さくらのクラウド + Kubernetesでマネージドなロードバランサを使う

さくらのクラウドのマネージドなL4ロードバランサーをKubernetesから使えるようにCloud Controller Managerを実装してみました。
Kubernetesでserviceを作成する際にtype: LoadBalancerと指定することで動的にマネージドロードバランサーを作成してくれます。
今回はこの仕組みをどう実現しているか/どう使うのかについてご紹介します。
3/30 追記:
コメントで「ループバックへのVIP設定は不要」とのご指摘をいただきました。
改めて0からクラスタを再構築して試したところ上手くいきましたのでVIP関連の記述を修正しました。
id:masaya_aoyama さんご指摘ありがとうございました!
Kubernetesでtype: LoadBalancerなserviceを作成するには
GKEやAKSではtype: LoadBalancerと指定してserviceを作成することでマネージドなロードバランサーを利用可能となっています。
せっかくさくらのクラウドでKubernetesを使うならやっぱりtype: LoadBalancerでマネージドなロードバランサでserviceを使いたいですよね。
でも単純にKubernetesクラスタをさくらのクラウド上にデプロイしただけではtype: LoadBalancerは利用できません。
というのも、type: LoadBalancerなserviceはKubernetesのCloud Controller Managerというクラウド(等)のプラットフォームとのインテグレーションを担当する部分で
実装されており、各クラウドプラットフォームごとにCloud Controller Managerを実装する必要があるためです。
参考:Kubernetes ドキュメント: Concepts Underlying the Cloud Controller Manager
Cloud Controller Managerの実装としては、Kubernetesのソースツリー配下に以下のプラットフォーム向けの実装があります。(v1.10時点)
- aws
- azure
- cloudstack
- gce
- openstack
- ovirt
- photon
- vsphere
ここにないプラットフォームについては独自に実装することでKubernetesと統合可能となっています。 (実装すべきインターフェースはこちらに定義されています -> kubernetes/pkg/cloudprovider/cloud.go)
既にDigitalOceanやOracle Cloud Infrastructureといったプラットフォームについては実装が公開されていますし、既存の実装を改造することでオンプレミス向けにCloud Controller Managerを実装した事例なども公開されています。
参考(スライド): Kubernetes meetup #7 スライド
参考(記事):Kubernetes をいじって Hardware LoadBalancer で “type LoadBalancer” を実現してみた @Kubernetes meetup #7
Cloud Controller Managerの実装については↑↑の記事が素晴らしいですのでオススメです。
ということで、さくらのクラウドでtype: LoadBalancerなサービスを使うにはCloud Controller Managerが必要ということなので早速実装してみました。
さくらのクラウド向けのCloud Controlelr Managerの実装
全体としては以下のようになります。

順番に解説していきます。
さくらのクラウドで利用できるロードバランサの仕様
まず、今回利用するさくらのクラウドのマネージドなロードバランサの主な仕様を押さえておきます。
主な仕様は以下の通りです。
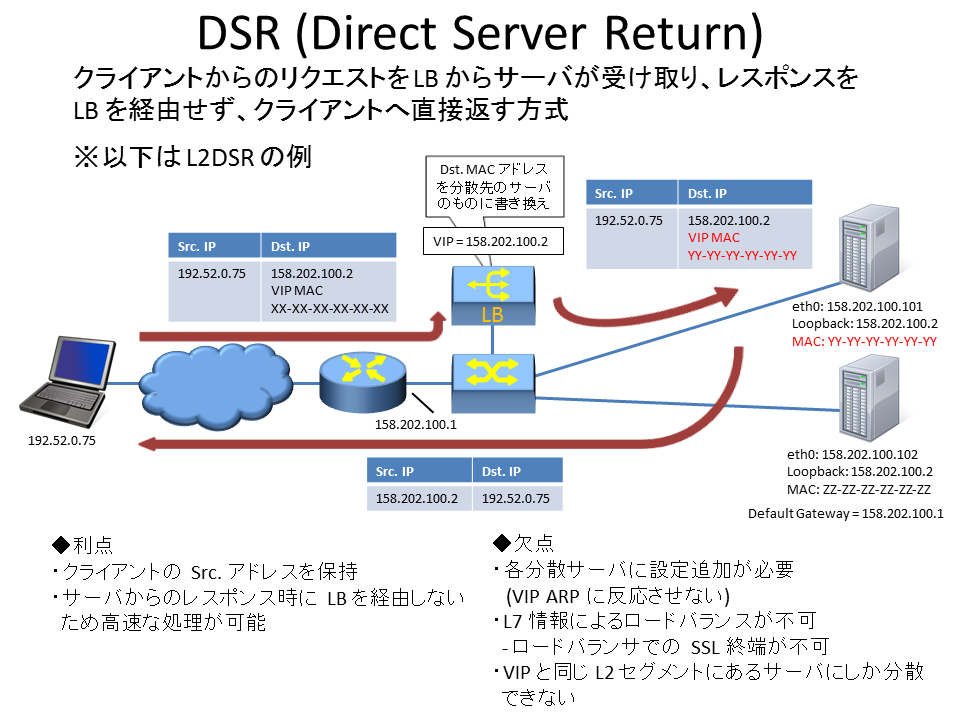
- DSR(Direct Server Return)方式のL4ロードバランサ
ルータ+スイッチまたはスイッチを使用して構築されたネットワーク内にのみ設置可能- VRRPを用いた冗長化に対応
- VIPは最大10個
- 実サーバはVIPあたり最大40台まで
Kubernetesと統合する上で特にポイントとなるのは以下2点です。
ルータ+スイッチまたはスイッチを使用して構築されたネットワーク内にのみ設置可能- DSR方式であること
ルータ+スイッチとは、さくらのクラウドでグローバルIPをブロック単位(/28〜/24)で確保するためのもので、
割り当てられたブロック内のグローバルIPは配下に接続したサーバやロードバランサなどに自由に割り振り可能となっています。
このルータ+スイッチにサーバとロードバランサを接続することでDSRでのロードバランシングを実現しています。
DSR方式自体については以下の資料などを参照ください。

{kind=link}
このDSR方式のロードバランサを使う場合は以下のような設定をサーバに対して行う必要があります。
- VIPに応答するためにループバックにVIPを設定
- VIP宛のARPに応答しない設定
3/30 修正 & 追記:
今回はロードバランサ作成時に動的にVIPを確保する仕組みとなっており、VIP確保時に各Workerノードに対してVIPをループバックに設定する必要があります。この辺りを動的に行うための仕組みも今回実装しています。
ループバックへのVIP設定はservice作成時にkube-proxyによってiptablesに追加されるルールにより処理されるため設定不要です。
Cloud Controller Managerの処理の流れ
今回中心となるのはControl Plane上で稼働するCloud Controller Managerです。
service作成時に以下のような流れでロードバランサの作成やVIP割り当てなどを行ってくれます。
(1) serviceの作成
まずはkubectl exposeなどでtype: LoadBalancerと指定してserviceを作成します。
この時点ではまだロードバランサが作成されておらず、各WorkerノードにVIPが割り当てられていない状態です。

(2) ロードバランサの作成
serviceが作成されるとCloud Controller Managerが動き出します。
まずスイッチ+ルータに割り当てられたグローバルIPブロックから未使用のグローバルIPを探します。
グローバルIPが見つかったらスイッチ+ルータの配下にロードバランサを作成します。

