Docker/InfraKitのインスタンスプラグインの作り方
今回はDocker/InfraKitのインスタンスプラグインの書き方について扱います。
はじめに
今回のゴール
当記事では以下2点をゴールとしています。
これらの解説のために、最小限の機能しか持たないインスタンスプラグインを(Go言語を用いて)ステップバイステップで作成してみます。
想定読者
- InfraKitのチュートリアルを一通りこなした方
- Go言語(初心者レベル)の開発スキルをお持ちの方
なお、インスタンスプラグインの作成に関しては、Dockerについての知識は不要です。
執筆時点でのInfraKitのバージョン
当記事執筆時点での最新版を利用しました。
InfraKitはガンガンとバージョンが上がり、SPIの定義も頻繁に変わります。
あくまで現時点での情報という点は留意ください。
0. 準備編
まずはInfraKitそのものについて全体像を簡単に押さえておきましょう。
InfraKitの役割
InfraKitとは一言で言うとインフラストラクチャのオーケストレーションを行うためのツールキットとのことです。
分散システムの構築や、インフラストラクチャの上流でコンテナなどのオーケストレーションを行うために、
- インフラストラクチャの状態を、
- ユーザがあらかじめ定義した状態に「保つ」こと
を目的としています。
状態を保つために、
- インフラストラクチャの現在の状態を把握
- 必要に応じて作成/破棄
を行います。
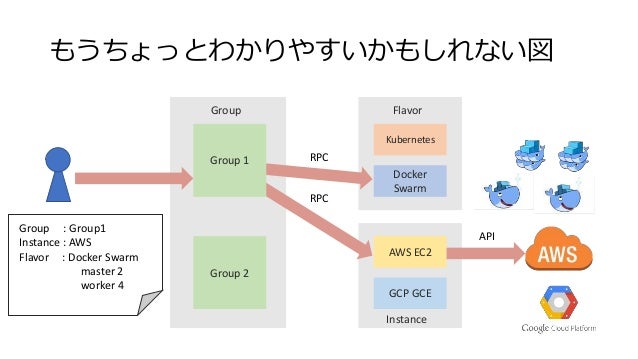
InfraKit = Group/Flavor/Instanceの3つのプラグイン(役割)の協調動作
以下の3つのプラグイン(役割)から構成されています。
Group(グループ)
個々のインスタンスをなんらかのルールで束ねたグループとして管理する役割を持ちます。
以下のような操作が行えるようになっています。
- グループの定義を受け取り、グループの管理を開始する
- グループの状態を把握する
- グループを破棄する
Instance(インスタンス)
グループのメンバーとなるインスタンスの操作/管理を行う役割を持ちます。
グループからの指示を受け、以下のような作業を行います。
Flavor(フレーバー)
グループ内のメンバーがどう動作をすべきかを定義する役割を持ちます。
- メンバーが実行すべきサービス(コマンド)の定義
- サービス(コマンド)が動作しているかの確認(ヘルスチェック)
なお、NTTの大嶋さん(InfraKitのコアメンテナ!!)が以下のような全体図を書かれています。
インフラ構成を定義としてグループに与えたら、構築や監視をよしなにやってくれるという感じですね。
各プラグインの実体
各プラグインは特定のAPIを持ったHTTPサーバで、UNIXドメインソケットでリッスンし、JSON-RPC2.0でやり取りします。
プラグインは共通のディレクトリ(通常は~/.infrakit/plugins)にソケットファイルを作成することで、
お互いに発見/呼び出しを行えるようになっています。
各プラグインが持つべきAPIは以下にドキュメントがあります。
各プラグインはGoで書く必要はなく、お好きなプログラミング言語を用いて作成することが可能です。
なお、Goを用いてプラグインを作成する場合、InfraKit側から提供されている便利なユーティリティ/ライブラリが利用可能です。
参考: https://github.com/docker/infrakit/tree/master/pkg/rpc
infrakitCLIについて
プラグインの状態確認や操作を簡単にするために、開発用CLI(コマンド)であるinfrakitが提供されています。
参考: https://github.com/docker/infrakit/blob/master/cmd/infrakit/README.md
InfraKitの実行自体に必須というわけではないのですが、あると便利ですので当記事でも利用していきます。
もしまだお手元にinfrakitコマンドがない場合はInfraKitのチュートリアルを参考にビルドしておいてください。
参考: InfraKitチュートリアル
ということで、これらの知識を持った上で早速プラグインの作成をしてみましょう。
今回作成するインスタンスプラグインについて
今回は最小限の機能しか持たないインスタンスプラグインをinfrakit-instance-minimumという名前で作成してみます。
GitHub: infrakit-instance-minimum
このプラグインは以下のような機能を持っています。
InfraKitが提供しているインスタンスプラグインのサンプル実装のfileインスタンスプラグインを参考にしていますが、
より機能を削り必要最低限のコードしか持たないものになっています。
1. 何もしないプラグインの作成
最初の段階として、何もしないプラグインを実装しInfraKitで認識できるところまでを実装してみます。
infrakitコマンドで起動しているプラグインを確認
まずはinfrakitコマンドで起動しているプラグインを確認してみます。
$ build/infrakit plugin ls
INTERFACE LISTEN NAME
現時点では何も起動していませんので何も表示されないのが正解です。
もし何かプラグインを起動しておいた場合は以下のような表示になります。
$ build/infrakit plugin ls
INTERFACE LISTEN NAME
Instance/0.6.0 ~/.infrakit/plugins/instance-file instance-file
プラグインの作成
GoでInfraKitのプラグインを作成する場合、InfraKit側から提供されているユーティリティを用いることで楽に実装可能です。
具体的には以下の実装を行うだけでインスタンスプラグインとして動作させることが可能です。
SPIとはService Provider Interfaceの略です。
以下のようにGoのインターフェースとして定義されていますので、これを満たす実装を行なっていきます。
// Plugin is a vendor-agnostic API used to create and manage resources with an infrastructure provider. type Plugin interface { // Validate performs local validation on a provision request. Validate(req *types.Any) error // Provision creates a new instance based on the spec. Provision(spec Spec) (*ID, error) // Label labels the instance Label(instance ID, labels map[string]string) error // Destroy terminates an existing instance. Destroy(instance ID, context Context) error // DescribeInstances returns descriptions of all instances matching all of the provided tags. // The properties flag indicates the client is interested in receiving details about each instance. DescribeInstances(labels map[string]string, properties bool) ([]Description, error) }
ソース: https://github.com/docker/infrakit/blob/master/pkg/spi/instance/spi.go
開発用にディレクトリ作成
まず、作成するプラグイン用のソースを格納するディレクトリを作成します。
mkdir infrakit-instance-minimum; cd infrakit-instance-minimum
以降はこのディレクトリ内で作業します。
インスタンスプラグインのSPIを実装(空の実装)
次にSPIの実装をplugin.goとして以下のように作成します。
plugin.go
package main import ( "github.com/docker/infrakit/pkg/types" "github.com/docker/infrakit/pkg/spi/instance" ) type plugin struct{} func NewMinimumInstancePlugin() instance.Plugin { return &plugin{} } func (p *plugin) Validate(req *types.Any) error { return nil } func (p *plugin) Provision(spec instance.Spec) (*instance.ID, error) { return nil, nil } func (p *plugin) Label(instance instance.ID, labels map[string]string) error { return nil } func (p *plugin) Destroy(instance instance.ID, context instance.Context) error { return nil } func (p *plugin) DescribeInstances(labels map[string]string, properties bool) ([]instance.Description, error) { return []instance.Description{}, nil }
SPIを実装したプラグインを起動するためのエントリーポイント作成
次に、プラグインを起動するエントリーポイントとしてmain.goを以下のように作成します。
main.go
package main import ( "github.com/docker/infrakit/pkg/cli" instance_plugin "github.com/docker/infrakit/pkg/rpc/instance" ) func main() { cli.RunPlugin("instance-minimum", instance_plugin.PluginServer(NewMinimumInstancePlugin())) }
ビルド & 起動
これだけでInfraKitのインスタンスプラグインとしての最低限の体裁が整っています。
早速ビルドして起動し、infrakitコマンドから認識できているか確認してみましょう。
(GOPATHの設定とかは適当にやっておいてくださいね。)
#ビルド $ go build #起動(フォアグラウンド起動) $ ./infrakit-instance-minimum INFO[0000] Listening at: ~/.infrakit/plugins/instance-minimum INFO[0000] PID file at ~/.infrakit/plugins/instance-minimum.pid
起動できたら、別のコンソールなどからinfrakitコマンドで確認してみましょう。
$ build/infrakit plugin ls
INTERFACE LISTEN NAME
Instance/0.6.0 ~/.infrakit/plugins/instance-minimum instance-minimum
無事に確認できましたね?おめでとうございます!これでインスタンスプラグインが作成できました!!!
