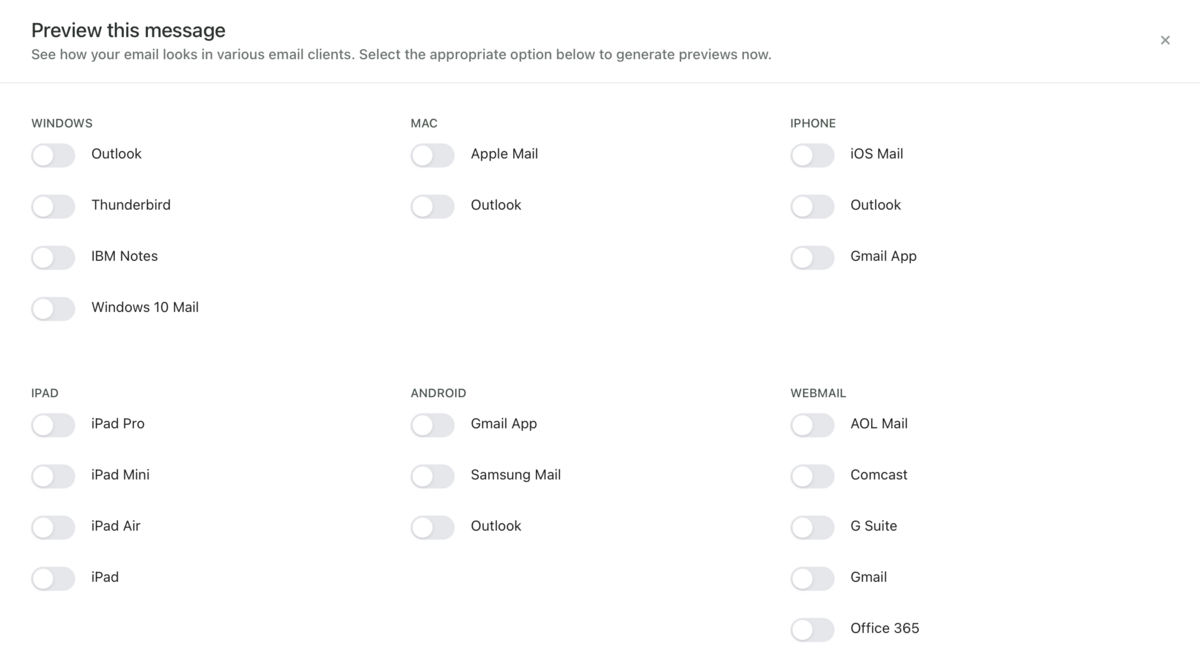
プレビュー生成機能
様々なメールクライアント上でメールがどのように表示されるかをプレビューする機能です。 以下のように様々な環境がサポートされています。
その他
そのほかにもPOP3/SMTPサーバも提供されていたりします。
類似/競合サービス
類似/競合サービスとしては以下のようなものもあります。
機能面、価格面、各言語向けSDK/ライブラリの充実状況、法人利用ができるライセンスか?などを考慮した結果、今回はMailosaurを選択しました。
自前でメールサーバを建ててもよかったのですが、$9~で手軽にAPIからメール操作ができるというのは非常に嬉しいところでした。
また、MailosaurはGo言語向けのSDK/ライブラリを提供しているのもポイント高かったです。
(テストしたいアプリケーションがGoで書かれていたため)
なお、Mailosaurは以下の言語/プラットフォームに対応しています。
使い方
以下に各言語/プラットフォーム向けのドキュメントが用意されています。
例えばGoだと以下のようなコードでMailosaurで発行したメールアドレスに対して送信したメールを確認できます。
(このコードでは受信したメールのサブジェクトをfmt.Printlnしています)
package emailtests import ( "fmt" "testing" "github.com/mailosaur/mailosaur-go" ) func TestExample(t *testing.T) { // Available in the API tab of a server apiKey := "YOUR_API_KEY"; serverId := "SERVER_ID"; serverDomain := "SERVER_DOMAIN"; m := mailosaur.New(apiKey); params := &mailosaur.MessageSearchParams { Server: serverId, } criteria := &mailosaur.SearchCriteria { SentTo: "anything@" + serverDomain, } email, err := m.Messages.Get(params, criteria) if (err != nil) { t.Error(err) } // If we have an email, print the subject fmt.Println("Subject: " + email.Subject) }
上記コードでは宛先メールアドレスを条件に受信メールを検索していますが、そのほかにも様々な条件が指定可能です。
(詳細は以下のAPIドキュメントを参照)
終わりに
ということでMailosaurを紹介しました。
メール関連のE2Eテストのお供にいかがでしょうか?