(3) VIPの割り当て & 実サーバの登録
次にロードバランサにserviceが利用するVIPを割り当てます。このVIPがkubectl get svcなどで見えるExternal IPとなります。
VIPを割り当てた後は振り分け先となる実サーバを登録します。現時点での実装だと全Workerノードあてに振り分けるようにしています(オプションで変更可能となる予定です。)
なおVIPはIPアドレス+ポート番号の組み合わせで登録するため、service作成時に複数のポートを公開するように指定されていた場合はポート番号ごとにVIPを登録します。
この時点でVIP宛てのリクエストが各Workerノードに振り分けられるようになりました。
しかしまだ各WorkerノードのループバックにVIPが割り当てられていないため、パケットが到着しても反応できない状態です。

3/30 追記:
serviceが作成されExternal IPが割り当てられると、kube-proxyによりVIP + 指定ポートへのパケットを処理するルールが各ノードのiptablesに追加されます。
このため、ループバックへのVIPの割り当ては不要です。
--- 3/30 修正: ここから不要 ---
VIP-Agentが各WorkerノードにVIPを割り当てる
VIP-Agentが各WorkerノードにVIPを割り当てる次に各WorkerノードにVIPを割り当てます。これはCloud Controller Managerで実装しても良いのですが、今回は別途エージェントを用意しました。
エージェントはVIP-Agentという名前で、Kubernetesオブジェクトの変更を監視するControllerとして実装しています。
画像: https://cdn-ak.f.st-hatena.com/images/fotolife/f/febc_yamamoto/20180329/20180329174211.png
{kind=link}
VIP-Agentは以下ようなyamlを用いて特権モード(privilege=true)かつhostのネットワークを直接利用する形で起動します。
DaemonSetですので各Workerノードで起動し常駐することになります。
apiVersion: extensions/v1beta1 kind: DaemonSet metadata: name: sakura-vip-agent namespace: kube-system spec: template: metadata: labels: name: sakura-vip-agent spec: serviceAccountName: sakura-vip-agent hostNetwork: true containers: - image: sacloud/sakura-vip-agent:0.0.1 name: sakura-vip-agent securityContext: privileged: true volumeMounts: - mountPath: /dev name: dev volumes: - name: dev hostPath: path: /dev
このような形にしておくことでserviceにExternal IPが割り当てられたことを検知し、ホスト側のインターフェースの設定を変更することが可能となります。
今回はserviceのExternal IPにはVIPが割り当てられますので、それをループバックに設定する役割となっています。
これでVIP宛てのリクエストを各workerが処理できるようになりました。
--- 3/30 修正: ここまで不要 ---
ここまでくれば後はkube-proxyがPodまで届けてくれます。
(この辺の詳細はQiita:GKE/Kubernetes でなぜ Pod と通信できるのかが詳しいです)
さくらのクラウド向けCloud Controller Managerの使い方
次に実際の利用方法についてです。さくらのクラウド向けのCloud Controller Managerを利用するには以下の作業が必要です。
- 各workerノードを
スイッチ+ルータ配下に作成 - 各workerノードでVIP宛てのarpに応答しないための設定
- kubeletの起動パラメータとして
--cloud-provider=externalを指定 Cloud Controller Managerのデプロイ(今回はhelmを利用)
各workerノードをスイッチ+ルータ配下に作成
Kubernetesクラスタ構築の際にworkerノードをスイッチ+ルータ配下に配置します。
注意点としては、各ノードのホスト名をクラスタ内で一意にすることと、ホスト名とさくらのクラウド上のサーバ名を同じにしておくことがあります。
これはCloud Controller Managerがworkerノードを検知するのに各ノードのホスト名を元にさくらのクラウドAPIで各サーバを探しに行くようにしているからです。
各workerノードでVIP宛てのarpに応答しないための設定
次にVIP宛てのarpに応答しないようにカーネルパラメータを設定します。
CentOSの場合だと以下のように指定します。
# /etc/sysctl.confに以下2行を追記
net.ipv4.conf.all.arp_ignore = 1
net.ipv4.conf.all.arp_announce = 2
# 追記した内容を反映
$ sysctl -p
kubeletの起動パラメータとして--cloud-provider=externalを指定
次にkubeletの起動パラメータを追加します。Kubernetes本体のソースツリー配下にないCloud Controller Managerを利用する場合は--cloud-provider=externalというパラメータを指定する必要があります。
Kubernetesクラスタのセットアップ方法によって設定方法は異なります。
例えばkubeadmの場合は各ノードの/etc/systemd/system/kubelet.service.d/10-kubeadm.confにEnvironment="KUBELET_EXTRA_ARGS=--cloud-provider=externalを追記します。
(追記後にkubeletの再起動などで反映するのをお忘れなく!)
Cloud Controller Managerのデプロイ
最後にCloud Controller Managerをデプロイします。(3/30 修正: VIPの記述を除去)
デプロイは手動でyamlを投入しても良いですが、簡単にデプロイできるようにHelm Chartを用意しています。
まず、Cloud Controller ManagerはさくらのクラウドAPIを利用するためAPIキーの設定が必要になります。
helmでのインストール時にAPIキーを指定してください。
# helm initを実行(まだしていない場合のみ)
$ helm init
# helmにsacloudリポジトリを追加
$ helm repo add sacloud https://sacloud.github.io/helm-charts/
# デプロイ実行
$ helm install sacloud/sakura-cloud-controller-manager --name sakura-ccm \
--set sacloud.accessToken=<APIトークン> \
--set sacloud.accessTokenSecret=<APIシークレット> \
--set sacloud.zone=<ゾーン(is1a/is1b/tk1a)>
3/30 修正: VIP-Agentの記述を除去
後は少し待てばCloud Controller Managerとが起動するはずです。VIP-Agent
(kube-systemネームスペースにデプロイされますので、確認はkubectl get all -n kube-systemのようにしてください)
これで準備が整いました。 次に実際にserviceを作成してみます。
Podを作成しtype: LoadBalancerなserviceを作成してみる
まずはserviceでexposeするコンテナを作成します。今回は例としてload-balancer-exampleという名前でnginxを起動してみます。
kubectl run load-balancer-example --replicas=2 --labels="run=load-balancer-example" --image=nginx:latest --port=80
これでload-balancer-exampleという名前のDeploymentが作成され、ReplicaSet/Podも作成されます。
次に作成されたDeploymentをexposeしてserviceを作成します。その際にtype: LoadBalancerの指定をしておきます。
kubectl expose deployment load-balancer-example --type=LoadBalancer --name=load-balancer-example
service作成直後はExternal IPが<pending>となります。
$ kubectl get svc load-balancer-example
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
load-balancer-example LoadBalancer 10.107.97.231 <pending> 80:30900/TCP 1m
External IPが割り当てられるまでしばらく待ちます。割り当てられると以下のような表示となるはずです。
$ kubectl get svc load-balancer-example
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
load-balancer-example LoadBalancer 10.107.97.231 nnn.nnn.nnn.nnn 80:30900/TCP 3m
後はブラウザなどでExternal IP宛てにアクセスすると表示されるはずです。
後片付け
serviceを削除するとロードバランサも削除されます。(3/30 修正: VIPの記述を削除)
以下のコマンドでserviceとdeploymentを削除しておきましょう。
$ kubectl delete svc load-balancer-example
$ kubectl delete deploy load-balancer-example
終わりに
ということでさくらのクラウド+Kubernetesでもtype: LoadBalancerなserviceが使えるようになりました。
今回実装したCloud Controller Managerはまだ実験段階ですが、これからドッグフーディングということで実環境で使いつつブラッシュアップしていきたいと考えています。
さくらのクラウドでKubernetesを利用する際はぜひCloud Controller Managerをお試しください〜!!
以上です。
etcdからkubernetesの動きを見る「kube-ectd-helper」