とはいえ、実装は空ですのでこのままでは何もできません。次の段階ではもう少し実装を足してみましょう。
2. インスタンスの作成処理の実装
続いて、もう少しインスタンスプラグインらしくするために、インスタンスの生成処理を実装してみます。
具体的には、以下のような定義をグループプラグインに与えることでインスタンスの生成が行えるようにしてみます。
{
"ID": "example",
"Properties": {
"Allocation": {
"Size": 3
},
"Instance": {
"Plugin": "instance-minimum",
"Properties": {}
},
"Flavor": {
"Plugin": "flavor-vanilla",
"Properties": {}
}
}
}
グループプラグインの起動と定義ファイル(JSON)の作成
まずはグループプラグインを起動しておきましょう。
グループプラグインの実装には、InfraKitが提供するデフォルト実装であるinfrakit-group-defaultを利用します。
また、フレーバープラグインも必要となりますので起動しておきます。
フレーバープラグインの実装には、InfraKitが提供するサンプルであるinfrakit-flavor-vanillaを利用します。
#グループプラグイン(default)の起動 $ build/infrakit-group-default #フレーバープラグイン(vanilla)の起動 $ build/infrakit-flavor-vanilla
起動後、infrakit plugin lsの結果が以下のようになるはずです。
$ build/infrakit plugin ls
INTERFACE LISTEN NAME
Flavor/0.1.0 ~/.infrakit/plugins/flavor-vanilla flavor-vanilla
Group/0.1.0 ~/.infrakit/plugins/group group
Metadata/0.1.0 ~/.infrakit/plugins/group group
Instance/0.6.0 ~/.infrakit/plugins/instance-minimum instance-minimum
続いて定義ファイル(JSON)を以下のように作成しておきます。
$ vi example.json #以下の内容を記述 { "ID": "example", "Properties": { "Allocation": { "Size": 3 }, "Instance": { "Plugin": "instance-minimum", "Properties": {} }, "Flavor": { "Plugin": "flavor-vanilla", "Properties": {} } } }
infrakitコマンドでグループプラグインに定義を渡す
作成した定義ファイルをグループプラグインに渡してみましょう。 定義ファイルの内容は以下のようになっています。
以下のコマンドでグループプラグインに定義を渡せます。
$ build/infrakit group commit example.json [...省略...] INFO[0021] Committing group example (pretend=false) Committed example: Managing 3 instances INFO[0021] Adding 3 instances to group to reach desired 3 panic: runtime error: invalid memory address or nil pointer dereference [signal SIGSEGV: segmentation violation code=0x1 addr=0x0 pc=0x140c474] goroutine 40 [running]: github.com/docker/infrakit/pkg/plugin/group.(*scaledGroup).CreateOne(0xc4201f2460, 0x0) /go/src/github.com/docker/infrakit/pkg/plugin/group/scaled.go:102 +0x6d4 github.com/docker/infrakit/pkg/plugin/group.(*scaler).converge.func2(0xc42016e9e0, 0xc420170730) /go/src/github.com/docker/infrakit/pkg/plugin/group/scaler.go:277 +0x63 created by github.com/docker/infrakit/pkg/plugin/group.(*scaler).converge /go/src/github.com/docker/infrakit/pkg/plugin/group/scaler.go:278 +0x6c2
3つのインスタンスを追加しようとしていますが、エラーが出ていますね。
これはインスタンスプラグインの実装が空だからです。また実装後に改めて試すことにしましょう。
なお、グループプラグインが異常終了してしまうために~/.infrakit/plugin/groupにファイルが残ったままになっています。
このままだと、次回グループプラグインを起動するときにエラーとなりますので手動で削除し、改めてグループプラグインを起動しておきましょう。
$ rm ~/.infrakit/plugins/group #あらためてグループプラグインを起動 $ build/infrakit-group-default
インスタンスの作成処理(Provision)の実装
ではもう少し実装を進めます。まずはインスタンスの作成処理を担当するProvisionメソッドを実装します。
plugin.goに追記していくのですが、追記内容が若干多いため、詳しい内容は以下の変更差分を参照してください。
- ソース: https://github.com/yamamoto-febc/infrakit-instance-minimum/blob/2e035ef8b1e0b99293cd5d76f6265b9a41818366/plugin.go
- 変更差分
Provisionメソッドは以下のように修正されています。
plugin.goのProvisionメソッド
func (p *plugin) Provision(spec instance.Spec) (*instance.ID, error) { // ランダムなIDを生成 id := instance.ID(fmt.Sprintf("instance-%d", rand.Int63())) path := filepath.Join(instanceDir, string(id)) // ディレクトリ(/tmp/infrakit-dummy-instances)がなければ作成 _, err := os.Stat(instanceDir) if err != nil { err := os.MkdirAll(instanceDir, os.FileMode(0777)) if err != nil { return nil, err } } // ファイル作成 if _, err := os.Stat(path); err != nil { f, err := os.Create(path) if err != nil { return nil, err } defer f.Close() } return &id, nil }
引数のinstance.Spec経由でグループプラグインに与えた設定内容を参照できるのですが、今回は利用していません。
本来はここで与えられた設定を読み込み、必要なインスタンス生成処理を行います。
今回はインスタンス生成の代わりに"instance-“+ランダムな数値という名前のファイルを作成するだけにしています。
次にProvisionの戻り値についてですが、instance.IDへの参照を返すことになっています。
今回はファイル名をそのままIDとして利用しています。
本来はインスタンスを一意に特定できるIDを生成または取得して返すように実装します。 (例:AWSだったらEC2のリソースIDを返す、など)
実行!!
ではビルドして実行してみましょう。古いインスタンスプラグインは一旦停止(ctrl+cでOK)し、改めてビルド&起動してください。
起動したら以下のコマンドを実行してみましょう。
Provisionを実装したインスタンスプラグインを実行
#グループプラグインへ設定ファイルを受け渡し $ build/infrakit group commit example.json [...省略...] INFO[2638] Committing group example (pretend=false) Committed example: Managing 3 instances INFO[2638] Adding 3 instances to group to reach desired 3 INFO[2638] Created instance instance-4559224122183623453 with tags map[infrakit.config_sha:cvb62mzivlzgdtja24rczqhdtktqx2sn infrakit.group:example] INFO[2638] Created instance instance-3099390593271315395 with tags map[infrakit.config_sha:cvb62mzivlzgdtja24rczqhdtktqx2sn infrakit.group:example] INFO[2638] Created instance instance-4785619793559779603 with tags map[infrakit.config_sha:cvb62mzivlzgdtja24rczqhdtktqx2sn infrakit.group:example]
うまくいきましたね!!/tmp/infrakit-dummy-instances/配下にファイルが3つ作成されていることが確認できるはずです。
ですが、、、少々問題があることに気づくかもしれません。
問題: ファイルがどんどん増えていく!?!?
しばらく待つと以下のようなログが表示され、/tmp/infrakit-dummy-instances/配下にファイルがどんどん増えていっているはずです。
INFO[2648] Created instance instance-1391249888231321150 with tags map[infrakit.config_sha:cvb62mzivlzgdtja24rczqhdtktqx2sn infrakit.group:example] INFO[2648] Created instance instance-4551305389484104975 with tags map[infrakit.config_sha:cvb62mzivlzgdtja24rczqhdtktqx2sn infrakit.group:example] INFO[2648] Created instance instance-102084934595871505 with tags map[infrakit.group:example infrakit.config_sha:cvb62mzivlzgdtja24rczqhdtktqx2sn]
原因: InfraKitがインスタンスの状態を知らないから
これは、InfraKitが現在インスタンスがどのような状態かを知らない = 存在しないと思っているために、毎回インスタンスを作ろうとしてしまうことが原因です。
まあそんな処理は実装してないから当たり前ですね。
ということで、次はこの「インスタンスの状態を調べる」 = DescribeInstancesメソッドを実装していきます。
後片付け
このままではファイルが延々と増え続けてしまいます。このため、グループプラグインにこのグループの破棄を指示しておきましょう。
ついでに今回インスタンスプラグインが作成したファイルも削除しておきます。
# group destroyを実施(引数にはグループのIDを指定) $ build/infrakit group destroy example # インスタンスプラグインが作成したダミーファイルを削除しておく $ rm /tmp/infrakit-dummy-instances/*
3. インスタンスの状態を調べるDescribeInstancesの実装
続いてDescribeInstancesを実装しましょう。
plugin.goに追記していくのですが、追記内容が若干多いため、詳しい内容は以下の変更差分を参照してください。
- ソース:https://github.com/yamamoto-febc/infrakit-instance-minimum/blob/ef5f497a23021cab9a04aefac87b3749e3639de2/plugin.go
- 変更差分
plugin.goのDescribeInstanceメソッド
func (p *plugin) DescribeInstances(labels map[string]string, properties bool) ([]instance.Description, error) { // ディレクトリ(/tmp/infrakit-dummy-instances)配下のファイルを取得 entries, err := ioutil.ReadDir(instanceDir) if err != nil { return nil, err } result := []instance.Description{} // インスタンス情報の組み立て for _, entry := range entries { result = append(result, instance.Description{ ID: instance.ID(entry.Name()), }) } return result, nil }
ここでは/tmp/infrakit-dummy-instancesディレクトリ配下に存在するファイルを参照し、インスタンス情報を組み立てています。
本来は、DBを参照したり、APIを呼び出すなどで現在のインスタンスたちの情報を組み立ててあげる処理となります。
実行!!
ではビルドして実行してみましょう。先ほどと同じく、古いインスタンスプラグインは一旦停止(ctrl+cでOK)し、改めてビルド&起動してください。
起動したら以下のコマンドを実行してみましょう。
Provisionを実装したインスタンスプラグインを実行
#グループプラグインへ設定ファイルを受け渡し $ build/infrakit group commit example.json [...省略...] INFO[3889] Committing group example (pretend=false) Committed example: Managing 3 instances INFO[3889] Adding 3 instances to group to reach desired 3 INFO[3889] Created instance instance-377673683573739334 with tags map[infrakit.group:example infrakit.config_sha:cvb62mzivlzgdtja24rczqhdtktqx2sn] INFO[3889] Created instance instance-8516032680601656640 with tags map[infrakit.group:example infrakit.config_sha:cvb62mzivlzgdtja24rczqhdtktqx2sn] INFO[3889] Created instance instance-6082236286152429340 with tags map[infrakit.group:example infrakit.config_sha:cvb62mzivlzgdtja24rczqhdtktqx2sn]
今度はしばらく待ってもファイルがどんどん増えなくなっているはずです。
動作確認: インスタンス(の代わりのファイル)を消してみる
それではInfraKit自体の動作確認になるのですが、/tmp/infrakit-dummy-instances配下のファイルを消してみましょう。
InfraKitは変更を検知し、あらかじめ決められたインスタンス数(今回は3)を保つために新たなインスタンスの作成を行います。
$ rm /tmp/infrakit-dummy-instances/いずれかのファイル # 数秒待つと、InfraKitが自動的に検知し、インスタンス(ファイル)が新たに作成される
問題: ファイルが消えない??
今度は逆にインスタンス(の代わりのファイル)を増やしてみましょう。 先ほどと同じように、あらかじめ決められたインスタンス数(今回は3)を保つためにインスタンスの削除が行われるはずです。
$ touch /tmp/infrakit-dummy-instances/instance-00000000 # 数秒待つと、InfraKitが自動的に検知するが、、、 INFO[4882] Removing 1 instances from group to reach desired 3 INFO[4882] Destroying instance instance-000000000 INFO[4892] Removing 1 instances from group to reach desired 3 INFO[4892] Destroying instance instance-000000000 INFO[4902] Removing 1 instances from group to reach desired 3 INFO[4902] Destroying instance instance-000000000 [...以降延々と続く...]