今回は以上です。
SRE室の紹介 & Embedded SRE/Enabling SREとしてのお仕事紹介
本投稿は、さくらインターネットアドベントカレンダー2022の14日目の投稿です。
この記事では2022年7月に発足した「SRE室」という部署について+これまで私が取り組んできたお仕事の一部を紹介します。
はじめに
さくらインターネットへ入職しSRE室で働き始めてからもうすぐ半年となります。
新しい環境に慣れるまで苦労しましたが、ここ数ヶ月はだいぶ落ち着いてきており、最近は毎日の仕事がとても楽しく感じられています。
これまでSRE室としての取り組みをあまり紹介できていませんでしたが、せっかくのアドベントカレンダーという機会なのでここで紹介させていただきます。
SRE室の紹介
SRE室とは
2022年7月に発足したばかりの新しめの部署です。 以下のような企業理念/ミッション/ビジョン/バリューに従い日々の業務へ取り組んでいます。
企業理念とSRE室のミッション/ビジョン/バリュー
まず我々の企業理念は「やりたいこと」を「できる」に変えるです。

この理念の実現のために、SRE室として以下のミッション/ビジョン/バリューを策定しました。
ミッション

我々の提供するサービスやシステム、プラットフォームの信頼性を高めることで、弊社の直接のお客様はもちろん、 その先のエンドユーザー様、ひいては社会そのもののDXを支えていきたいです。
ビジョン

率先してSREのプラクティスを実践し、社内へ広め、サービスやプラットフォームの信頼性を高めることで価値向上をはかりお客様へより高い価値を届けます。
また、その活動は社内に留まらず、社員自らEnabling SREとなることでお客様や社外のサービスの信頼性向上にも携わっていきます。
バリュー

SREが強権を発動して決まりを押し付けるのではなく、一緒に手を動かすことを大事にしています。
SRE室のエンジニアだけがSREs(Site Reliability Engineers)となるのではなく、
Embedded SRE/Enabling SREとして一緒に手を動かすことを通じてSREの取り組みを拡散させていきます。
一緒に動く際もそれぞれが勝手に動くのではなく、密なコミュニケーションにより互いに期待値を明確にしておくことで 合意のない期待を防ぎ、互いに作業を譲ってしまう/お互いに押し付けてしまう、いわゆる「お見合い」状態を防ぎます。
さらにYou build it, you run it(自分で作って自分で運用する)をバリューとして掲げました。
この言葉は有名なのでご存じの方も多いかもしれませんね。
運用のことを考える開発/運用からのフィードバックを受けられる開発をすることで運用性を向上させ、ひいては信頼性を向上させるという狙いです。
担当業務
現在メンバーは5人です。それぞれが異なる領域を担当しています。
例えばボスであるkazeburoさんは運用系の業務として以下のようなものに取り組んでいます。
また、別のメンバーは社内Kubernetes基盤を担当していたりします。 knowledge.sakura.ad.jp
その他にも色々な業務がありますが、この記事ではこれらの中から私の担当業務の1つであるEmbedded SRE/Enabling SREとしての業務を例として紹介します。
Embedded SRE / Enabling SREとしてのお仕事の例
この記事では3つの業務の例を紹介します。
- チームとしての開発/運用体制作り
- 安心して開発/運用するための仕組み作り
- ポストモーテムの導入
Embedded SRE/Enabling SREとしてプロダクトチームと共に手を動かすのですが、その範囲は開発だけに留まらず、 チームビルディング、CI/CD、モニタリング、QAなど多岐にわたります。
また、1つのプロダクトチームに専属ではなく、いくつかのプロダクトチームを兼任するような形となっています。
まずはチームとしての開発/運用体制作りについて紹介します。
チームとしての開発/運用体制作り
これは先月から携わり始めたとあるプロダクト(以下プロダクトAと表記)での取り組みです。
プロダクトAは結構歴史のあるプロダクトで、すでにユーザーも一定数付いており一見順調そうに見えるのですが、いくつかの課題/負債も抱えていました。
- 問い合わせへの対応速度が他チームと比較すると遅く見える
- 障害対応作業でのオペミスによる2次災害が発生していた
- ドキュメントが乏しく、アーキテクチャの全体像が掴みにくい
