AWSの料金をSlackに通知するLambdaをRustに移植してみた
はじめに
お仕事でAWS Lambdaを使って実装する処理が出てきました。
この処理はクリティカルな部分ではない、補助的な処理だったため日頃から使う機会を窺っていたRustで実装してみることにしました。
まずはRust+Lambdaの肩慣らしのために、プライベートなアカウントで利用している毎日のAWSの料金をSlackに通知する処理をRustに移植してみることにしました。
元ネタ: LambdaでAWSの料金を毎日Slackに通知する(Python3) qiita.com
今回移植したコード一式はこちらにおきました。 github.com
Rustへの移植
基本的には元のPythonの処理をそのまま移植していく方針としました。
関数の作成やIAMロールへのポリシーのアタッチなども元ネタとほぼ同じやり方にしています。
関数の作成はこんな感じでカスタムランタイムを選択しておきます。アーキテクチャはx86_64にしました。
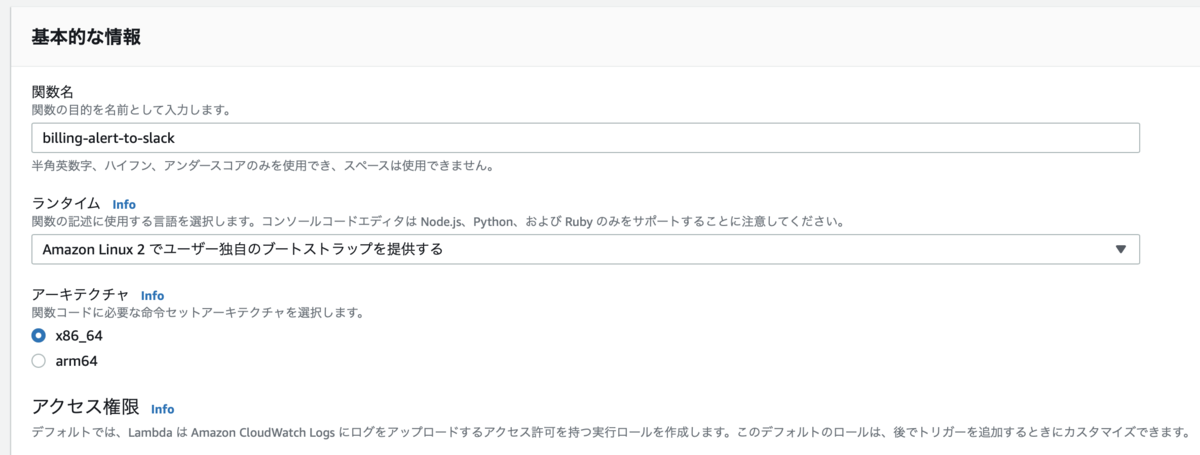
コードはローカルでzipファイルを作ってアップロードする形にします。