原因: インスタンスの削除処理を実装していないから
今回は予想がつくかと思いますが、インスタンスの削除処理を実装していないからですね。
ということで、次はこの「インスタンスを削除する」 = Destroyメソッドを実装していきます。
後片付け
先ほどと同じく後片付けを実行しておいてください。
# group destroyを実施(引数にはグループのIDを指定) $ build/infrakit group destroy example # インスタンスプラグインが作成したダミーファイルを削除しておく $ rm /tmp/infrakit-dummy-instances/*
4. インスタンスを削除するDestroyの実装
続いてDestroyを実装しましょう。
plugin.goに追記していくのですが、追記内容が若干多いため、詳しい内容は以下の変更差分を参照してください。
- ソース: https://github.com/yamamoto-febc/infrakit-instance-minimum/blob/1d8e324d53585321136699a375e83c2d473f2f1c/plugin.go
- 変更差分
plugin.goのDestroyメソッド
func (p *plugin) Destroy(instance instance.ID, context instance.Context) error { path := filepath.Join(instanceDir, string(instance)) _, err := os.Stat(path) if err == nil { //ファイルが存在する場合は削除 return os.Remove(path) } return nil }
完成!実行してみましょう!!
先ほどまでと同じです。
#グループプラグインへ設定ファイルを受け渡し $ build/infrakit group commit example.json [...省略...] INFO[3889] Committing group example (pretend=false) Committed example: Managing 3 instances INFO[3889] Adding 3 instances to group to reach desired 3 INFO[3889] Created instance instance-377673683573739334 with tags map[infrakit.group:example infrakit.config_sha:cvb62mzivlzgdtja24rczqhdtktqx2sn] INFO[3889] Created instance instance-8516032680601656640 with tags map[infrakit.group:example infrakit.config_sha:cvb62mzivlzgdtja24rczqhdtktqx2sn] INFO[3889] Created instance instance-6082236286152429340 with tags map[infrakit.group:example infrakit.config_sha:cvb62mzivlzgdtja24rczqhdtktqx2sn]
今度はインスタンスの削除処理が正常に行われるはずです。
$ touch /tmp/infrakit-dummy-instances/instance-00000000 # しばらく待つとInfraKitが検知してインスタンス削除処理を実施 INFO[5398] Removing 1 instances from group to reach desired 3 INFO[5398] Destroying instance instance-000000000
これで最低限の機能を持つインスタンスプラグインが作成できました。
本来はフレーバープラグインでの設定の反映なども行わないといけないのですが、その辺は必要に応じて既存のプラグインのソースを解析してみてください。
最後に、plugin.goのソース全体を載せておきます。
package main import ( "fmt" "github.com/docker/infrakit/pkg/spi/instance" "github.com/docker/infrakit/pkg/types" "math/rand" "os" "path/filepath" "io/ioutil" ) var ( instanceDir = "/tmp/infrakit-dummy-instances" ) type plugin struct{} func NewMinimumInstancePlugin() instance.Plugin { return &plugin{} } func (p *plugin) Validate(req *types.Any) error { return nil } func (p *plugin) Provision(spec instance.Spec) (*instance.ID, error) { // ランダムなIDを生成 id := instance.ID(fmt.Sprintf("instance-%d", rand.Int63())) path := filepath.Join(instanceDir, string(id)) // ディレクトリ(/tmp/infrakit-dummy-instances)がなければ作成 _, err := os.Stat(instanceDir) if err != nil { err := os.MkdirAll(instanceDir, os.FileMode(0777)) if err != nil { return nil, err } } // ファイル作成 if _, err := os.Stat(path); err != nil { f, err := os.Create(path) if err != nil { return nil, err } defer f.Close() } return &id, nil } func (p *plugin) Label(instance instance.ID, labels map[string]string) error { return nil } func (p *plugin) Destroy(instance instance.ID, context instance.Context) error { path := filepath.Join(instanceDir, string(instance)) _, err := os.Stat(path) if err == nil { //ファイルが存在する場合は削除 return os.Remove(path) } return nil } func (p *plugin) DescribeInstances(labels map[string]string, properties bool) ([]instance.Description, error) { // ディレクトリ(/tmp/infrakit-dummy-instances)配下のファイルを取得 entries, err := ioutil.ReadDir(instanceDir) if err != nil { return nil, err } result := []instance.Description{} // インスタンス情報の組み立て for _, entry := range entries { result = append(result, instance.Description{ ID: instance.ID(entry.Name()), }) } return result, nil }
おまけ: 今回未実装のメソッド/追加で実装した方が良いメソッド
今回未実装のメソッド
今回はインスタンスプラグインのSPIのうち、以下を実装しませんでした。
- Validate(req *types.Any) error
- Label(instance instance.ID, labels map[string]string) error
それぞれ簡単に役割を説明しておきます。
Validate(req *types.Any) error
その名の通り検証を行うメソッドです。
グループプラグイン経由で定義したインスタンスプロパティ関連の値が渡ってくるため、ここで検証処理を行います。
Label(instance instance.ID, labels map[string]string) error
インスタンスに"ラベル"をつけるためのメソッドです。
具体的にはキーと値がlabelsに入ってくるため、これをインスタンスと紐付けます。
自前のDBに保持したり、クラウド上のインスタンスであればメタデータとして登録したりします。
なお、拙作infrakit.sakuracloudでは、さくらのクラウドのサーバのDescriptionという文字列を格納するための属性に保持するように実装しました。
さくらのクラウドではサーバにメタデータを紐づける仕組みがなかったために苦肉の策というところでした。
(なお、さくらのクラウドにはタグという機能もあるのですが、文字数の制限があるために利用できませんでした)
追加で実装した方が良いメソッド
全てのプラグインは以下のインターフェースについても実装しておいた方が良さそうです。
github.com/docker/infrakit/pkg/spiパッケージの
VendorインターフェースInputExampleインターフェース
それぞれCLIなどに対し情報を返すためのメソッドです。
Vendorインターフェースは各プラグインの名称やバージョンなどを返すためのメソッドです。
今の所InfraKit側でこの情報を使っている部分はなさそうなのですが、AWS/GCP/DigitalOceanなどのインスタンスプラグインでも実装されていますので、なるべく実装しておいた方が良さそうな感じがしています。
InputExampleインターフェースは、そのプラグインがどのようなプロパティが設定できるのかの例を定義するメソッドです。
cliなどから利用されています(infoサブコマンドなど)。
終わりに
当記事では最低限の機能を持つInfraKitのインスタンスプラグインをステップバイステップで作成しました。
実際にプラグインを作成する際はInfraKitのリポジトリ内にある他のインスタンスプラグインの実装も参考にするのが良いかと思います。
手始めにexamplesのfileプラグインのソースを読むことをお勧め致します。
これは当記事と同じようにインスタンスとしてダミーのファイルを作成する処理を行っています。
VendorインターフェースやInputExampleインターフェースの実装もされていますし、短いソースですので一度眼を通してみてください。
以上です。Enjoy!!
参考資料
パッケージ管理ツール「whalebrew」〜透過的にDocker上でコマンドを実行する環境を作る〜
「whalebrew」という素晴らしいプロダクトが出ていました。
Homebrewのような感じでコマンドをインストールし、かつそのコマンドをDocker上で実行できるように環境を整えてくれるツールです。
# whalebrewコマンドで"whalesay"コマンドをインストールしてみる
$ whalebrew install whalebrew/whalesay
# DockerHubからイメージのダウンロードが行われる
Unable to find image 'whalebrew/whalesay' locally
Using default tag: latest
latest: Pulling from whalebrew/whalesay
e190868d63f8: Extracting [=======================> ] 30.64 MB/65.77 MB
909cd34c6fd7: Download complete
0b9bfabab7c1: Download complete
a3ed95caeb02: Waiting
00bf65475aba: Waiting
c57b6bcc83e3: Waiting
8978f6879e2f: Waiting
8eed3712d2cf: Waiting
# ダウンロードしたイメージを実行できるように、/usr/local/bin配下にエイリアスが作成される
# 最終的に以下のようなコマンドでDocker上で実行されることになる
# docker run -it -v "$(pwd)":/workdir -w /workdir $IMAGE "$@"
🐳 Installed whalebrew/whalesay to /usr/local/bin/whalesay
# インストールしたコマンドは作成されたエイリアスを通じ実行できる
$ whalesay 'hello'
_________
< hello!! >
---------
\
\
\
## .
## ## ## ==
## ## ## ## ===
/""""""""""""""""___/ ===
~~~ {~~ ~~~~ ~~~ ~~~~ ~~ ~ / ===- ~~~
\______ o __/
\ \ __/
\____\______/
以下、簡単に使い方などをメモしておきます。
インストール
今の所はWindowsは非対応のようです。Linux/Macなら動くと思います。
以下のようにバイナリをダウンロードして実行権を付与するだけです。
curl -L "https://github.com/bfirsh/whalebrew/releases/download/0.0.1/whalebrew-$(uname -s)-$(uname -m)" -o /usr/local/bin/whalebrew; chmod +x /usr/local/bin/whalebrew
使い方
コマンドのインストール
$ whalebrew install オーガニゼーション/イメージ名
オーガニゼーション/イメージ名にはDockerHub上のものを指定します。

検索
検索は現状ではwhalebrewオーガニゼーション配下のイメージに対してのみ有効みたいです。
$ whalebrew search イメージ名
whalebrewでインストール済みのコマンド一覧表示
$ whalebrew list
更新(upgrade)
$ whalebrew upgrade オーガニゼーション/イメージ名
動作設定
現在はエイリアスを作成する先のディレクトリを変更できるようです。
デフォルトは/usr/local/binですが、以下の環境変数で変更可能です。
WHALEBREW_INSTALL_PATH
パスの通ったディレクトリを指定しましょう。
内部動作
コマンドをインストールすると、WHALEBREW_INSTALL_PATH(デフォルト/usr/local/bin)配下に以下のようなファイルが作成されます。
例: whalebrew/whalesayコマンドをインストールした場合
#!/usr/bin/env whalebrew image: whalebrew/whalesay
これを実行すると、以下のようなDockerコマンドが(whalebrewを通じて)実行されます。
docker run -it -v "$(pwd)":/workdir -w /workdir $IMAGE "$@"
注意点は、dockerでのWORKDIRが/workdirに固定となっている点です。
コマンド実行時のカレントディレクトリの内容がコンテナ内の/workdirにボリュームとして割り当てられます。
なお、後述しますが、Dockerイメージ側でラベルが指定されている場合はこのパスが変更できるようです。
注:dockerクライアント実行環境にもよりますが、~/配下など、コンテナにバインドマウント可能なディレクトリでないとコマンド実行できないっぽいですね。
公開するイメージの作り方
以下の2つの条件を満たすだけです。
- DockerHub上に公開すること
- イメージに
ENTRYPOINTが設定されていること
以下のLABELをイメージに設定(Dockerfileに記述)しておくことで、動作のカスタマイズができるようです。
io.whalebrew.name : whalebrewでインストールした場合のコマンド名。デフォルトではイメージ名となる。
io.whalebrew.config.environment : コンテナに渡す環境変数。以下のように指定する。
# コマンド実行時に$TERMと$FOOBAR_NAMEを引き渡しする(-eオプション) LABEL io.whalebrew.config.environment '["TERM", "FOOBAR_NAME"]'
io.whalebrew.config.volumes : コンテナに割り当てるボリューム。以下のように指定する。
# ~/.dockerをコンテナの/root/.dockerに読み取り専用で割り当て(-vオプション) LABEL io.whalebrew.config.volumes '["~/.docker:/root/.docker:ro"]'
まとめ
これまでDockerイメージで配布されていたアプリの場合、whalebrewを使えば楽に配布〜実行設定できますね。
dockerコマンドを直接叩いてもらわなくてよくなる、aliasを張る必要がなくなるなど嬉しいですね!