- アーキテクチャの全体像が掴みにくいせいでソースコードも追いにくい
- テストコードが網羅的ではなく手作業でのテストが大変そう
そこでSRE室として何か手伝いたいと思いプロダクトAチームへジョインすることにしました。
まずチームに入り、雑談会を通じて問題探し
まずはチームメンバーとの雑談会を通じて各メンバーの課題に対する温度感や悩みなどの思いを共有する場を設けました。
その場で以下のような問題も見えてきました。
- リモートワーク化が進んだことや中心的な役割を担っていた担当者の退職などによりコミュニケーションが減った/分断された
- 開発者の担当領域が分かれており、互いに他のメンバーの担当領域についてよく知らないという知識の分断状態となっている
- 開発開始当初と現在とでプロダクトに求められるものが変化し、信頼性や拡張性により高いレベルが求められるようになった(が追いついていない)
なぜ現在のようなアーキテクチャになっているのかといったあたりの背景/仕様についても雑談を通じて少しずつ見えてきました。
最初の一手: コミュニケーション経路の確保/整備
少しずつ問題は見えてきましたが、すでに動いているプロダクトにいきなり大鉈を入れるのはリスクが高く、また限られた人員でうまく回していく必要もありましたので、 まずは小さい改善を繰り返すことでゆっくりと信頼性を高めていく方針としました。
このための最初の一手としてコミュニケーション経路の確保/整備をしました。
- 週に2回の朝会
- 週に1回の定例会
まずはスクラムのデイリースクラムのように同じ場所/同じ時間に朝会というミーティングを開催することにしました。
チームメンバーそれぞれが抱えている仕事やその進捗状況、どのようなことで悩んでいるかを共有する場としています。
また、朝会で扱いきれないような課題については定例会ということで少し長めに時間をとって話す機会を設けました。
たくさんの課題がありますが、毎回どこまで/どれからやるかを参加者全員で話し合い、2〜3テーマをピックアップしてワイガヤする場になっています。
なお、さくらはリモートワークを前提とした働き方を採用していますので朝会/定例会はもちろんオンラインで行います。
次の一手: 「個人からチームへ」活動
チーム内でこまめにコミュニケーションを取る経路が出来たので、さらに一歩進めて各メンバーが個人で進めていた業務をチームで担当できるようにしてみました。 具体的には以下のようなところをチームで対応するようにしました。
- 問い合わせ対応窓口
- 運用作業
従来はSlackなどで個人宛に問い合わせが来ていましたが、専用のSlackグループを作りこちらに問い合わせしてもらうことでチームとして問い合わせ対応を行うようにしました。 作業についてもZoomなどで画面共有しながら行うことでノウハウを共有できる仕組みとしました。
こまめな方向調整: ふりかえりの実施
これらの仕組みを導入してみて数週間経った時点でふりかえりを行い細かな方向調整をしました。
例えば朝会を見直し、担当業務についてはGitHub Projectを使うようにして可視性をあげるように変更しました。
チーム作りはまだまだ続く
まだまだ課題は山積みですがこまめな改善をしつつチームとして進んでいく体制が整いました。
今後のふりかえりで方針転換するかもしれませんが当面はこんな感じで少しずつ進めていくつもりです。
ということでチーム作りへの取り組みを紹介しました。
次はもうちょっと泥臭い開発/運用周りの業務を紹介します。
安心して開発/運用するための仕組み作り
前述のプロダクトとは別のプロダクト(以下プロダクトBと表記)での取り組みについてです。
プロダクトBチームへは私がバックエンドの開発の担当という形でジョインしました。
こちらのチームはある程度チームとして動く体制が整っていましたので、プロダクトの主機能の開発に加え、CI/CD、モニタリングなどの面の改善に取り組みました。
安心して開発/運用するための課題
プロダクトBチームへジョインした当初、作業をする中でいくつかの不安を感じていました。
- コード品質が下がることへの不安
- テスト不足による不具合混入の不安
- リリースなどの運用作業でお客様への影響が発生してしまうことの不安
- アプリケーション内部の動きが見えないことへの不安
これらの不安を解消し、安心して開発/運用できるようにすることはそのまま信頼性向上に繋がると判断しこれらの課題に取り組みました。
取り組み一覧
品質低下の防止
- golangci-lintの導入
- shellcheckの導入
- 単体テストの充実/テスト環境のDockernize