多分すごく限られた層にだけ響くツール「kube-etcd-helper」を作りました。
kube-etcd-helperは、kube-apiserverが利用しているetcdに直接アクセスし、
データのダンプや変更の検知を行うためのツールです。
kubernetesの全体のデータの動きを知りたい方や、kubernetesを開発プラットフォームとして利用するインフラエンジニアの方などは便利にお使いいただけると思います。
Kubernetesオブジェクトの中身を見るには
Kubernetesオブジェクトとは、Kubernetesのクラスタの状態を表す永続化されるエンティティのことです。
podとかserviceとかdeploymentなどですね。
これらは通常kube-apiserverによって公開されるAPIを通じて操作します。
kube-apiserverの背後ではetcdが動いており、エンティティの永続化に使われています。
手っ取り早くKubernetesオブジェクトの中身を確認するにはkubectl getコマンドを利用するのが楽です。
例えばpodオブジェクトの中身を見るには以下のようなコマンドを実行します。
$ kubectl get pod <pod名>
NAME READY STATUS RESTARTS AGE
hello-world-55c844bc5b-544h6 1/1 Running 0 3d
より詳細に見るには-o yamlや-o jsonといったオプションをつければOKです。
よく使うコマンドですので馴染みのある方も多いですよね。
さらに、--watchというオプションをつけることで、指定オブジェクトの変更を追い続けることも可能です。
# --watchオプションをつけると、オブジェクトの変更を検知できる
$ kubectl get pod <pod名> --watch
NAME READY STATUS RESTARTS AGE
hello-world-55c844bc5b-544h6 1/1 Running 0 3d
また、kube-apiserverが提供するREST APIを直接利用する方法でもオブジェクトの内容を確認できます。
# kubectl proxyを併用する場合
$ kube proxy --port=8080 &
$ curl http://localhost:8080/api/v1/namespaces/<ネームスペース>/pods/<pod名>
{
"kind": "Pod",
"apiVersion": "v1",
"metadata": {
"name": "<pod名>",
# 以下略
}
}
これらの方法以外にも、etcdctlなどのetcdクライアントツールで直接データの中身を覗く方法も取れそうなのですがこの方法には問題があります。
というのも、kubernetes 1.6以降はetcd v3がデフォルトとなりバイナリーフォーマット(protobuf)でシリアライズされたデータが格納されているため、
コマンドラインから覗いても(一部を除き)読めないデータとなっているからです。
ということで多くのケースではkubectlまたはREST APIを利用することになると思います。
問題となるケース
通常はkubectlまたはREST APIを利用すれば事足りると思いますが、いくつか面倒なケースというのもあります。
kubectl runなどの複数のオブジェクトにまたがる操作を追いたい場合- オブジェクトの変更履歴を比較し、どこが変わったのか確認したい場合
例えばkubectl runを実行すると、Deployment/ReplicaSet/Podが作成されます。
これらの動きを追いたい場合--watchオプションを利用することになるのですが、
現在はkubectl get allに対しての--watchオプションは残念ながらサポートされていないためそれぞれに対し個別にkubectl get --watchしないといけません。
また、--watchで変更履歴を追えますが、変更されるごとに個別のファイルに出力といったことはできないためどこが変わったのか比較するのがなかなかに面倒な作業です。
これらの問題を解決するためにkube-etcd-helperを作りました。
kube-etcd-helperは何をするの?
kube-etcd-helperは、kube-apiserverが利用しているetcdに直接アクセスしデータのダンプや変更の検知を行うためのツールです。
前述の通りkubectlやREST APIからではネームスペース/オブジェクトを跨いだ全オブジェクトを追うのはなかなか手間ですが、kube-etcd-helperを利用すれば簡単にできちゃいます。
kube-etcd-helperのインストール
kube-etcd-helperはGoで書いているため、インストールは実行ファイルをダウンロードして実行権を付与するだけでOKです。
以下のGitHubリリースページからダウンロードしてください。
あとはetcdに接続できる環境で実行するだけです。
master上で直接kube-etcd-helperを実行できる場合は問題ないですが、Docker for Macなどの直接etcdと通信できない環境の場合は
事前に以下のようにポートフォワードしておきます。
kubectl port-forward etcd-docker-for-desktop 2379:2379 --namespace=kube-system
なおデフォルトではlocalhost:2379に対して通信しようとしますがオプションで変更も可能です。
同じく証明書の指定などもオプション指定可能です。
kube-etcd-helperの使い方
ダンプ
etcd内でのキー階層をそのままディレクトリ/ファイルにダンプが可能です。
# etcdのデータをoutディレクトリにダンプ
$ kube-etcd-helper dump -o out/ --pretty

変更の追跡(watch)
kubectlの--watchオプションと同じく、変更を検知するためのwatchサブコマンドを用意しています。
これを利用すれば、全ネームスペースの全オブジェクトの動きを追うことが可能です。
# etcdのデータの変更を検知して標準出力に書き出し
$ kube-etcd-helper watch --pretty
watchサブコマンドはディレクトリ/ファイルへの出力に対応しているため、diffコマンドなどを併用することでどこが変わったのかを追うことも容易です。
# ディレクトリ/ファイルへの出力
$ kube-etcd-helper watch -o out/ --pretty

この例はkubectl runでhello-worldというdeploymentを作成した時の動きをwatchサブコマンドで記録したところです。
deployment/replicaset/podそれぞれの配下にJSON形式で変更内容を保存しています。
diffコマンドなどを併用するとオブジェクトのどの値が変更されたのか確認できます。

この図はPodの作成〜schedulerがスケジューリングする部分ですね。Podのステータスがどう変わったのか一目瞭然です。
また、ファイル名はetcdのリビジョン番号を利用していますので、ファイル名順に並べればkubernetesがどの順番でetcdに対して操作を行なっているのか追うことも可能ですね。
その他のコマンド
その他にはlistとgetサブコマンドがあります。
listはetcdのキーのみを一覧表示します。getは指定キーの内容を表示してくれます。
他にもいくつかオプションがありますので、詳細は--helpを参照してください。
終わりに
ということでkube-etcd-helperの紹介でした。
カスタムのコントローラーを書く方やkubernetesの内部構造をもっと知りたいという方には便利だと思いますのでぜひご利用ください!!
以上です。
Terraform公式のモジュールレジストリ「Terraform Registry」でモジュールを公開する方法