ぜひ流行って欲しいところです。
公開されたばかりのプロダクトですのでバグもあるかと思いますが積極的に使っていきたいです。
以上です。 Enjoy!!
【golang】vendoring時はビルドタグでのフィルタリングは使わない方がいい
English version:【golang】Don't use filtering by build tags to vendoring
TL;DR
govendorではvendoringする際に無視するビルドタグが指定できる- しかし、ビルドに必要なファイルがvendorディレクトリ配下にコピーされないケースがある
- 必要なファイルがコピーされないことにより、クロスコンパイルできなくなるといった問題が起こるかもしれない
- なので、vendorディレクトリのサイズは増えてしまうが、ビルドタグでのフィルタリングはしない方がシンプルで良い
Introduction
現在、Go言語には次のようにたくさんのパッケージ管理(vendoring)ツールがあります。
こちらのページでは他にもたくさんのツールが紹介されています。
PackageManagementTools · golang/go Wiki · GitHub
私はその中でも、govendorをよく利用しています。
govendor は簡単/手軽に利用できるため、これまでたくさんのプロジェクトで利用してきました。
でもある時、govendorの設定次第では面倒な問題が発生することがわかりました。。。
What is the problem?
先月(2016/12)、Terraformに対して以下のPullRequestを作成しました。
このPRは、Arukasプロバイダを追加するものです。
この新しいプロバイダは以下のリポジトリにてサードパーティープラグインとしてリリース済みであったものを
Terraform本体に取り込んでもらうためのものでした。
このPRはすぐにマージされ、Terraform v0.8.3としてリリースされました。
しかしその時、、、

Windowsでビルドできなくなった!?!?
What's!? What's happened!?!?
Arukasプロバイダーはサードパーティープラグインとしてのリリース時にWindows版を含んでおり、(Windows上でも)問題なくビルドできていました。
Terraform本体に取り込んでもらう際、ソースコードへの変更は行われていないのに、なぜビルドが壊れてしまったのでしょうか?
Who broke the build on Windows?
原因を探るため、@jbardinからのメッセージで指摘されているライブラリgopkg.in/alecthomas/kingpin.v2から調査を始めることにしました。
ライブラリgopkg.in/alecthomas/kingpin.v2はArukasプロバイダによってimportされているものです。
このライブラリは、Arukasプロバイダをサードパーティープラグインとしてリリースしていた頃から利用しているため、Windowsでも問題なく利用できることが判明しています。
かつ、Terraform本体 / サードパーティープラグインとしてリリースしていたArukasプロバイダ共にvendoringにはgovendorを利用しています。
このため、(govendorによって)vendorディレクトリ配下にコピーされたgopkg.in/alecthomas/kingpin.v2ライブラリのファイルを比較してみることにしました。
Compare gopkg.in/alecthomas/kingpin.v2 files under vendor directory
比較結果は以下の通りです。

guesswidth.goがなんらかの理由でコピーされていないようです。
なぜでしょうか???
Answer: govendor was setted to ignore some build tags
(Terraformにおける)govendorの設定ファイルvendor/vendor.json で以下のような設定が行われています。
https://github.com/hashicorp/terraform/blob/v0.8.4/vendor/vendor.json#L3
"ignore": "appengine test",
govendorはvendor/vendor.jsonの"ignore"に設定された各値とソースファイルの接尾詞 or ソースコード中のビルドタグを比較し、
対象のファイルを無視すべきか判定しています。
この設定ではappengineとtestというタグが無視対象として設定されているということです。
そして、今回コピーされていなかったguesswidth.goのビルドタグは以下のようになっていました。
https://github.com/alecthomas/kingpin/blob/v2.2.3/guesswidth.go#L1
// +build appengine !linux,!freebsd,!darwin,!dragonfly,!netbsd,!openbsd
なお、*nix系プラットフォーム(Linx/BSD/MacOSなど)ではこのファイルの代わりにguesswidth_unix.goが利用されます。
こちらのファイルのビルドタグは以下のようになっています。
https://github.com/alecthomas/kingpin/blob/v2.2.3/guesswidth_unix.go#L1
// +build !appengine,linux freebsd darwin dragonfly netbsd openbsd
これらのビルドタグが与えられている場合、(対象プラットフォームが)Windowsでのビルドではguesswidth.goの方が利用されます。
しかし、vendor.jsonの"ignore"にてappengineが指定されているため、govendorはguesswidth.goを無視してしまうのです!!!
(日本語版注 : govendorはビルドタグを解析し、一つでもignoreに設定されたタグとマッチするタグが指定されている場合は該当ファイルをvendor配下にコピーしないのです)
この状況では、*nix系プラットフォームではビルド出来ても、Windowsではビルド出来ないのです。
ではどうすれば良いのでしょうか??
Conclusion
vendoring時にビルドタグでフィルタリングすることは、vendorディレクトリのサイズ削減ができるという利点はありますが、
いくつかのプラットフォームでビルドできなくなるといった問題が発生する可能性があります。
さらに、これらの問題解決の際は、importしている各ファイルのビルドタグの確認といった面倒な調査が必要になるでしょう。
このため、vendoring時のビルドタグによるフィルタは利用しない方が良いです。
(注:ただし、ignoreタグとtestタグについてはフィルタしても問題なく動くと思います)
これらの問題があってもビルドタグによるフィルタリングを利用するユースケースはあるのでしょうか?
少なくとも私は思いつきませんでした。
あなたはどう思いますか?
もし良い方法があればこの記事にコメントをください!
2016年 活動まとめ
2016年も残すところ僅かとなりました。
今年は実り多い年だったので、忘れないうちに活動内容をまとめておきます。
全体的には?
オープンソース活動、記事執筆ともに順調な1年でした。
- アプリ開発 : 合計30本以上のリリース
- 記事執筆:Qiita / さくらのナレッジ / ブログ 、合計42本を執筆
- イベントでの発表: 1回/月程度の頻度で勉強会/イベントへ参加、うち3イベントで発表あり
GitHubのcontributionはこんな感じです。

傾向として、土日は家族と過ごすことが多いため、平日のコミットが多めとなっておりました。
アプリ開発の実績
アプリ単体でリリースしたものだけで15アプリ、記事連動したアプリやDockerイメージなどの細々したものを含めると30以上のアプリのリリースを行いました。
ライブラリ関連
さくらのクラウド用APIライブラリ「libsacloud」
docker-machine-sakuracloudで得た、Go言語でのさくらのクラウドAPI操作のノウハウを他のプロダクトでも利用できるようにするために
APIライブラリとしてスクラッチ開発を行いました。
このライブラリは現在でもバンバン開発しており、公式のAPIライブラリ:saklientよりも機能が充実していたりします。
さくらのクラウドへ新たな機能が追加された場合、概ね1週間以内には対応しています。
2016年に開発したプロダクトの多くがこのlibsacloudを利用する形となっているため、本年の本格的な活動開始がこのプロダクトで正解だったと思っています。
さくらのIoT Platform用APIライブラリ「sakuraio-api」
さくらのIoT Platform用のAPIライブラリです。
主に「Terraform for さくらのIoT Platform」での利用のために開発しました。
こちらは来年も順次充実させていく予定です。
なお、さくらのIoT Platform用のライブラリとしては、WebHook関連のライブラリとして以下のようなものもあります。
こちらは先の「sakuraio-api」に統合を予定しています。おそらく来年上旬あたりの対応となると思います。
Terraform関連
Terraform for さくらのクラウド
Terraform for Arukas
Terraform for さくらのIoT Platform
さくらのクラウド、Arukas、さくらのIoT Platformへの対応を行いました。
特にさくらのクラウドについてはさくらのナレッジにて入門記事の連載を執筆中ですので、引き続き対応を強化していきます。
Packer関連
Packer for さくらのクラウド
さくらのクラウド上にマシンイメージを作成するためのツール「Packer for さくらのクラウド」を作りました。 こちらは開発はひと段落させたつもりですので、来年は大きな機能追加などは行わずバグフィックス中心になる予定です。
Docker関連
Infrakit - さくらのクラウド用プラグイン
2016年10月に発表されたDockerの新しいアーキテクチャへの挑戦「infrakit」のプラグインとして、
さくらのクラウド対応を試験的に行ってみたものです。
infrakit対応プラグインとしては世界最速での開発/発表を行うことができました。
infrakit自体のDockerへの取り込みはまだまだ見えない要素も多いのですが、
infrakit.awsの実装など、具体的な実装ができつつありますので、様子を見ながらさくらのクラウド対応を行うことを視野に入れています。
WordPress関連
WordPress + オブジェクトストレージ用プラグイン「wp-sacloud-ojs」
WordPress + ウェブアクセラレータ用プラグイン「wp-sacloud-webaccel」
依然シェアNo.1であり続けているCMSの王様「WordPress」にて、さくらのクラウドのプロダクトを利用するためのプラグインを作りました。
こちらは開発はひと段落ついたかなーと感じているため、来年はバージョンアップ対応やバグフィックス中心になりそうです。
監視関連
Mackerelとさくらのクラウドのインテーグレーションツール「Sackerel」
はてなさんのイケてる監視ツール「Mackerel」とさくらのクラウドをインテグレーションするツールを作りました。
今後はMackerelだけでなく、もっと汎用的に利用できるようにすべくアイディアを練っている段階です。
PrometheusやZabbixなど他の監視ツールともうまく連携できる仕組みにできればいいなーと漠然と考えています。
その他:さくらのクラウド関連の細々したツール類
さくらのクラウド上の全リソース削除コマンド「sacloud-delete-all」
さくらのクラウドへのISOイメージアップロードコマンド「sacloud-upload-image」
さくらのクラウドへのアーカイブアップロードコマンド「sacloud-upload-archive」
細かいCLIツールを作成しました。
各ツールがバラバラに存在してしまっていることや、公式CLIである「sacloud」の開発が停滞していることもあり、
そろそろさくらのクラウド関連のCLIツールをまとめて再編してコミュニティーツールとして提供するのがいいかな?とも考えています。
この辺りは考えがまとまっていないので来年はじっくり取り組むつもりです。
その他:Arukas関連のツール類
プルリクエスト駆動開発用デプロイパイプラインツール「arukas-ship」
GitHub〜DockerHub〜Arukasとデプロイパイプラインを形成するためのツールです。
GitHubにpushするだけでArukasへデプロイできます。
このツールはQiitaに紹介記事を書いたのですが、
投稿から半年近く経っても徐々にストック/PVが伸びている息の長いプロダクトだったりします。
Arukas関連のプロダクトについては、来年4月の正式リリースに合わせ、見直し/更新などを行う予定です。