- 日次E2Eテストの導入
プロダクトBはgoとbashを主に利用していましたのでlinterとしてgolangci-lintとshellcheckを導入しました。
また、プロダクトがsystemdに依存しており、手元のマシン(mac/windows)からテストし辛いという問題がありました。
対応として外部環境への依存部分は極力切り離した上で単体テストを充実させると共に、Docker上でも動かせるようにすることでテスト環境構築を容易にしました。
加えてE2Eテストを充実させ、毎日実施することでエンドツーエンドでの問題発生を早期発見できるようにしました。
CI/CD
- DroneによるCI/CDの導入
CI/CDの仕組みも整えました。さくら社内ではDroneやGitHub Actionsが使われていますが、どちらかというとDroneの利用が多そうだったのでそちらに合わせました。
運用面を考慮したソフトウェア改善
- 起動バージョン誤りを防ぐために実行ファイルへコミットハッシュの埋め込み
- デプロイを安全に行うためのGraceful Shutdown実装
- systemdユニットの再起動を安全に行えるようスクリプトを改善
- 依存モジュール更新などの運用をスクリプト化
更新などの運用作業時にお客様へ影響を出さないための仕組みや作業を楽にするための仕組みを作りました。
具体的にはAPIサーバへのGraceful Shutdownの実装などがあります。 デプロイ時はAPIサーバの実行ファイルの更新のためにAPIサーバの再起動が必要なのですが、 APIサーバがリクエスト処理中に再起動をかけてしまうとそのリクエストはエラー扱いとしていたため、再起動時にリクエストを投げていたユーザーには影響が出てしまっていました。 Graceful Shutdownを実装することでお客様への影響なくAPIサーバの再起動ができるようになりました。
監視
- サービスメトリック監視
サービスメトリック監視を導入し、アプリケーション内部の状況の見える化を行いました。
安心して作業できるようになったので次の段階へ
これらの取り組みである程度安心して開発/運用できるようになりました。
次は生産性の改善に取り組みたいです。
Four Keysの計測など、まだまだ手を付けられていない物がたくさんありますので順次進めていきます。
ここまでいろいろな改善をしてきましたが、それでも障害は発生する物です。
次は発生してしまった障害を活かすためのポストモーテムの導入について紹介します。
ポストモーテムの導入
こちらは今取り組んでいる最中です。 将来的には全社的にポストモーテム文化を導入したいところですが、まずはSRE室の身近なところから実施してみてから徐々に広げていくつもりです。
このために以下のような取り組みを行いました。
- ポストモーテムのためのテンプレート整備
- ポストモーテムのレビューの仕組みを整備
ポストモーテムのためのテンプレート整備
テンプレートとしてSRE本の付録Dを利用することにしました。
シンプルで必要十分な項目が網羅されていますので、まずこれで運用してみて必要に応じて項目の増減をする方針です。
ポストモーテムのレビューの仕組みを整備
また、チーム単位でのポストモーテム実施時 or 実施後にチーム外の人からレビューしてもらえるような仕組みにしました。
SRE本でもベストプラクティスとしてポストモーテムをレビューすることが推奨されていますしレビュー大事ですよね。
ポストモーテムのレビューについてはPagerDuty Incident Responseにも項目がありますね。 response.pagerduty.com
ポストモーテム周りの仕組みを整備しましたが、いつ実施するのかの基準やどうやって結果を社内に展開していくかはまだ検討中です。
こちらは文化の浸透まで時間がかかるでしょうから気長に進めてみるつもりです。
終わりに
ということでSRE室や取り組んでいる業務について紹介しました。
この他にもトイルの削減のための自動化やプロアクティブな対応のためのモニタリング基盤の整備など面白い業務がたくさんあります。
これらはまた機会があれば紹介させていただきます。
以上です。
wireproxyでDockerから--cap-addせずにWireGuardに繋ぐ
はじめに
試用期間を無事に乗り越えた
お久しぶりです。今年の7月からさくらインターネットで働き始めておりました。
先月で試用期間が終わり、今月から正式採用となりました。
無事に試用期間を乗り切れて一安心です。
担当業務は?