TerraformにはTerraform Registryという公式のモジュールレジストリが用意されています。 今日はTerraform Registryでモジュールを公開する方法について紹介します。
Terraform Registryでモジュールを公開するまで
Terraform RegistryはGitHubのパブリックなリポジトリに一定のルールに従ったTerraformモジュールを置けば公開できるようになっています。
モジュール公開までの手順
手順としては以下の通りです。
リポジトリ/モジュール作成時のルール
リポジトリ/モジュール作成の際は以下のルールに従う必要があります。
- GitHubのパブリックなリポジトリでモジュールのソースを公開する
- リポジトリ名は
terraform-<PROVIDER>-<NAME>という形式にする - モジュールのファイル構成はStandard module structureに従う
0.0.0またはv0.0.0のようなセマンティックバージョンに従った名前のタグをつける
順番に見ていきましょう。
モジュール用のGitHubリポジトリ作成
まずGitHubでパブリックなリポジトリを作成しましょう。
リポジトリ名はterraform-<PROVIDER>-<NAME>という形式にする必要があります。
例えばAWS向けにconsulクラスタをセットアップするようなモジュールであればterraform-aws-consulという名前にします。
<PROVIDER>の部分はモジュールが操作する対象のプロバイダーの名前を指定します。
複数のプロバイダーを利用することもあると思いますが、その場合はメインとなるプロバイダーの名前を指定すればOKです。
<NAME>の部分はモジュールの名前を指定します。
ハイフンを含む名前も指定できます。
モジュールの作成
リポジトリを作成したらモジュールの作成を行います。
ファイル構成はStandard module structureに従う必要があります。
Standard module structureって?
モジュール作成の際のファイル構成の作法です。
- [必須]ルートモジュールであること
- READMEファイルを持つこと
- ライセンスファイルを持つこと
main.tf/variables.tf/outputs.tfを持つこと- 変数(Input Variables)とアウトプット(Output)はそれぞれ説明(Description)を指定すること
- ネストしたモジュールがある場合は
modulesディレクトリ配下に置くこと - 利用例は
examplesディレクトリ配下に置くこと
ルートモジュールとは、モジュールのルートディレクトリ直下にtfファイルの存在するモジュールのとこです。
大抵のモジュールは問題なくルートモジュールと言えるでしょう。
READMEファイルはREADMEまたはREADME.mdというファイル名である必要があります。
ライセンスは任意のライセンスが利用できるようですが、Apacheライセンス 2.0が多い印象です。
ファイル配置としてはmain.tf/variables.tf/outputs.tfを少なくとも作成します。
もちろんこれ以外の任意の名前のtfファイルやテンプレートなどを含んで構いません。
ただし、ネストしたモジュールを含む場合はmodulesディレクトリに配置します。
READMEファイル作成時の注意点
Terraform Registryで公開する際はもちろんレジストリのURLで公開されます。
このため、READMEに画像ファイルやリンクを含める場合は絶対パスとしなければなりません。
モジュールにタグをつける
モジュールを作成したらセマンティックバージョンに従った名前のタグをつけます。
0.0.0または頭にvをつけたv0.0.0形式とします。
忘れずにGitHubにpushしておきましょう。
# タグの作成 $ git tag v0.0.1 # GitHubにpush $ git push origin v0.0.1
モジュールの公開
後はTerraform Registryで公開作業をするだけです。
公式ドキュメントに動画がありますのでこちらを参照してください。
ほぼ迷うことはないと思いますが、個人リポジトリではなくオーガニゼーション配下のリポジトリを指定したい場合はOAuth時に忘れずにGrantしておいてください。

引用元: https://www.terraform.io/docs/registry/modules/publish.html
以上でモジュールが公開できました。
公開されたモジュールを利用する
公開されたモジュールは<GitHubのアカウント or オーガニゼーション>/<モジュール名>/<プロバイダー名>という形式で利用することになります。
例えば、以下の場合だとfoo/bar/awsということになります。
- GitHubのアカウントは
foo - モジュール名は
bar - プロバイダーは
aws
tfファイルにはこんな感じで記載します。
module "your_module_name" { source = "foo/bar/aws" version = "0.0.1" }
後は通常のTerraformを利用する流れと同じでterraform initを実行後にplanやapplyを実行するだけです。
おわりに
Terraformモジュールを作ったことがある方であれば非常に簡単に公開できますね!
ちなみに、Terraform Enterpriseを利用すればプライベートなレジストリも利用できるとのことです。
興味がある方はHashiCorp Japanに問い合わせしてみると良さそうです。
ということでガンガンモジュール作成しましょうー!
以上です。
【さくらのクラウド】Kubernetesクラスタ構築用のモジュールをTerraform Registryに公開しました

はじめに
先日 Open Service Broker for さくらのクラウドというプロダクトを公開しました。
参考: Open Service Broker for さくらのクラウドでKubernetes + Service Catalog出来るようになりました
これを試すには以下2つの方法があります。
Docker for Mac/Windowsの方は気軽に試せますが、やはりちゃんと複数台のサーバで構成されたKubernetesクラスタで動かしたいですよね。
でもVPC内に手動でクラスタを構築するのはなかなか大変な作業です。
そこで、Terraform(とTerraform for さくらのクラウド)でコマンド一発で構築できるようにしました。
Terraformの公式モジュールレジストリであるTerraform Registryに公開していますので非常に簡単に利用することができます。
Terraform Registry: sacloud/kubernetes-single-master/sakuracloud

今回はこのモジュールの使い方について紹介します。
Terraform RegistryのモジュールでKubernetesクラスタを構築する
準備
terraformとterraform for さくらのクラウドのインストールを行っておきます。
以下のドキュメントを参考にインストールし、APIキーの取得/設定などを行っておいてください。
構築
まずは以下のようなtfファイルを用意します。
module "kubernetes" { source = "sacloud/kubernetes-single-master/sakuracloud" // サーバーのrootユーザーのパスワード password = "<put-your-password-here>" // ワーカーノードの数(0でもOK、0だとマスター上でPodが稼働する) worker_count = 3 }
あとは通常のTerraformの流れでterraform initしてterraform applyすればOKです。
簡単ですよね?
あとは構築完了まで数分待ちましょう。
Kubernetesクラスタを使ってみる!
無事構築できましたでしょうか?
構築できたら早速使ってみましょう。
以下2通りの利用方法があります。
- SSHでマスターノードに接続して利用
- マスターノードから
kubeconfigファイルをダウンロードして利用
順に説明します。
マスターノードにSSH接続
terraform applyを実行したディレクトリにcertsディレクトリが作成されています。
この中にサーバへのSSH接続用の秘密鍵が格納されています。
これを利用すればマスターノードだけでなく、ワーカーノードへもSSH接続が行えます。
さくらのクラウド CLI Usacloudを利用する場合は以下のようにすればSSH接続できます。
# サーバ名 kubernetes-master-01を指定してSSH接続 $ usacloud server ssh -i certs/id_rsa kubernetes-master-01
デフォルトではマスターノードの名前はkubernetes-master-01となっているはずです。
変更している場合はコマンドを適宜読み替えてください。
あとはkubectlコマンドやhelmコマンドが利用できるようになっています。
# クラスタの情報を表示 $ kubectl cluster-info # ノードの状態を表示 $ kubectl get node
Type: LoadBalancerなServiceは動かせませんがIngressなどはちゃんと動きます。
kubeconfigファイルをダウンロードして利用
SSH接続せずともkubeconfigファイルをマスターノードからダウンロードすることでローカルマシン上のkubectlコマンドから操作できるようになります。
kubeconfigファイルはマスターノードの/etc/kubernetes/admin.confに置かれていますのでSCPなどでダウンロードします。
Usacloudの場合は以下のコマンドでダウンロード可能です。
# SCPでダウンロード $ usacloud server scp -i certs/id_rsa kubernetes-master-01:/etc/kubernetes/admin.conf ./admin.conf
ダウンロード後は--kubeconfigオプションで都度指定 or KUBECONFIG環境変数を設定するなどで利用します。
# コマンドラインオプションで都度指定する場合 $ kubectl --kubeconfig admin.conf cluster-info # 環境変数で指定することも可能 $ export KUBECONFIG=$(pwd)/admin.conf $ kubectl cluster-info
注意点
このモジュールはシングルマスタ構成で、耐障害性などは考慮していません。
開発/検証用途など向けとなっています。 必要であれば自分でetcdのバックアップなどを行ってください。
終わりに
ということで非常に簡単に使えますのでぜひご利用ください!!
Open Service Broker for さくらのクラウドでKubernetes + Service Catalog出来るようになりました
Open Service Broker for さくらのクラウド