その他:オープンソースプロダクト開発への参加
docker-machineやpackerなどへのコントリビューションを行いました。
記事の執筆(全42本)
Qiitaへの投稿(34本)
Qiitaへは大小合わせて34本記事を投稿しました。
特に印象深い記事をいくつかピックアップしておきます。
DockerBlogからの翻訳&紹介記事なのですが、非常に興味深い内容でした。
CGIのように、リクエストを受けたらDockerコンテナを起動し処理するという内容ですが、
Dockerを用いたサーバーレスな構成の一例として非常にインスピレーションを刺激してくれました。
Docker + infrakitについての紹介です。
未だにinfrakitについて国内のみならず海外でも情報が少ないです。貴重な日本語記事ではあるのですが、
すでに若干コードの更新などが行われていますので、もしinfrakitに大きめな動きがあるようであれば新たに記事を投稿するつもりです。
HashicorpのNomadを利用した環境構築例です。
Nomadはもっと流行ってもいい気はするのですが、、コンテナ界隈、特にオーケストレーション周りの熾烈な争いの中で
Nomadは今ひとつ突き抜けられない感じがしていますので、しばらくは概要を軽く様子見する程度で良いかなーと感じてます。
さくらのナレッジへの投稿(6本)
月に1本程度のペースで投稿しています。
現在はTerraformについての連載を行なっています。
連載中ではありますが、面白いものを思い付いたら連載の合間でも差し込みで投稿する予定です。
その他(2本)
Qiitaでのさくらのアドベントカレンダーに2本記事を投稿しました。
イベント参加などのコミュニティー活動
月に1回程度のペースで各種勉強会への参加など行いました。
その中で、発表を行ったのは以下3つでした。
「さくらインターネット」のDockerホスティング「Arukas」と「Docker Machine」ドライバについてのイベント
4/27 にArukasの発表のついでにdocker-machine-sakuracloudについてお話しさせていただきました。
この時の資料はこちらです。
さくらじまハウス
資料はこちらです。
東京で消耗したくない!」西日本にいながら”IT界隈の人”になったエンジニアと交流する会in北九州
発表の場がちょっと少なかったので、来年はどなたかぜひ招待してください!どこかで喋りたいです!
まとめ
ということで1年を振り返ってみました。
割と濃い開発/執筆活動ができたかなと思います。
来年はもっと喋る機会が増やせればいいなーと思っています。
イベントを企画中の方がいらっしゃいましたらぜひ招待してください!喜んで参加します!
以上です。
「Terraform for さくらのIoT Platform」作りましたー!

この記事はさくらのアドベントカレンダー(その2)の18日目の記事です。
現在12/25ですが、空いていたので投稿させていただきました。
作ったよー!
ということで、TerraformでさくらのIoT Platformを操作するためのプラグイン「Terraform for さくらのIoT Platform」をリリースしました!
詳細は以下のGithubを参照ください。ドキュメントもある程度揃っています。
何ができるの?
さくらのIoT Platformのコントロールパネルでの以下の作業を自動化できます。
- プロジェクトの登録/更新/削除
- モジュールの登録/更新/削除
- 連携サービスの管理
- WebSocket
- Incoming Webhook
- Outgoing Webhook
連携サービスは他にもAWS IoTやMQTT Client、DataStoreなどがあるのですが、
これらはさくらのIoT PlatformのAPIドキュメントが公開され次第実装します。
余談: go言語でAPIクライアントを実装するにあたりgo-swaggerを利用しています。
このため、現在未実装の機能についてはAPIドキュメントにて定義ファイル(yml)が提供された後で実装をする予定です。
使い方は?
準備として、Terraform本体のダウンロード、このプラグインのダウンロード、さくらのIoT PlatformのAPIキーの取得が必要です。
詳しくは以下のページを参照ください。
その後、以下のようなTerraform定義ファイルを作成してterraformコマンドを実行することで、
さくらのIoT Platformの環境構築が一発で行えます。
サンプル
# ------------------------------------------------------------
# プロジェクトの登録
# ------------------------------------------------------------
resource "sakuraiot_project" "project01" {
name = "example project"
}
# ------------------------------------------------------------
# モジュールの登録
# ------------------------------------------------------------
resource "sakuraiot_module" "module01" {
project_id = "${sakuraiot_project.project01.id}"
name = "example module"
register_id = "put-your-register-id" # (要編集)通信モジュール本体に記載されているモジュール登録用ID
register_pass = "pur-your-register-pass" # (要編集)通信モジュール本体に記載されているモジュール登録用パスワード
}
# ------------------------------------------------------------
# 連携サービスとしてOutgoing WebhookとIncoming Webhookを登録
# ------------------------------------------------------------
# Outgoing Webhook
resource "sakuraiot_service_outgoing_webhook" "webhook01" {
project_id = "${sakuraiot_project.project01.id}"
name = "example outgoing webhook"
secret = "secret" # HMAC-SHA1署名用のシークレット
url = "https://your-webhook-server.com/" # Outgoing Webhookの連携先URLを指定
}
# Incoming Webhook
resource "sakuraiot_service_incoming_webhook" "webhook01" {
project_id = "${sakuraiot_project.project01.id}"
name = "example incoming webhook"
secret = "secret" # HMAC-SHA1署名用のシークレット
}
どんな時に使うの?
使い所はズバリ「他サービスとの連携がある環境の構築」です! 例えばさくらのIoT Platformの通信モジュールで受けたデータをArukasで動かす場合、
- 1) Arukas上にWebSocketまたはIncomingWebhookなどの連携サービス用コンテナを起動しておく
- 2) Arukasが割り当てたエンドポイントの情報を元にさくらのIoT Platformで連携サービス(Outgoing-Webhookなど)を登録
といった、複数サービスを行き来しながらの面倒な設定が必要になるのですが、この辺りが一発というのがポイントです。
もちろん、環境をコード化することによって、バージョン管理ができるようになったり、コードレビューが行いやすくなったり、環境の複製/再利用が行いやすくなる、などの様々なメリットを受けることもできます。
試しに複数サービス環境を構築
さくらのIoT PlatformとArukasを連携する環境を構築してみます。
- さくらのIoT Platformにプロジェクトを作成
- さくらのIoT Platformに通信モジュールを1台登録
- さくらのIoT Platformに連携サービスとしてOutgoing-Webhookを登録、通信モジュールからのデータをWebhookでArukas上のコンテナへ送信
- Arukasでは通信内容を表示するだけのエコーサーバーを起動しておく
- Webhookは外部からの不正アクセスを防ぐためにHMAC-SHA1署名用のシークレット文字列を設定する
準備
はじめに以下のページを参考に、Terraform for さくらのIoT PlatformとTerraform for Arukasのインストールを行っておきます。
定義ファイル
Terraform定義ファイルは以下のようになります。
# ------------------------------------------------------------
# HMAC-SHA1署名用のシークレット文字列を定義
# ------------------------------------------------------------
variable secret { default = "secret" }
# ------------------------------------------------------------
# Arukas上にコンテナ起動
# ------------------------------------------------------------
resource "arukas_container" "echo_server" {
name = "sakura_iot_echo"
image = "yamamotofebc/sakura-iot-echo"
ports = {
protocol = "tcp"
number = "8080"
}
environments {
key = "SAKURA_IOT_ECHO_SECRET"
value = "${var.secret}"
}
}
# ------------------------------------------------------------
# さくらのIoT Platformへプロジェクトの登録
# ------------------------------------------------------------
resource "sakuraiot_project" "project01" {
name = "example project"
}
# ------------------------------------------------------------
# さくらのIoT Platformへモジュールの登録
# ------------------------------------------------------------
resource "sakuraiot_module" "module01" {
project_id = "${sakuraiot_project.project01.id}"
name = "example module"
register_id = "put-your-register-id" # (要編集)通信モジュール本体に記載されているモジュール登録用ID
register_pass = "pur-your-register-pass" # (要編集)通信モジュール本体に記載されているモジュール登録用パスワード
}
# ------------------------------------------------------------
# さくらのIoT Platformへ連携サービスとしてOutgoing Webhook登録
# ------------------------------------------------------------
# Outgoing Webhook
resource "sakuraiot_service_outgoing_webhook" "webhook01" {
project_id = "${sakuraiot_project.project01.id}"
name = "example outgoing webhook"
secret = "${var.secret}" # HMAC-SHA1署名用のシークレット
url = "${arukas_container.echo_server.endpoint_full_url}" # Arukasが発行するエンドポイントのURLを参照指定
}
あとはterraform applyするだけで環境構築できちゃいます。便利でしょ?