所属部署はこれまで通りSRE室です。
ボスであるkazeburoさんをはじめ頼もしい同僚たちに囲まれて毎日楽しく仕事しております。
そんな中での私の業務はというと、引き続きUsacloudやTerraformプロバイダーといったOSSの開発をしつつSREとしての業務も担当しています。
Embedded SRE/Enabling SREとして、開発/運用の両者が共通のゴールをもって、運用性に優れたソフトウェアを開発すべくさまざまな取り組みをしています。
今日は最近のSREとしての取り組みの中から、デプロイの自動化にまつわる話を紹介させていただきます。
本題: wireproxyでDockerコンテナ内からWireGuard VPNに繋ぐ
SREとしての取り組みの一環として、これまで手動で行われていたとあるアプリケーションのデプロイ作業を自動化しました。
CI/CDという取り組みは既に一般的に広まっており、私自身これまで何度もデプロイの自動化を行なってきました。
今回対象にしたアプリケーションは比較的小規模で単純なGo製のアプリケーションでしたので、割とすんなりと自動化できるだろうと思っていたのですが少々引っかかる点もありました。
というのも、今回のデプロイ対象サーバへはWireGuard VPNを経由して接続する必要があり、さらにデプロイに用いているDrone上で起動されるDockerコンテナからそれを行う必要があるというのが難点でした。
wireproxyというツールを併用することでこの問題を解決しましたので以下で今回のシステム構成〜使い方まで含めて紹介します。
今回のシステム構成
今回の構成は以下の通りです。
- ソースコード管理: GitHub Enterprise(GHE)
- CI/CD: Drone
- VPN: WireGuard
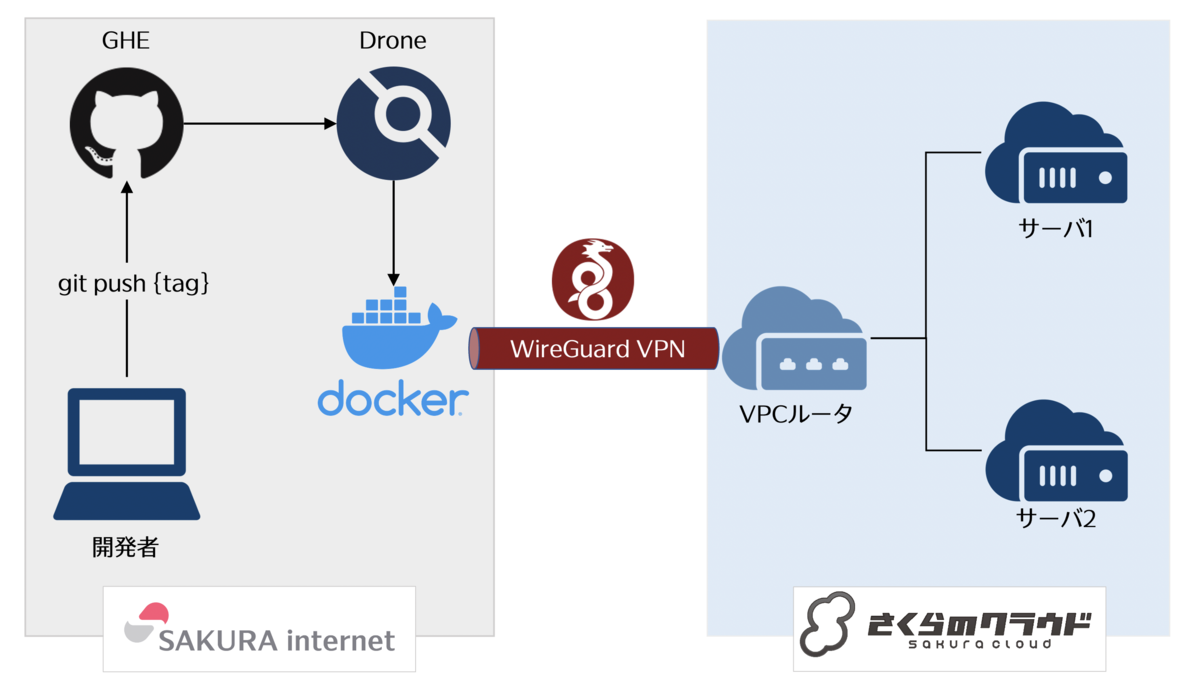
アプリケーションのソースコードは社内ネットワーク上のGHEに置かれており、CI/CDには同じく社内ネットワーク上においたDroneを利用しています。
DroneではDockerパイプラインを利用しています。
今回デプロイ対象のシステムはさくらのクラウドに置いており、VPCルータを用いてVPCを構築、その中にサーバを複数台置くという構成です。
VPCルータのWireGuardサーバ機能でVPNを構築している
今回の構成ではVPNのためにVPCルータのWireGuardサーバ機能を利用しています。 VPCの中のサーバには外部から直接SSH接続出来ないようにしており、VPCルータとWireGuardでVPN接続してからサーバに接続する形となっています。
サーバ上で動かすアプリケーションはWeb APIを提供するもので、クライアントからのアクセス経路は別途確保する必要がありますが、今回のデプロイの話には関係ないので記載を省略しました。
問題: DockerからどうやってWireGuard VPNに繋ぐ?