Cloud Foundryやkubernetes-incubatorのservice catalogでおなじみ?のOpen Service Broker APIをさくらのクラウド向けに実装しましたのでご紹介させていただきます。
Open Service Broker APIってなに?
Open Service Broker APIとは、Cloud Foundry由来のService Brokerの仕組みをkubernetesなどのCloud Foundry以外の環境でも利用できるようにHTTP APIの仕様を定めたものです。
その前にService Brokerってなに?
Service Broker(サービスブローカー)とは、プラットフォーム(Cloud FoundryやKubernetes)が外部のサービスやコンポーネントを使いやすくするための仕組み、、、です。
と言われてもこれではよくわかりませんね、、、ということで具体的な例を見ながらService Brokerとは何かを追っていきます。
例えばkubernetesでデータベースを使うには?
DockerやKubernetesなどを利用する場合、データベースやKVS、ストレージなどのステートフルなリソースの扱いは悩みどころです。
Kubernetesではこのようなステートフルな運用のためにStateful Setsというものが用意されていますが、通常のステートレスなコンテナと比べると若干デプロイや運用が面倒です。

ということで、無理にKubernetes内で動かさずにRDSなどの外部のサービスの利用をすることも多いかと思います。
RDSなどの外部のサービスを利用する場合
データベースをk8s内で運用せず外部のサービスを利用する場合、概ね以下のような作業が必要となります。
- 利用するサービスの有効化(プロビジョニング)
- 払い出されたログイン情報などをKubernetes上のSecretsなどに登録
- ログイン情報を環境変数などでPodに渡す
この辺の作業はスクリプトなどである程度自動化することも可能ですが、利用するサービスごとに手順が異なったりしてなかなか大変です。

サービスごとに手順手順が異なるといった煩雑さに対し、統一したインターフェースを提供し手軽に扱えるようにすることがService Brokerの役割(のひとつ)です。
次にService Brokerがこれらの問題をどう解決するのか見ていきます。
Service Broker = 外部のサービスなどを仲介してくれる仲買人
イメージとしてはこんな感じです。

利用者と外部サービスとの間にブローカー(仲買人)が入ることで、利用者はブローカーにお願いするだけで済みます。
ブローカーも役割分担することで実装が簡単に
さらに、ブローカーは利用者からの依頼を管理する部分と実際のサービスの調達を行う部分に役割分担されています。

役割分担することで、サービスが増えても追加となったサービスの分だけを実装すればよく、多様なサービスに柔軟に対応できるようになります。

ここでもう一度: Open Service Broker APIとは?
そして、利用者からの依頼を管理する部分と実際のサービスの調達を行う部分についてのインターフェースを仕様として定めたものがOpen Service Broker APIです。

元々はCloud Foundryから始まった仕組みらしいのですが、Service Brokerが非常に便利な仕組みだったために
Kubernetesなど他のプラットフォームでも利用できるようにCF依存でないオープンな仕様としてOpen Service Broker APIが策定されたようです。
(Cloud Foundry周りにあまり詳しくないのでこの辺は後述の参考サイトなどを参照ください…)
Open Service Broker APIの策定はCloud Foundry Foundation (CFF)によってホストされており、現在のAPIバージョンは2.13となっています。
このCFFにはFujitsu, Google, IBM, Pivotal, RedHat, SAPといったメンバーが参加しているとのことです。
ここには載っていませんが、Microsoft(Azure)についてもOpen Service Broker for Azure(OSBA)が活発に開発されています。
KubernetesとOpen Service Broker APIの関係は?
KubernetesにおいてもOpen Service Broker APIを利用するための仕組みが開発されています。
それがkubernetes-incubatorのService Catalogというものです。
Service Catalogは先ほどの図で言うと、利用者からの依頼を受け付ける仲介者の役割を担っています。

具体的にはService CatalogはKubernetesのカスタムリソースとしてServiceInstanceとServiceBindingを追加し、それらを管理するコントローラー+APIサーバを提供してくれます。
つまり、Kubernetes利用者からは以下のようにkubectlコマンドでリソースを追加することで、外部のサービスを利用できるようになります。
# こんな感じのyamlを用意(この例ではAzure上のMySQLを利用)
$ cat example_service.yaml
apiVersion: servicecatalog.k8s.io/v1beta1
kind: ServiceInstance
metadata:
name: example-mysql-instance
namespace: default
spec:
clusterServiceClassExternalName: azure-mysql
clusterServicePlanExternalName: basic50
parameters:
location: eastus
resourceGroup: demo
firewallRules:
- startIPAddress: "0.0.0.0"
endIPAddress: "255.255.255.255"
name: "AllowAll"
# kubectlで投入
$ kubectl create -f example_service.yaml
これでAzure上のMySQL(Azure Database for MySQL)のインスタンスが作成されます。
このMySQLを各Podなどから利用できるようにするためのクレデンシャルの発行を以下のように行うことができます。
(なお、このインスタンス作成のことをProvisioning、クレデンシャルの発行(仕様上は以外も出来ますが)をBindingと呼びます)
# Azure Database for MySQLへのアクセス用クレデンシャル発行 & Kubernetesのsecretに格納
$ cat example_binding.yaml
apiVersion: servicecatalog.k8s.io/v1beta1
kind: ServiceBinding
metadata:
name: example-mysql-binding
namespace: default
spec:
instanceRef:
name: example-mysql-instance # 先ほど作成したインスタンスを指定
secretName: example-mysql-secret # クレデンシャルの格納先となるsecret名を指定
# こちらもkubectl経由で投入
$ kubectl create -f example_binding.yaml
各PodではSecretを参照することでデータベースのホスト名/データベース名/ユーザー名/パスワードなどを知ることができます。
kubernetes上で完結できるので、例えばHelm chartとしてきちんと永続化したいデータを持つアプリなどの配布を行う際に非常に便利に使えます。
本題: Open Service Broker for さくらのクラウド
そして今回実装したのがService Catalogから依頼を受けて実際にサービスを調達する部分です。
これを利用することでkubernetesからさくらのクラウド上のマネージドなサービスを利用することが容易になります。

先ほどのAzureの例のように、kubectlコマンドからさくらのクラウド上のマネージドDBであるデータベースアプライアンスを作成できます。
ということで早速使い方を紹介します。
Open Service Broker for さくらのクラウドの使い方
準備
まずはさくらのクラウド上のVPC内にKubernetesクラスタを構築する必要があります。