今後の展望
Terraformの現在のバージョン(2016年12月現在はv0.8.2)はAWS IoTをサポートしていません。
しかしすでにAWS IoTをサポートするためのPullRequestが来ているようですので、近日中に対応されるのではないかと思います。
この辺りも自動化できるようになるとさらに夢が広がりますね!
お願い:複数の通信モジュールをお持ちの方へ
私のお小遣いでは通信モジュールをひとつしか買えませんでした。。。
このため複数の通信モジュールを利用する場合のテストが不十分です。
もし複数のモジュールをお持ちの方がいらっしゃいましたらテストにご協力いただけると助かります!
できれば三つ以上の通信モジュールがあるといいですね!
終わりに
これでさくらのサービスでのTerraformサポートはクラウド、Arukas、IoT Platformと揃いました。 次は、、VPSですね!
|ω・`)チラ
|ω・`)チラチラ
VPSは初期費用がかかったりするのでAPIでの操作は難しいかもしれないですが、
ちらほらAPI欲しいという声を聞きますので、、、
もしさくらのVPSでAPIが公開されたらTerraform対応しますので、ぜひ公開をお待ちしております。
以上です。Terraform for さくらのIoT Platform、ぜひご利用くださいー!!

- 出版社/メーカー: スイッチサイエンス
- メディア: Personal Computers
- 購入: 2人 クリック: 15回
- この商品を含むブログを見る

DevOpsを支えるHashiCorpツール大全 ThinkIT Books
- 作者: 前佛雅人
- 出版社/メーカー: インプレス
- 発売日: 2015/10/22
- メディア: Kindle版
- この商品を含むブログを見る

Terraform: Up and Running; Writing Infrastructure As Code
- 作者: Yevgeniy Brikman
- 出版社/メーカー: Oreilly & Associates Inc
- 発売日: 2017/02/25
- メディア: ペーパーバック
- この商品を含むブログを見る
バルス!さくらのクラウドに物理的に「バルス」を実装してみた

本稿はさくらインターネット Advent Calendar 2016(その1)の19日目の記事です。
前日の記事は@BakeTanukiさんによるKUSANAGI + ウェブアクセラレータという組み合わせについてでした。
この記事の中で拙作「wp-sacloud-webaccel」についてもご紹介いただきました!ありがとうございました!!
さて、今回はさくらのIoT Platformを使ったネタを仕込んでみました。
成功例だけでなく、途中の失敗体験を含めて詰め込んでしまったために長い記事になってしまいました。すいません。
さくらのIoT Platformに取り組む/取り組まれている方の参考になれば幸いです。
言い訳:
筆者はWeb系エンジニアであり、ハードウェアについてはいわゆる「Lチカ」ができる程度です。また、IoTへの取り組みは今回初チャレンジでした。
このため、当記事で作成するものについて実用性や安全性など考慮出来ていませんので、当記事を参考する際はその辺りご注意ください。
はじめに:Terraformプラグイン開発中のお悩み
Advent Calendar1日目の前佛さんの記事「Terraform for さくらのクラウド入門チュートリアル」にてご紹介いただいた、 Terraform for さくらのクラウドというTerraformプラグインについてですが、プラグインを開発している時、実際にさくらのクラウド上にリソースを作成するテストも多いため、こんな悩みがあります。
「さくらのクラウド上にゴミリソースが溜まっていく。。。」
実際にさくらのクラウド上にリソースを作成するようなテストを行う際、 テストの異常終了などでクリーンアップ処理が正常に行われず、ゴミが溜まっていくことがあります。
後でまとめて消しても良いのですが、対象リソースによっては作成数の上限があるため、 こまめに削除しないとテストの実行がままならないというものもあります。 例えばデーターベースアプライアンスは上限数が1のため、リソース作成済みだとテストで新たに作成しようとしてもエラーになってしまいます。
「手動でポチポチ削除するのめんどくさい、、、」
「めんどくさいなー」と思いつつ、さくらのクラウド上のコントロールパネルをポチポチ操作してリソースを削除しようとすると、
- 電源を切ってからじゃないと削除できない
- 他のリソースと接続している場合、切断してからじゃないと削除できない(スイッチとか)
といったことがあり、泣きながら個々のリソースの電源断/切断などを行なってから削除、という作業をしていました。
そこでふと思い浮かんだのが、、、
「バルス」って叫んだら、さくらのクラウド上の全リソース消せないかな?
ということでした。(バルスとは:Wikipedia)
とりあえずやってみよう!ということで、「バルス on さくらのクラウド」を実装してみることにしました。
「バルス」を実行するための構成要素は?
参考サイト:天空の城ラピュタ:Wikipedia
まずはどのような機能/要素が必要なのかの検討のため、「バルス」の動きを以下の図で表してみました。

①飛行石に触れ、 ②「バルス」と叫ぶことで飛行石が反応します。
バルス発動条件には諸説あるようですが、ここでは飛行石に接触した状態で「バルス」と言えば発動すると仮定しています。
続いて飛行石が③呪文が「バルス」かの判定を行います。
飛行石は他にもいくつかの呪文に反応するため、 飛行石自体が音声への反応/認識ができるようになっているものと思われます。
条件を満たすと、飛行石が④ラピュタの中枢にあるコンピューターへ破壊を指示し、
⑤ラピュタの破壊処理が行われ、ラピュタが落ちることになります。
「バルス」を現実世界に落とし込んでみる:その1(失敗編)
先ほど「バルス」の機能/要素を抽出したため、それを現実世界で実現可能な方法に落とし込んでみます。
後述しますが、この方法は結果的に失敗に終わりました。。。
このため、具体的なコードは最低限のもの以外省略しています。

飛行石に触っているかの判定を実装する
バルス発動条件である飛行石に触れるについては①タクトスイッチを押すことで実装できそうです。
「バルス」と言われたかの判定を実装する
飛行石はそれ自体が音声を認識しているようですね。
現実世界においては音声認識モジュールなどを利用すれば実装できそうですが、音声認識モジュールは高価な部品です。
私のようなハードウェアに疎いエンジニアにとって、高価なハードウェアは使いこなせなかった時の心理的ダメージやトラブル時の対応への不安があるので出来るだけ避けたいものです。
複雑な処理はさくらのIoT Platformの通信モジュールを使ってリモートで全部処理しちゃえ!
そこで、今回は「さくらのIoT Platform」の通信モジュールを利用し、 ハードウェアは最小限の動き(AD変換とデータ送信)のみ行うようにすることで安価な部品で事足りるようにしてみました。

さくらのIoT Platformは、公式サイトにて以下のように説明されています。
「さくらのIoT Platform」は、モノとネットワークでデータを送受信するための通信環境、データの保存や処理に必要なシステムを一体で提供するIoTのプラットフォームです。
モノに組み込むための「さくらの通信モジュール」と当社のデータセンターを、安全性を確保するためのLTE閉域網で接続し、ストレージ、データベースなどのバックエンドシステム、外部のクラウドやアプリケーションサービスとAPI連携システムを一体型で統合的に提供します。
さくらの通信モジュールは複雑な設定など必要なく、専用のシールドなどを利用してArduinoに接続すればすぐ使えるようになっています。
Arduinoで利用できるライブラリも提供されているため、簡単なメソッド呼び出しで通信を実現することができそうです。
マイク入力 + AD変換 + データ送信
②「バルス」と叫ぶと、
- (
③の1)マイクで音声を入力、ArduinoでAD変換 - (
③の2)変換したデータを通信モジュールでそのまま送信
という処理を行うようにします。
さくらのIoT Platformは外部との連携用にWebhookが使える
また、さくらのIoT Platformでは通信モジュールからのデータ受信時に外部のシステムと連携するためのOutgoing Webhookが用意されています。
今回はこれを利用して、Arukas上にバルス判定サーバーを立てて、そこにWebhookで通知、各種処理を行うようにします。

ArukasはDockerコンテナのホスティング環境です。まだβ期間ということで無料で使えます。
バルス判定サーバーでの処理
バルス判定サーバーでは以下の処理を行います。
- Webhookで受信したデータをwaveファイルに変換
- 変換したwaveファイルをMicrosoftの提供するAzure Cognitive Servicesを利用してテキストに変換
- テキストに「バルス」という文字が含まれるか判定
waveファイルは非常に単純なファイルフォーマットのため、簡単なバイナリーの操作(ヘッダの設定)で作成することができます。
今回はWebhookの受信処理やバイナリー操作を行うため、実装にはGo言語を採用しました。
さくらのクラウド上のリソース全消し処理
「バルス」判定がOKだった場合はさくらのクラウド上のリソース全消しを行います。
これはさくらのクラウドAPIやAPIライブラリを利用すればすぐに実装できますね。
バルス判定サーバーをGo言語で書いたため、こちらもGo言語で実装することとしました。
ここまでの処理をまとめると以下のような感じになります。

では後はこれらが本当に実現可能かプロトタイピングしながら確認してみましょう。
プロトタイピングしてみる!