普通にdocker runするとエラーになる
上記の通り、VPCの中のサーバにSSH接続するにはまずWireGuardでVPN接続する必要があります。
これをDroneのDockerパイプラインからやろうとするとエラーになってしまいます。
以下は手元でエラーを再現してみたものです。
# docker run -it --rm ubuntu:22.04 # 必要なものをインストール $ apt-get update; apt-get install -y iproute2 wireguard # インターフェース作成 $ ip link add dev wg0 type wireguard RTNETLINK answers: Operation not permitted
RTNETLINK answers: Operation not permittedって怒られてしまいますね。
権限が足りない -> --cap-add NET_ADMIN or --privilegedで実行できる
これは権限が足りないからで、docker runする時に--cap-add NET_ADMINを指定することで実行できるようになります。
参考: Docker run リファレンス - Linuxケイパビリティ
--privilegedでも良いですが、不要な権限は与えない方が良いでしょう。
Dockerのドキュメントにも以下のように書かれてます。
ネットワーク・スタックとやりとりするには、 --privileged を使う替わりに、ネットワーク・インターフェースの変更には --cap-add=NET_ADMIN を使うべきでしょう。
DockerはOK、次にDroneではどうすればいい?
Droneも--cap-add相当のことができる設定があればよさそうです。
しかしドキュメントを見る限りどうも--cap-addは出来ないようです。
代わりに--privilegedであれば指定できますが、Drone上で該当リポジトリをTrustedとしてマークする必要があります。
(各リポジトリのSettingsから設定可能です)
これで一応対応出来るとはいえデプロイのためにコンテナへ特権を与えたくないです。
ということで別の方法を探します。
別の方法: wireproxyを使う
この件についてSRE室の朝会(業務内容の共有だったり雑談したりする会)で話題に出したところ、kazeburoさんから「wireproxyというのがあるよ」と教えていただきました。
wireproxyとは
READMEにはwireproxy is a completely userspace application that connects to a wireguard peer, and exposes a socks5 proxyと書かれています。
どう実装されているのでしょうか?
ざっと見たところ以下のものを使ってユーザースペースでの実装を実現しているようです。
- tunデバイス: wireguard-go/tun/netstack -> gVisorのTCP/IPスタックを用いたtunの実装
- WireGuardプロトコルの実装: wireguard-go
wireguard-go/tun/netstackについてはこちらの記事でも触れられていますね。
0x6b.github.io
これなら--cap-add NET_ADMINしなくても大丈夫そうです。
ちなみにSOCKS5プロキシの実装にはこちらが使われています。
- SOCKS5プロキシ: github.com/armon/go-socks5
ということで早速試してみます。
wireproxyを手元から試してみる
WireGuardのクライアント設定ファイルを用意する
wireproxyはWireGuardクライアント設定ファイルを読み込めますので、まずは動くクライアント設定ファイルを用意した上でwireproxyの設定という手順で進めます。 まずWireGuardクライアント設定ファイルを用意し、その設定でWireGuardに繋がることを確認します。
今回は以下のような感じで用意しました。
$ vi wg0.conf [Interface] PrivateKey = xxx Address = 192.168.0.11/32 [Peer] PublicKey = xxx AllowedIPs = 192.168.0.0/24 Endpoint = 192.0.2.1:51820 PersistentKeepalive = 25
これで繋がるかDockerで試してみます。--cap-add NET_ADMINをつけるのを忘れないようにします。
# wg0.confを置いたディレクトリで実行 $ docker run -it --rm --cap-add NET_ADMIN -v $PWD:/etc/wireguard -v ~/.ssh:/root/.ssh ubuntu:latest # 必要なものをインストール $ apt-get update; apt-get install -y iproute2 wireguard openssh-client # WireGuardでVPN接続してみる $ wg-quick up wg0 # 確認: VPC内のサーバへSSHしてみる $ ssh user@192.168.0.x
設定が正しければ繋がるはずです。
WireGuardクライアント設定ファイルを参照するようにwireproxyの設定ファイルを作成