なぜVPC内にKubernetesクラスタが必要かと言うと、さくらのクラウドのデータベースアプライアンスがVPC内(正確にはスイッチさえ繋げばOK)に置く必要があるためです。
Kubernetes(内のPod)から繋ぎたいため、必然的にVPC内にクラスタを置く必要があります。
クラスタを持っていない方はDocker for WindowsまたはDocker for MacでもOKです。
その場合、L2TP/IPSecなどでVPCルータに対してVPN接続を行っておきましょう。

インストール
Helmのインストール
まずはKubernetesのパッケージ管理ツールであるHelmをインストールします。
macOSの場合はhomebrew、Windowsの場合はChocolateyでインストール可能です
# macの例 $ brew install kubernetes-helm
インストールしたらhelm initを実行しておきます。
$ helm init
Service Catalogのインストール
続いてHelmでService Catalogのインストールを行います。
# HelmにService Catalog用のリポジトリを追加 $ helm repo add svc-cat https://svc-catalog-charts.storage.googleapis.com $ Service Catalogのインストール(ネームスペースは"catalog"としておく) helm install svc-cat/catalog --name catalog --namespace catalog
(オプション) Service Catalog CLIのインストール
必須ではないですが、Service Catalog専用のCLI(svcat)をインストールしておくと詳細な情報が参照できて便利です。
CLIを試してみたい方はドキュメントを参考にインストールしてみてください。
Open Service Broker for さくらのクラウドのインストール
続いてHelmでOpen Service Broker for さくらのクラウドのインストールを行います。
さくらのクラウドのAPIキーが必要となりますので、発行していない方はコントロールパネルなどから発行しておいてください。
APIキーは以下のように環境変数に設定しておきます(インストール時の入力を楽にするためです)。
$ export SAKURACLOUD_ACCESS_TOKEN=<your-api-token> $ export SAKURACLOUD_ACCESS_TOKEN_SECRET=<your-api-secret> $ export SAKURACLOUD_ZONE=<your-zone>
続いてHelmでインストールを行います。
# HelmにOpen Service Broker for さくらのクラウド用のリポジトリを追加 $ helm repo add sacloud https://sacloud.github.io/helm-charts/ # Open Service Broker for さくらのクラウドのインストール(ネームスペースは"osbs"としておく) $ helm install sacloud/open-service-broker-sacloud --name osbs --namespace osbs \ --set sacloud.accessToken=$SAKURACLOUD_ACCESS_TOKEN \ --set sacloud.accessTokenSecret=$SAKURACLOUD_ACCESS_TOKEN_SECRET \ --set sacloud.zone=$SAKURACLOUD_ZONE
インストール後はkubectl get pod --namespace=osbsを実行して動いているか確認しましょう。
# STATUSがRUNNING、かつREADYが1/1になっていることを確認しておく $ kubectl get pod --namespace=osbs NAME READY STATUS RESTARTS AGE osbs-open-service-broker-sacloud-xxxxxxxx-xxxxx 1/1 Running 0 7h
kubectlコマンドでデータベースアプライアンスを作成してみる
それでは早速データベースアプライアンスを作成してみましょう。
現時点では以下2種類をサポートしています。
- MariaDB 10.2
- PostgreSQL 9.6
今回は例としてMariaDBを作成してみます。
まず以下のようなyamlファイルを用意します。
apiVersion: servicecatalog.k8s.io/v1beta1 kind: ServiceInstance metadata: name: my-mariadb-instance namespace: default spec: clusterServiceClassExternalName: sacloud-mariadb clusterServicePlanExternalName: db-10g parameters: switchID: <VPC内のスイッチのID> ipaddress: "<データベースに割り当てるIPアドレス>" maskLen: <データベースのネットワークマスク長> defaultRoute: "<データベースのデフォルトルートIPアドレス>"
さくらのクラウド上のスイッチのIDとデータベースに割り当てるIPアドレス関連の記入が必要です。
記入したらkubectlコマンドを実行します。
kubectl create -f <作成したyamlファイル>
うまくいきましたね?
しばらく待つとさくらのクラウド上に新しいデータベースアプライアンスが作成されているはずです。
数分かかりますので気長に待ちましょう。
svcatコマンドをインストールしている場合は以下のコマンドで作成状況を確認できます。
$ svcat get instances
作成したデータベース上にアカウントを作成してみる
次に、Podなどから利用できるようにデータベース上に新たなアカウントを発行し、Kubernetesのsecretにクレデンシャルを登録します。
こちらも先ほどと同じくyamlファイルを作成してkubectlコマンドを実行することで行えます。
apiVersion: servicecatalog.k8s.io/v1beta1 kind: ServiceBinding metadata: name: my-mariadb-binding namespace: default spec: instanceRef: name: my-mariadb-instance secretName: my-mariadb-secret
$ kubectl create -f <作成したyamlファイル>
kubectlを実行すると、my-mariadb-secretという名前でデータベースへのログイン情報(クレデンシャル)が登録されているはずです。
# secretに登録されたクレデンシャルの確認 $ kubectl get secret my-mariadb-secret
なおsecretはBASE64エンコードされていますので、復号して生データを見たい場合は以下のコマンドを実行しましょう。
$ echo <BASE64エンコードされた文字列> | base64 -D
あとは各Podからsecretの値を参照すればOKです。マネージドなデータベースがこれだけで使えるようになるのは便利ですよね!!!
応用: 作成したデータベースを利用する例
応用例としてService Broker for さくらのクラウドを利用するhelm chartを作成してみました。
イケてるデータ可視化ツールであるMetabaseをインストールする例となっています。
Metabaseのバックエンドとしてさくらのクラウドのデータベースアプライアンスを利用、データベースアプライアンスはOpen Service Broker for さくらのクラウドが管理します。
# 応用例のインストール
$ helm install --name my-release sacloud/metabase \
--set database.switchID=<your-switch-id> \
--set database.ipaddress=<your-db-ip> \
--set database.maskLen=<your-db-network-mask-len> \
--set database.defaultRoute=<your-db-default-route-ip>
詳細はChartの内容をみていただければと思いますが、ちゃんと永続化したいデータを伴う構成でもHelmで手軽に配布できるようになっています。
終わりに
ということで今回はOpen Service Broker for さくらのクラウドについて紹介しました。
Open Service Broker/Service Catalogは非常に便利ですのでぜひ使ってみてください!!
以上です。
参考記事
この記事を書くのに以下の記事/スライドを大いに参考にさせていただきました。
Service Brokerの仕組みについてはこちらの資料を読むのがおすすめです。
Arukasで任意のコマンドを実行する「Rarukas」 - 雲の向こうの使い捨てコンテナ