これらの機能要素が本当に実現できるのか、小分けにして実装を試してみました。
マイクの入力を扱う
まずはマイクとArduinoでどこまで音声が拾えるのか試してみました。
マイクは1個240円で売っていたノーブランド品のMAX4466を調達しました。
(2016年12月現在はノーブランドのものは品切れのようですが、スイッチサイエンスさんでも同等品を扱っているようでした)

- 出版社/メーカー: スイッチサイエンス
- メディア: エレクトロニクス
- この商品を含むブログを見る
Arduinoは永久保証の付いているスイッチサイエンスさんの品を選びました。
また、安価なArduino UNO互換品もありましたので、万が一に備えて予備として購入しておきました。
- 出版社/メーカー: スイッチサイエンス
- メディア: Personal Computers
- 購入: 2人 クリック: 15回
- この商品を含むブログを見る
![HiLetgo NEWバーション UNO R3 ATmega328P USB CH340G Arduinoと互換性 + USB ケーブル [並行輸入品]](https://images-fe.ssl-images-amazon.com/images/I/51g5b2MOosL._SL160_.jpg "HiLetgo NEWバーション UNO R3 ATmega328P USB CH340G Arduinoと互換性 + USB ケーブル [並行輸入品]")
HiLetgo NEWバーション UNO R3 ATmega328P USB CH340G Arduinoと互換性 + USB ケーブル [並行輸入品]
- 出版社/メーカー: HiLetgo
- メディア: おもちゃ&ホビー
- この商品を含むブログを見る
こちらのサイトを参考に、マイク+Arduinoと手元のMacをUSB接続し、Processingでwaveファイルを作成してみました。
以下の流れで、マイクからの入力をシリアル接続(USB)経由で手元のMacに送ってwaveファイル作成を行なっています。
- (1) 手元のMacにてProcessingを起動
- (2) Arduinoにてマイク(MAX4466)からのアナログ入力を取得
- (3) 取得した値はArduinoからシリアル出力
- (4) Processingにてシリアル入力を読みwaveファイルを作成

結果、多少のノイズは乗っているものの、十分に声が判定できるwaveファイルが出来ました。
必要があればバルス判定サーバー上でwaveファイルに対して波形編集を行うことで音圧調整やノイズ除去などを行うようにします。
(なお、参考サイトのコードだとサンプリングレートが足りず、Arduinoのレジスタ設定でanalogRead()の速度アップを行ったりしました。 )
Azure Cognitive Servicesで音声(wave)からテキストへ変換してみる
Azure Cognitive Servicesとはマイクロソフトが提供している、AIを利用して様々な「モノゴトを認識させる」ためのAPI群です。

ここでは、先ほど作成した音声ファイルをAzure Cognitive ServicesのAPIを利用してテキストへ変換してみます。
REST形式でAPIを呼び出してみる
以下のドキュメントを参考に、REST形式でAPIを呼び出してみました。
Azure Cognitive Services(Bing speech API)ドキュメント
- Azure側の準備
本稿では詳細な手順は省略しますが、APIを利用するには、AzureポータルにてCognitive Services APIsを有効化しておく必要があります。
こちらのサイトなどを参考に準備し、
APIの呼び出しに必要なキーを発行しておきましょう。
curlコマンドでAPIを呼び出し
APIの挙動を確かめるため、以下のようなシェルスクリプトでcurlコマンドを利用してAPIを呼び出してみました。
対象の音声ファイルはカレントディレクトリにtest.wavという名前で配置しています。
#!/bin/sh # 認証トークンの取得 curl -X POST -H "Ocp-Apim-Subscription-Key:[Azureポータルで取得したAPIキー]" -H "Content-Length:0" https://api.cognitive.microsoft.com/sts/v1.0/issueToken > test_token # API呼び出し VERSION=3.0 REQUEST_ID=`uuidgen` APP_ID=D4D52672-91D7-4C74-8AD8-42B1D98141A5 FORMAT=json LOCALE=ja-JP INSTANCE_ID=`uuidgen` DEVICE=test curl -v -L -X POST -H "Authorization: Bearer `cat test_token`" \ -H "Content-Type: audio/wav; samplerate=8192" \ --data-binary @test.wav \ -m 30 \ "https://speech.platform.bing.com/recognize?version=$VERSION&requestid=$REQUEST_ID&appID=$APP_ID&format=$FORMAT&locale=$LOCALE&device.os=$DEVICE&scenarios=ulm&instanceid=$INSTANCE_ID"
呼び出しが成功すると、以下のようなJSONが取得できます。
{
"header": {
"lexical": "バルス",
"name": "バルス",
"properties": {
"HIGHCONF": "1",
"requestid": "xxxxxxxx-nnnn-xxxx-nnnn-xxxxxxxx10xx"
},
"scenario": "ulm",
"status": "success"
},
"results": [
{
"confidence": "0.8237563",
"lexical": "バルス",
"name": "バルス",
"properties": {
"HIGHCONF": "1"
},
"scenario": "ulm"
}
],
"version": "3.0"
}
無事認識されているようですね!
これと同等の処理をバルス判定サーバー上に実装すれば良さそうです。
さくらのIoT Platformとの連携用にGo言語でWebhook受信サーバーを立てる
続いて音声データをさくらのIoT Platformから受け取るために、Go言語でWebhook受信用サーバーを実装してみました。
さくらのIoT PlatformとのWebhookやりとり部分は今後も汎用的に使いそうなので「sakura-iot-go」という名前でライブラリとして切り出してみました。
このライブラリを利用すれば、以下のようなコードでさくらのIoT PlatformからのWebhook受信サーバーを実装できます。
package main import ( "fmt" sakura "github.com/yamamoto-febc/sakura-iot-go" "net/http" ) func main() { // パス"/"で待ち受け http.Handle("/", &sakura.WebhookHandler{ // IoT Platformの管理画面(Outgoing Webhook)で設定したSecret Secret: "[put your secret]", HandleFunc: func(p sakura.Payload) { // [ここにWebhook 受信時の処理を書く] }, }) // ポート番号8080で待ち受け http.ListenAndServe(":8080", nil) }
これで無事にIoT PlatformからのWebhookを受信できました。
バルス判定サーバーはこのライブラリを利用して実装するようにします。
Arukasで動かすためにDockerイメージ化
Arukas上で動かすためには、DockerイメージをDockerHubで公開しておく必要があります。
そこで、Go言語で実装したバルス判定サーバーを実行するDockerイメージを作成し公開することにします。
Dockerfileの作成
Dockerfileは以下のようになります。
Go言語でアプリケーションを実装すると、実行ファイル1つにパッケージングすることができるので、Dockerイメージ化は非常に楽です。
実行ファイルをADDしてENTRYPOINTに指定するだけ済んじゃいます。非常にシンプルですね。
FROM alpine:3.4 LABEL maintainer="Kazumichi Yamamoto <yamamoto.febc@gmail.com>" MAINTAINER Kazumichi Yamamoto <yamamoto.febc@gmail.com> RUN set -x && apk add --no-cache --update ca-certificates ADD 作成した実行ファイル /bin/ ENTRYPOINT ["/bin/作成した実行ファイル"]
いよいよ通信モジュールを繋いでみる

次に実際に通信モジュールを繋いでさくらのIoT Platform経由で音声データを送ってみます。
音声データのサイズはどれくらい?
今回は1秒間の音声データを取得することにします。
音声認識をするためには、サンプリングレート8000程度は欲しいところです。
1回のサンプリング(Arduino上でanalogRead()を実行する)で1byte(0〜255)の値を取得するようにすると、
1秒 × 8000回 × 1byte = およそ8Kbyte となります。
バッファが足りない、、、!?
通信モジュールが1回で送信できるデータには限りがあります。 (通信モジュールβ版ではバッファ/データキューは32個とのことでした。参考:データシート)
このため、溢れたデータはArduino上のメモリなどのバッファに置いておかないと消失してしまいます。
そして今回利用しているArduino(UNO)には利用可能なメモリとして2KbyteのSRAM、1KbyteのEEPROMしかありません。
このままではおよそ8Kbyteある音声データが溢れて消えてしまいます。
このため、バッファリング用のSRAMモジュール(32Kbyte)を個別に追加して対応しています。

- 出版社/メーカー: スイッチサイエンス
- メディア: エレクトロニクス
- この商品を含むブログを見る
音声データを送信してみる
タクトスイッチを押している間、マイクからの入力を取り込むことにします。
入力データは一旦バッファに置いて、順次通信モジュールで送信してみました。
ここで問題が!!!
ここまでは順調だったのですが、とうとう問題が発生してしまいました。その問題とは、、、
- 通信モジュールから
CMD_ERROR_BUSYというエラーが返ってくる - 1秒分のデータを送信完了するまで40秒以上かかる
という2つです。40秒では支度できないということですね。困りました。。。
何が悪いのか?
Arduino側で、以下のようなコードでデータ送信を行なっていました。
void flushSamples(){ // Tx Queue uint8_t ret; uint8_t avail; uint8_t queued; uint8_t buf[8] = {0}; // SRAMに置いたデータを順次処理する for(int i = 0;i < MAX_DATA_LEN;i++){ // バッファ(8byte)にデータが溜まったら通信モジュールのキューに入れる if (i > 0 && i % 8 == 0){ ret = sakuraio.enqueueTx(DATA_CHANNEL, buf); // キューに入れたらバッファをクリア memset(buf , 0 , sizeof(buf)); } buf[i%8] = (uint8_t)data.read(i); // 通信モジュールのキューの現在サイズを取得 sakuraio.getTxQueueLength(&avail, &queued); if(queued >= 30){ // 30個キューに溜まったら送信実施 ret = sakuraio.send(); // [ここでCMD_ERROR_BUSYというエラーが頻発] while(ret != 1){ // send()が成功するまでインターバルを入れながらループする delay(500); digitalWrite(STATUS_LED_PIN, HIGH); delay(500); digitalWrite(STATUS_LED_PIN, LOW); ret = sakuraio.send(); Serial.print("."); if (ret == 1){ Serial.println("Done."); } } } } // コントロール用のチャンネルに終了コードを入れておく sakuraio.enqueueTx(CONTROL_CHANNEL, END_CODE); sakuraio.send(); // キューに残っているデータを送信 }
とにかく短時間で大量のデータを送る必要があるのがネックなようです。
CMD_ERROR_BUSYとなったらインターバルを入れているため、さらに時間がかかることになります。。。
データ量を減らせばなんとかなるか?
データ量を減らしつつ、「バルス」を送信できないか、、、
と悩んでいると、ふと違うやり方を思いつきました。
そうだ!モールス信号があるじゃないか!
音声入力の代わりにモールス信号で「バルス」という文字を入力してもらうようにすればデータ量を減らせそうです。
しかもモールス信号の復号程度ならArduinoだけで処理ができるため、飛行石自体が「バルス」という言われたか認識するという元の処理に近い形が取れそうです。
ということで設計から見直して再チャレンジしてみました。
「バルス」を現実世界に落とし込んでみる:その2(成功編)

シンプル!非常に単純になりました。
Arduinoで①モールス信号入力を処理します。信号の入力にはタクトスイッチを利用することにしました。
入力されたモールス信号が「バルス」だった場合は通信モジュールで②データ送信を行います。
サーバー側はデータが到着したらリソース全消し処理を呼び出すだけです。
いけそう!実装してみる!