次に先ほど動作確認したWireGuardクライアント設定ファイルを参照するような形でwireproxyの設定ファイルを作成します。
今回のwireproxyの設定ファイルは以下のような構成となります。
# WireGuardのクライアント設定ファイルへのパス WGConfig = /path/to/wg0.conf # 以下でwireproxyの設定 [Socks5] BindAddress = 127.0.0.1:1080
wireproxyにはTCPClientTunnelとTCPServerTunnel、Socks5という設定項目がありますが、今回はSocks5を利用します。
Socks5を利用すると、指定したアドレスでリッスンするSOCKS5プロキシを起動してくれます。
sshコマンドからはProxyCommand='nc -X 5 -x 127.0.0.1:1080 %h %p'のように指定することでSOCKS5プロキシを利用できます。
ということで動作確認してみましょう。今度は--cap-add不要です。
# wg0.confを置いたディレクトリで実行 $ docker run -it --rm -v $PWD:/etc/wireguard -v ~/.ssh:/root/.ssh ubuntu:latest # 必要なものをインストール $ apt-get update; apt-get install -y iproute2 wireguard openssh-client curl netcat # wireproxyをダウンロード&インストール $ curl -LO https://github.com/octeep/wireproxy/releases/download/v1.0.5/wireproxy_linux_amd64.tar.gz $ tar zxvf wireproxy_linux_amd64.tar.gz && rm wireproxy_linux_amd64.tar.gz $ install wireproxy /usr/local/bin # wireproxy用の設定ファイルを作成 $ vi proxy.conf WGConfig = /path/to/wg0.conf [Socks5] BindAddress = 127.0.0.1:1080 # wireproxyをデーモンモードで起動 $ wireproxy -d -c proxy.conf # SSH接続してみる $ ssh -o ProxyCommand='nc -X 5 -x 127.0.0.1:1080 %h %p' user@192.168.0.x
これでうまく動きました。これならDrone上でTrustedにしたりprivileged: trueにしたりしなくても動きそうです。
Droneから使えるようにDockerfile作成
Droneから使いたいのでDockerfileを作っておきます。これをビルドしてレジストリにプッシュしておきます。
$ vi Dockerfile
FROM ubuntu:latest
ENV DEBIAN_FRONTEND noninteractive
RUN apt-get update \
&& apt-get -y install \
iproute2 \
wireguard \
openssh-client \
curl \
netcat \
&& apt-get clean \
&& rm -rf /var/cache/apt/archives/* /var/lib/apt/lists/* \
&& curl -LO https://github.com/octeep/wireproxy/releases/download/v1.0.5/wireproxy_linux_amd64.tar.gz \
&& tar zxvf wireproxy_linux_amd64.tar.gz \
&& rm wireproxy_linux_amd64.tar.gz \
&& install wireproxy /usr/local/bin
ADD deploy.sh /deploy.sh
deploy.shは以下の値を環境変数で受け取る形にしました。
- WG_CONF: WireGuardクライアント設定ファイルの内容
- SSH_USER_NAME: SSH接続時のユーザー名
- SSH_PRIVATE_KEY: SSHための秘密鍵
- TARGET_HOSTS: 対象ホスト(スペース区切り)
今回はscp/sshコマンドをベタ書きしてますが、その辺を書き直せばもう少し汎用的に使えるはずです。
#!/bin/sh set -e if [ -z "$WG_CONF" ]; then echo "\$WG_CONF is required" exit 1 fi if [ -z "$SSH_USER_NAME" ]; then echo "\$SSH_USER_NAME is required" exit 1 fi if [ -z "$SSH_PRIVATE_KEY" ]; then echo "\$SSH_PRIVATE_KEY is required" exit 1 fi if [ -z "$TARGET_HOSTS" ]; then echo "\$TARGET_HOSTS is required" exit 1 fi # 各種ファイルを生成 echo "$WG_CONF" > wg0.conf echo "$SSH_PRIVATE_KEY" > /deploy_key; chmod 