2018/2/20にArukasのβサービスが再開しましたね!!待ってました!!!
ということで早速使ってみました。
何が変わったの?
GitHubアカウントでのサインイン/サインアップは廃止
先ほどのお知らせにも書かれていましたが、GitHubアカウントでのサインアップが廃止されていました。
以前のArukasでアカウントを持っていた場合でも再作成となるようです。
以下ページからサインアップを行いました。
現在は予約制となっており、サインアップ後に登録可能な状態になったら招待メールが届きます。
(私の時は30分程度で届きました)
4つのプランの中から選択が可能に
課金体系についても公開されていました。
スペックやインスタンス数の制限などの違いで以下4つのプランがあるとのことです。
| 名称 | vCPU | RAM | 価格 | 概要 |
|---|---|---|---|---|
Free |
0.1 | 128MB | 無料 | 同時に起動できるコンテナーインスタンスは一つだけ |
Hobby |
0.1 | 512MB | 0.74円/h |
FreeプランとCPU性能は同じ、RAMサイズ増 |
Standard x1 |
0.5 | 512MB | 1.48円/h |
HobbyプランからvCPU増 |
Standard x2 |
0.5 | 1024MB | 2.96円/h |
Standard x1プランからRAMサイズ増 |
なお、Freeプラン以外を一度でも起動した月は基本料金として月額50円上乗せされるとのことです。
APIも結構変わった
また、サービス再開に合わせてAPIについても更新されていました。
認証や必要なヘッダなどについては変更ないようですが、リソース名やリソースの内容についてはだいぶ変わっています。
例: app_setsとかは無くなりました。
旧Arukas APIを利用していた場合は変更が必要でしょう。
取り急ぎGo言語についてAPIライブラリを作成しておきましたのでぜひご利用ください。
APIライブラリを作ったらアプリも欲しくなりましたのでとりあえず作っておきました。
Arukasで任意のコマンドを実行する「Rarukas」コマンド
shell(sh)に対するremote-shell(rsh)みたいに、Arukasでもっと手軽にコマンド実行したいなーということでremote-arukas = rarukasというコマンド作りました。
GitHub: rarukas - CLI for running one-off command(s) on Arukas
Go言語で書いてますので、インストールはバイナリをGitHubからダウンロードして実行権付与するだけです。
ダウンロードは以下のGitHub Releasesページから行えます。
以下のような感じで任意のコマンドをArukas上のコンテナで実行可能です。
コンテナはオンデマンドに作成され、コマンド実行が終了すると破棄されます。エコですね!!
# 事前にAPIキーを環境変数に設定(コマンドラインオプションでも指定可) $ export ARUKAS_JSON_API_TOKEN=<APIトークン> $ export ARUKAS_JSON_API_SECRET=<APIシークレット> # Arukas上でcurlコマンドを実行 $ rarukas curl -L https://arukas.io/
動きとしてはこんな感じです。

- SSH用のキーペアを生成(オプション指定でキーの指定もできる)
- Arukas APIでコンテナ作成 & 起動、SSH用の公開鍵をArukas API経由でコンテナに渡す
(起動するコンテナはRarukas側で用意したSSH/SCP可能なイメージを利用してます) - (任意)コンテナが起動したらSCPでローカルのファイルをコンテナのworkdirへアップロード
- コンテナ上で指定のコマンド実行
- (任意)コンテナ上のworkdirをローカルにダウンロード
- Arukas APIでコンテナ破棄
実行したいコマンドはファイルでの指定もできる
実行したいコマンドはファイルでの指定も可能になっています。
例えばローカルマシンにrun_on_arukas.shというスクリプトを用意しておいて、以下のようにオプション指定すればOKです。
お好きなシェルスクリプトが利用できます!
# 実行したいコマンドを別ファイルで指定 rarukas -c run_on_arukas.sh
ローカルマシンのファイルをアップロード/コマンド実行後にコンテナからダウンロード
さらにはSCP経由でファイル/ディレクトリのやりとりができるため、
- ローカルの処理したいデータをアップロード
- Arukas上で加工
- 加工したデータをローカルにダウンロード
ということもできます。
このために--sync-dirというオプションを用意しており、これで指定したディレクトリをコマンド実行前にアップロード、コマンド実行後にダウンロードしてくれるようになります。
# カレントディレクトリの内容をアップロード/コマンド実行で生成されたファイルをダウンロード $ rarukas --sync-dir . "echo from-arukas > result.txt" # ローカルマシンにコンテナ上で生成されたファイルがダウンロードされている $ ls result.txt
ベースイメージの選択ができる
Arukas上で起動するコンテナのベースイメージはデフォルトでは軽量なalpineベースですが、実行したいコマンドに応じて以下のようなものを指定できます。
alpine: デフォルト、alpineベースの軽量イメージcentos: CentOS7ベースubuntu: Ubuntu 16.04ベースansible: Ansible実行用のalpineベースイメージsacloud: さくらのクラウド系ツール(usacloudやterraform、packerなど)の実行用イメージ、alpineベース
ベースイメージはオプション指定することで変更できます。
# ubuntuベースのイメージを利用する場合 rarukas --type ubuntu <your-command>
どんな時に使うの?
バッチ処理のオフロードや多少時間がかかってもいいから自分のマシンの負荷を上げたくない時などに便利です。
rarukasコマンドでArukasコンテナを起動するのには早くて10〜20秒、負荷状況によってはもう少しかかることもあるため速度を求める処理には向きませんが、
複数のコンテナに分散して並列に処理できるような場面では真価を発揮します。
利用例: 10コンテナでコマンドを分散/並列実行
以下のように xargsなどと組み合わせることで任意の処理を複数のコンテナに分散/並列実行できます。
この例ではecho Hello World from Rarukas -(連番)というコマンドを10台に分散/並列実行しています。
(複数インスタンスの利用となるため、--planオプションでhobbyプランを利用するように指定)
# 10コンテナに分散してコマンド実行 $ seq 10 | xargs -P10 -n1 rarukas --plan hobby echo Hello from Rarukas -$1
これを実行すると以下のような表示になるはずです。
ただし、並列実行のため順序は保証されませんので多少出力順が異なる可能性があります。
# 見やすくするために標準エラー出力は除いています Hello from Rarukas - 2 Hello from Rarukas - 9 Hello from Rarukas - 4 Hello from Rarukas - 1 Hello from Rarukas - 8 Hello from Rarukas - 3 Hello from Rarukas - 7 Hello from Rarukas - 10 Hello from Rarukas - 5 Hello from Rarukas - 6
利用例: Ansibleで複数マシンのプロビジョニングやレポート作成を分散/並列実行
先ほども出てきましたが、ansibleコマンドを実行できるイメージを用意しています。
これを利用すれば自マシンに負荷をかけることなく大量のサーバのプロビジョニングも行えますね。
まずはインベントリファイルやSSH用の秘密鍵などを準備しておきます。
この例ではプロビジョニング対象の各サーバ毎にインベントリファイル&秘密鍵を用意するようにしています。
# 対象のサーバ毎にインベントリファイルと秘密鍵を準備
$ tree .
.
├── host1
│ ├── ansible.cfg
│ ├── hosts
│ └── private_key
├── host2
│ ├── ansible.cfg
│ ├── hosts
│ └── private_key
├── host3
│ ├── ansible.cfg
│ ├── hosts
│ └── private_key
├── host4
│ ├── ansible.cfg
│ ├── hosts
│ └── private_key
└── host5
├── ansible.cfg
├── hosts
└── private_key
# バックグラウンドでrarukasコマンド起動(5台分)
$ rarukas --type ansible --plan hobby --sync-dir host1 ansible host1 -i hosts -m setup --tree ./ &
$ rarukas --type ansible --plan hobby --sync-dir host2 ansible host2 -i hosts -m setup --tree ./ &
$ rarukas --type ansible --plan hobby --sync-dir host3 ansible host3 -i hosts -m setup --tree ./ &
$ rarukas --type ansible --plan hobby --sync-dir host4 ansible host4 -i hosts -m setup --tree ./ &
$ rarukas --type ansible --plan hobby --sync-dir host5 ansible host5 -i hosts -m setup --tree ./ &
他にも大容量のファイルのファイルのダウンロード -> 他のサーバへ送信といったように自マシンやネットワークの負荷を軽減するような使い方もありますね。 色々応用できると思います。
でもお高いんでしょ?
Rarukasを使うことで手軽にコンテナを使い捨てできますが、その際に心配なのがやっぱり料金ですね。
例えば1台あたり10分かかる処理を10台で行なったとすると、1実行あたり100分、毎日1回実行とすると30日で3,000分 = 50時間ですね。
Hobbyプランだと時間あたり 0.74円ですので、月額利用料としては
@0.74円 × 50時間 + 基本料金50円 = 87円
なんと、87円!!!
87円ですよ!!これはお安いですね!!!
ちなみに、公式サイトの料金の部分に「課金は秒単位」と記載があるので、ちょっとだけ起動して破棄する = 使い捨てる運用にもってこいですね!!