ということで、以下のような回路にしてみました。
Arduino + LEDが数個 + 入力用のタクトスイッチという非常にシンプルな構成です。

入力は「バルス」の英語表現である「balus」をモールス信号にて行います。
注:英語表記はbalus以外にも諸説あるようです。
モールス信号で1文字正しく入力するごとにLEDを点灯させるようにしました。
こんな感じに仕上がりました。
上から見た写真:

Arduinoのスケッチはこんな感じです。(抜粋)
#include <SakuraIO.h> #include "constants.h" #include "morse_code.h" // モールス信号で入力するキーワード[ l = long , s = short] String magicalSpell = "balus"; // [ lsss , sl , slss , ssl , sss] const byte spellLen = 5; // モールス信号入力用バッファ String inputBuf[spellLen]; // バッファの現在位置 byte bufIndex = 0; // タイマー(スイッチON開始時刻、スイッチOFF開始時刻、最終操作時刻) unsigned long startTime , endTime , silentTime; // モールス信号での文字入力ごとに点灯させるLEDの配列 int LEDs[] = {LED1,LED2,LED3,LED4,LED5}; // 文字区切り連続入力防止用 bool isSpacePushed = false; // バルス処理中フラグ bool isSpellCasting = false; // さくらの通信モジュール(I2C) SakuraIO_I2C sakuraio; // ------------------------------------------------------------------- void setup(){ Serial.begin(9600); // Arduino各ピンの入出力モード設定 setupPinMode(); // さくらの通信モジュールがオンラインなるまで待つ connecToSakuraIoT(); // 初期化完了をシリアル出力でお知らせ printInitMessage(magicalSpell); // 初期化完了をLEDでお知らせ blinkLED(BLINK_INIT); } void loop(){ // バルス処理呼び出し中か? if (isSpellCasting){ checkSakuraResponse(); return; } // 無操作になって一定時間経過したら文字の区切りとする if (isMorseSilent()){ Serial.println("space"); pushMorse(CODE_SILENT); isSpacePushed = true; } if (digitalRead(SW) == SW_ON){ // タクトスイッチが押されている digitalWrite(LED_STATUS , HIGH); if (startTime == 0) { startTime = millis(); // スイッチONにした時刻 silentTime = 0; isSpacePushed = false; } }else{ // タクトスイッチを離した digitalWrite(LED_STATUS , LOW); if (startTime > 0 && endTime == 0) { endTime = millis(); // スイッチをOFFにした時刻 isSpacePushed = false; } } // タクトスイッチのON/OFF両方の時刻から信号の長短(ツー/トン)を判定 if (startTime > 0 && endTime > 0){ if ( isMorseShort() ){ // short(トン)か? // 入力バッファへプッシュ Serial.println("short"); pushMorse(CODE_SHORT); }else if ( isMorseLong() ){ // long(ツー)か? // 入力バッファへプッシュ Serial.println("long"); pushMorse(CODE_LONG); } //判定したら時刻をクリア resetStartTime(); // 無操作時間の開始時刻を保持しておく silentTime = millis(); } // 無操作時間が閾値(RESET_DUR)を超えたら、それまでの入力をリセット if (silentTime > 0){ if ( millis() - silentTime > RESET_DUR) { resetAll(); blinkLED(BLINK_TIMER_RESET); } } } // 入力バッファにモールス信号を登録 void pushMorse(String code){ if (code.equals(CODE_SHORT)){ inputBuf[bufIndex].concat(CODE_SHORT); }else if (code.equals(CODE_LONG)){ inputBuf[bufIndex].concat(CODE_LONG); }else if (code.equals(CODE_SILENT)){ // 単語区切りを受信した。キーワードの文字数までは1文字づつ正答確認を行う。 if (bufIndex < magicalSpell.length()-1){ // 入力されたモールス信号(1文字分)をシリアル出力 printInputedMorseCode(bufIndex, inputBuf[bufIndex]); if (isInputMorseOK(bufIndex)) { // 正しい(キーワードと合致した)モールス信号が入力されたか? digitalWrite(LEDs[bufIndex] , HIGH); bufIndex++; }else{ // 間違ったコードが入力されたため、メッセージを表示して入力リセット printWrongInputMessage(); resetAll(); blinkLED(BLINK_NOT_CASTED); return; } }else{ // === 入力信号が「バルス」だった場合の処理 === // 入力OKメッセージをシリアル出力 printOKInputMessage(magicalSpell); blinkLED(BLINK_CASTED); sendToSakuraIoT(); } } } // さくらのIoT Platformへ指示(処理開始コード)を送信する void sendToSakuraIoT(){ sakuraio.enqueueTx((uint8_t)SAKURA_IOT_CHANNEL, (uint32_t)SAKURA_IOT_START_CODE); uint8_t ret = sakuraio.send(); if (ret == CMD_ERROR_NONE) { // エラーがなかったら呼び出し中フラグを立てる isSpellCasting = true; } } // さくらのIoT Platformからの応答をチェック void checkSakuraResponse(){ uint8_t avail , queued; // 受信キューの状態を問い合わせ(現在利用可能なキュー長、キューの中のデータ数) sakuraio.getRxQueueLength(&avail, &queued); // キューにデータがあれば if (queued > 0) { uint8_t channel; // チャンネル uint8_t type; // データのタイプ[i,I,l,L,f,d,b] uint8_t values[8]; // データ int64_t offset; // オフセット uint8_t ret = ret = sakuraio.dequeueRx(&channel, &type, values, &offset); if (ret == CMD_ERROR_NONE) { // エラーがなかったらデータの確認 if (channel == SAKURA_IOT_CHANNEL){ if (values[0] == SAKURA_IOT_END_CODE){ // 正常終了コードを受信 blinkLED(BLINK_NORMAL_END); isSpellCasting = false; return; }else if (values[0] == SAKURA_IOT_ERROR_CODE){ // エラーコードを受信 blinkLED(BLINK_ERROR_END); isSpellCasting = false; return; } // 未知の値は無視 } // 未知のチャンネルでの受信は無視 } } blinkLED(BLINK_WAITING_RESPONSE); }
サーバー側実装
後はサーバー側の実装ですが、こちらはさくらのクラウドAPIを順次呼び出して削除処理を行うだけです。
せっかくなので先ほどの「sakura-iot-go」を利用するために、Go言語で実装してみました。
なお、この処理は汎用的に使えそうなのでGitHubで独立したリポジトリとして公開しています。
実行!
では順番に実行していきます。
ArukasやさくらのIoT Platformの設定を適切に行なった上で、モールス信号で「balus」と入力してみましょう!
やった!無事動きました!
さくらのクラウドのコントロールパネルを見ると、無事リソースが削除されていることも確認できました!
9Vの電池をつなげて動かすこともできますので、外出先でも「バルス」できますね!
まとめ
ということで、さくらのIoT Platformを使って悪ふざけをしてみましたw
今回の処理内容について
今回の処理の流れは
- 信号の入力があったら
- さくらのIoT Platformを通じて通信し
- サーバー上で削除処理を実行
というものですが、ちょっとしたアイディアで色々な応用ができそうですね。
例えばサーバー上で商品の注文処理を実装すれば Amazon Dashボタンのような動きをさせることもできます。
夢が広がりますね!
失敗/設計変更について
最初の設計では、通信時のBUSYエラーや通信時間が結構かかるという辺りで躓いてしまいました。
大量のデータを短期間で送るということがそもそも通信モジュールの特性とマッチしてないように感じました。
結局、何がおきているのか/何が原因でダメなのかがわからず、設計変更で逃げるような対応となりました。
ハードウェアの絡む問題が発生した際はやはり詳しい専門家のアドバイスが欲しいなーと思いました。
(今回みたいにそもそも設計がダメとかあるだろうし)
とはいえ、さくらのIoT Platformならお試しするための敷居が低いため、まずはプロトタイプで検証という動き方をするのがいいのかなとも思いました。
感想
今回IoT初挑戦だったのですが、めんどくさそうな通信や連携の部分が思ったよりすんなりと書けたことが驚きでした。
電子工作=Lチカというレベルでも、さくらのIoT Platformを使うことで簡単に通信/外部との連携処理まで実装でき、しかもセキュリティーやその後のスケールアップはプラットフォーム側に任せてしまって関心のあるサービスの実装に注力できるというのはいいなーと思いました。
おまけ:今回の副産物
今回のものは悪ふざけで作成したものですが、そんな中でも副産物として実用できるライブラリが数個収穫できましたので以下にまとめておきます。
ついでに今回使ったコードについても全部(ダメだった方も)公開しています。
失敗した方がどんなソースだったのか気になる方は参照してみてください。
ライブラリ
今回のコード(失敗バージョン)
今回のコード(成功バージョン)
以上です。ここまでお読みいただきありがとうございました。
最近の活動について
気づいたら4年ぶりのブログ投稿です。
この間活動していなかったわけではないのですが、、
- 業務にて古い技術を採用せざるをえない事情があり、積極的に技術関連のアウトプットをするモチベーションが低下してた
- Qiitaに投稿するようになった
などにより、こちらには投稿できてませんでした。 最近はまた活動再開してきてますのでぼちぼち投稿していきたいです。
最近作ったもの紹介
Docker Machine さくらのクラウド
DockerMachineのさくらのクラウド用ドライバを作りました。
Terraform for さくらのクラウド
Terraformのさくらのクラウド用プロバイダを作りました。
紹介記事では概要や実際の設定メモ程度しか書いてないので ぼちぼちちゃんとしたスタートガイドを書く予定です。
libsacloud
さくらのクラウドAPIのGo言語用ライブラリを作りました。 saklientを参考にしていますが、フルスクラッチで開発してます。
上記のTerraform for さくらのクラウドでも利用しています。
最近の活動その他
他にもAutoScalingのサンプル記事書いたり、 カンファレンス/勉強会に参加したりしてます。
直近だとPHPカンファレンス福岡に参加しました。
今後の活動
未定ですが、もう少しTerraform for さくらのクラウドの ドキュメントを整備しておきたいですね。
本日は以上です。
")
プログラミング言語Go (ADDISON-WESLEY PROFESSIONAL COMPUTING SERIES)
- 作者: Alan A.A. Donovan,Brian W. Kernighan,柴田芳樹
- 出版社/メーカー: 丸善出版
- 発売日: 2016/06/20
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (2件) を見る

プログラマのためのDocker教科書 インフラの基礎知識&コードによる環境構築の自動化
- 作者: 阿佐志保,山田祥寛
- 出版社/メーカー: 翔泳社
- 発売日: 2015/11/20
- メディア: 大型本
- この商品を含むブログ (3件) を見る
DevOpsを支えるHashiCorpツール大全 ThinkIT Books
- 作者: 前佛雅人
- 出版社/メーカー: インプレス
- 発売日: 2015/10/22
- メディア: Kindle版
- この商品を含むブログを見る