0600 /deploy_key cat << EOL > proxy.conf WGConfig = wg0.conf [Socks5] BindAddress = 127.0.0.1:1080 EOL # wireproxy起動 wireproxy -d -c proxy.conf # 接続完了するまで数秒待つ sleep 5 for host in $TARGET_HOSTS; do # scpでファイルを送り込んだり scp -i /deploy_key -o StrictHostKeyChecking=no -o ProxyCommand='nc -X 5 -x 127.0.0.1:1080 %h %p' ./your-application-file ${SSH_USER_NAME}@${host}:/path/to/your/application # sshで何かしたり ssh -i /deploy_key -o StrictHostKeyChecking=no -o ProxyCommand='nc -X 5 -x 127.0.0.1:1080 %h %p' ${SSH_USER_NAME}@${host} : do something done
Droneの設定
最後にDroneでこのDockerイメージを使ってデプロイするように設定します。
$ vi .drone.yml --- kind: pipeline type: docker name: deploy # タグをトリガーとする trigger: ref: - refs/tags/** steps: # ...中略... - name: deploy image: your-image:tags environment: WG_CONF: from_secret: WG_CONF SSH_USER_NAME: from_secret: SSH_USER_NAME SSH_PRIVATE_KEY: from_secret: SSH_PRIVATE_KEY TARGET_HOSTS: from_secret: TARGET_HOSTS
これでGHEにタグをpushするとWireGuard経由でデプロイが行えるようになりました。
終わりに
ということでwireproxyを使ってDockerから--cap-addなしでWireGuard VPNに繋いでデプロイするようにした話を紹介しました。
Drone特有の処理はないのでGitHub Actionsなどからも同様の方法が取れるはずです。
まだまだ改善の余地は多々ありますので今後も継続して改善していきます。
また、今回は紹介しませんでしたがデプロイの自動化の前段階としてE2Eテストの導入といったより安心して作業できる環境づくりなども行いました。
これらの取り組みは機会があれば改めてご紹介させていただきます。
以上です。
参考文献
WireGuardについて
- インターネットVPNの選択肢に WireGuardはいかがですか?: WireGuardの入門記事
- 作って理解するWireGuard: WireGuardの詳細解説
ユーザースペースでのWireGuard実装関連
- Userspace networking mode (for containers): tailscale/tailscaledのUserspace networking mode(SOCKS5プロキシ)
- cloudflare/boringtun: ユーザースペースでのWireGuardプロトコルの実装(Rust)
- Fadis/userspace_wireguard: WireGuardプロトコルのユーザースペース実装(C++)
- soratun を改造して AWS Lambda から簡単に SORACOM Arc を使ってみました: wireproxyと同じくwireguard-goを用いたユーザースペース実装(Go)
その他
![LeanとDevOpsの科学[Accelerate] テクノロジーの戦略的活用が組織変革を加速する impress top gearシリーズ](https://m.media-amazon.com/images/I/51TuqLnPBCL._SL500_.jpg "LeanとDevOpsの科学[Accelerate] テクノロジーの戦略的活用が組織変革を加速する impress top gearシリーズ")

続: さくらのクラウドにTerraformでISUCON過去問の環境を作る
前回: ISUCON12予選環境を作るやつ
前回はISUCON12予選の環境を作りました。
matsuu/cloud-init-isuconには他の過去問もある
環境を作るのに使わせていただいているmatsuu/cloud-init-isuconではISUCON12予選以外の過去問の環境向けのファイルも提供されています。
せっかくなので他の過去問にも対応しました。
対応した環境
matsuu/cloud-init-isuconが対応している環境は一通り対応してみました。
公式
非公式
ISUCON本に載ってるprivate-isuもあります
ISUCON本に載ってるprivate-isuも構築できちゃいます。

今回作成した過去問環境は基本的にサーバ1台で動かすようになっているのですが、 private-isuについてだけはさくらのナレッジに従いapp/benchの2台構成となっています。
ということで
非常に手軽に作成できるようになってますので是非お試しください〜。
以上です。