ということでコンテナ使い捨てにRarukasは非常にお手軽です。
是非ご利用くださいー!!
終わりに
Arukasは3/19までは無料で利用できるとのことです。
この機会に一度試してみてはいかがでしょうか?
その際は是非Rarukasコマンドもよろしくお願いします!!
以上です。
【さくらのクラウド】baserCMS用のスタートアップスクリプトを使ってみた

baserCMSがさくらのクラウドと連携し、baserCMS環境を簡単に構築できるスタートアップスクリプトが追加されたとのニュースが出ていました。
baserCMSニュース: IaaS型クラウド「さくらのクラウド」に、baserCMSのスタートアップスクリプトが搭載
baserCMSはオープンソースカンファレンス(OSC)などで度々見かけてはいたものの、なかなか手を出せていなかったのでこの機会に試してみました。
baserCMSってなに?
この辺はやはり公式サイトにバッチリ書いていました。
公式サイトの紹介文には以下のような特徴が挙げられています。
- 日本人が日本人の為に開発している国産CMS(コンテンツマネージメントシステム)
- CakePHPをベースとしているので、カスタマイズ性、メンテナンス性が高い
- メールフォームや新着ブログなどのプラグインや管理画面の枠組みを最初から装備
- スマートフォーンや携帯サイトにも対応
- マニュアルやソースコードのコメントが日本語
ライセンスはMITだそうです。
ざっと公式サイトを見ましたが、ドキュメントが非常に充実しているなーという印象です。
baserCMSのインストール
スタートアップスクリプトの前に、通常のbaserCMSのインストール手順を確認してみました。
インストール手順は公式サイトのはじめてガイドの中に導入マニュアルがまとめられています。
通常のインストール手順としては
- (1) baserCMSのソース一式をダウンロード
- (2) サーバにアップロード
- (3) ブラウザでインストーラーページを開く
- 必要に応じてWebサーバの設定変更など
- (4) データベースの選択(MySQL/PostgreSQL/SQLite3が選べる)
- (5) 管理ユーザーの登録
という流れです。多くのCMSと同じ流れですね。
慣れている方であればすぐに設置可能でしょう。
baserCMS用のスタートアップスクリプトは何をしてくれるの?
スクリプトを眺めると、先ほどのインストール手順を一気に行ってくれるもののようです。
割と面倒なWebサーバや関連ライブラリのインストール、DBのセットアップ、意外と忘れがちなサーバのタイムゾーンの設定などを行っています。
これを利用すればインストールが非常に楽になりそうです。
ということで早速スタートアップスクリプトを利用してbaserCMSをインストールしてみます。
さくらのクラウドでbaserCMS用スタートアップを利用
手順としては以下の通りです。
まずはさくらのクラウドのコントロールパネルにアクセスします。
アカウントをお持ちでない場合はこちらからアカウント開設を行っておきます。
1) IaaS画面へ遷移
ログイン後表示される画面でIaaSを選択します。

2) ゾーン選択 -> サーバ作成画面へ
次に対象のゾーンを選択します(以下図の①)。ゾーンによって価格が若干異なりますのでお好みのゾーンを選択してください。
ゾーン選択後にサーバ管理画面を開き(図の②)、右上の方にある「追加」ボタン(図の③)をクリックします。

3) サーバ作成画面でシンプルモードのチェックを外す
デフォルトではシンプルモードという、簡易選択画面になっていると思います。
スタートアップスクリプトはシンプルモードでは選択できませんのでチェックを外しておきます。

4) サーバのスペック選択(CPU/メモリ/ディスクなど)
続いて作成するサーバのスペックを選択します。
CPUとメモリについては後から変更可能ですので最初は適当に選べば良いと思います。
(baserCMSのドキュメントを確認しましたが、特に推奨スペックは記載がなさそうでした…)
また、baserCMSのスタートアップスクリプトはCentOS7のみ対応ということですので、ディスクについては
- ディスクソースは
アーカイブを選択 - アーカイブ選択では
CentOS7を選択
としてください。
ディスクサイズについてですが、こちらは先ほどのCPU/メモリと異なり、増設するのに若干の作業が必要となります。
(別ディスクを増設する or より大きいサイズのディスクにコピーして移行など)
なので、ある程度のディスク利用が見込める場合は最初から大きめにしておくのがオススメです。

5) ディスクの修正
続いて「ディスクの修正」という欄に入力を行なっていきます。
まずサーバのrootユーザのパスワードを入力します。
本番運用するサーバであればここで公開鍵を登録しておくべきなのですが、今回は省略しています。
なるべく登録をお勧めします。
そしていよいよスタートアップスクリプトの設定を行います。
スタートアップスクリプトとしてshellを選択すると、スクリプト一覧のリストが表示されます。
この中からbaserCMSを選択します。

6) baserCMS関連の設定
baserCMSスタートアップスクリプトを選択すると、その下部にbaserCMS関連の設定項目を入力する欄が表示されます。
以下3つは必須となっていますので忘れずに入力してください。
- baserCMS 管理ユーザー名
- baserCMS 管理ユーザーのパスワード
- baserCMS 管理ユーザのメールアドレス
ここで入力したユーザー名/パスワードは、後ほどbaserCMSの管理画面にログインする際に利用します。

サーバ作成画面にはその他入力項目もありますが、適当に入力してください。
最後に画面下部にある「作成」ボタンを押せばサーバ作成が行われます。 作成完了まで数分かかることもありますので少し待ちましょう。

動作確認!!
サーバ作成はうまくいきましたね?
それでは早速baserCMSの画面を開いてみましょう。
まずはさくらのクラウドのコントロールパネルから、作成されたサーバのグローバルIPアドレスを確認します。
サーバ一覧画面にサーバのグローバルIPが表示されていますので控えておきます。
(右クリックするとIPアドレスのコピーができますよ!)

あとはブラウザから以下URLをひらけばbaserCMSのトップページが表示されるはずです。
- 公開画面:
http://<サーバのグローバルIP>/ - 管理者画面:
http://<サーバのグローバルIP>/admin
公開画面トップページ

管理者ログイン画面

管理者ダッシュボード

ということでbaserCMS環境が非常に簡単に構築できました。
あとは公式サイトの導入マニュアルを参照しながらカスタマイズしていくだけですね。
導入マニュアルには「インストールあとのはじめの一歩」というページにどのような設定を行えば良いのかについてまとめられていますので、インストール後はこちらもご参照ください。
以上です。Enjoy!!