プロジェクト構成
全体的な構成はこんな感じにしました。
$ tree . . ├── Cargo.lock ├── Cargo.toml ├── Makefile ├── bootstrap // エントリーポイント用のバイナリクレート │ ├── Cargo.toml │ └── src │ └── main.rs └── event.json // テスト用のダミーインプット
Lambdaのカスタムランタイムの仕様としてエントリーポイントはbootstrapという実行可能ファイルにする必要があるとのことでした。
docs.aws.amazon.com
今回はCargoのワークスペースを作成しその中にバイナリクレートとしてbootstrapというクレートを配置する形にしました。
ビルド〜zip作成
こちらに従ってビルドしていくようなMakefileを用意しました。
あらかじめrustup target add x86_64-unknown-linux-gnuしておいた上でmake zipするとDocker上でクロスコンパイル〜zip作成が行われるようになっています。
Makefileはこんな感じです。
DOCKER_PLATFORM ?= linux/amd64 RUST_VERSION ?= 1.57 RUST_ARCH ?= x86_64-unknown-linux-gnu DEPS ?= bootstrap/src/*.rs bootstrap/Cargo.toml Cargo.toml Cargo.lock RELEASE_DIR := ${PWD}/target/${RUST_ARCH}/release TARGET_BIN := ${RELEASE_DIR}/bootstrap TARGET_ZIP := lambda.zip build: cargo build --release --target ${RUST_ARCH} .PHONY: buildx buildx: $(TARGET_BIN) $(TARGET_BIN): $(DEPS) docker run -it --rm --platform ${DOCKER_PLATFORM} \ -v "$${PWD}":/usr/src/myapp -w /usr/src/myapp rust:${RUST_VERSION} \ make build .PHONY: zip zip: $(TARGET_ZIP) $(TARGET_ZIP): $(TARGET_BIN) zip -j "$(TARGET_ZIP)" "$(TARGET_BIN)"
PythonからRustへの移植
移植したコード全体はこちらです。 github.com
ロギング
pythonではloggerをこんな感じで用意していました。
logger = logging.getLogger() logger.setLevel(logging.INFO)
print!やprintln!でも良かったのですが、ログレベルをサポートするためにこちらを使うことにしました。
こんな感じで使います。
// 初期化 simplelog::SimpleLogger::init(LevelFilter::Info, Config::default()).unwrap(); // ログ出力 log::info!("hello {}", "world");
AWS SDK
boto3の代わりにrusotoを使います。
⚠️ Rusoto is in maintenance mode. ⚠️と書かれてますが今回は気にせず使うことにしました。
こんな感じになります。
let client = CloudWatchClient::new(Region::UsEast1); client.get_metric_statistics(GetMetricStatisticsInput { namespace: String::from("AWS/Billing"), metric_name: String::from("EstimatedCharges"), dimensions: Some(vec![Dimension { name: String::from("Currency"), value: String::from("USD"), }]), start_time: (Utc::today().and_hms(0, 0, 0) - Duration::days(1)) .format("%+") .to_string(), end_time: Utc::today().and_hms(0, 0, 0).format("%+").to_string(), period: 86400, statistics: Some(vec![String::from("Maximum")]), ..GetMetricStatisticsInput::default() }).await
SlackへのPost(WebHook)
requestsの代わりにreqwestを使います。
こんな感じにになりました。
let client = reqwest::Client::new(); client.post(slack_post_url.to_string()).body(body.to_string()).send().await?;
実行!
ということでmake zipし、作成されるzipファイルをマネジメントコンソールからアップロードしテスト実行してみます。

いい感じですね!
残課題
Dockerでのビルド周りが遅いのは要改善です。
また、LocalStackやlambci/lambdaを用いてローカル実行できるようにしてあげる必要もあると思います。
この辺は追々対応していきます。
ということで今回は以上です。
![実践Rust入門 [言語仕様から開発手法まで]](https://m.media-amazon.com/images/I/51t+hDKJOvL._SL500_.jpg "実践Rust入門 [言語仕様から開発手法まで]")

連携できるアプリは3000個以上!さくらのクラウド+iPaaS(Zapier)で広がる世界

はじめに
最近Zapierを触る機会がありました。 これまでiPaaS的なことをやるときにIFTTTのPro版を使っていたのですが、Zapierを試してみるとなかなか使い勝手が良かったので試した内容を残しておきます。
Zapierとは
ZapierとはいわゆるiPaaSで、さまざまなWebアプリケーションを統合/自動化してくれます。
こちらの動画を見ると、カタカナだと「ザピアー」と読むのが近いですかね。
youtu.be
サポートしているappは3000を超えており、よく使うようなアプリ(GmailやTrello、Slack/Discord、スプレッドシートなど)にきちんと対応しています。

対応していないアプリについては、アプリ側がWeb APIを提供していれば自分でIntegrationを作成することで対応させることができます。
IntegrationはGUI上でポチポチ(Zapier Platform UI) またはCLI経由で作成することが可能です。
BASIC認証にも対応してますのでさくらのクラウドにも対応できそうです。
Zapier+さくらのクラウドで何ができるの?
Actions
ZapierからAPIを叩けますので、何かをトリガーにAPIを叩くことが可能です。
この記事では例としてDiscordに書き込んだらサーバを起動するという仕組みを作ってみます。
Triggers
また、ZapierにはAPIなどでデータをポーリングしてデータが追加/変更されたことを検知する仕組みが備わっています。 例えば
- 新しいサーバが追加されたら何かをする
- サーバの起動状態(起動 or シャットダウン)が変わったら何かをする
- DNSレコードが追加されたら何かをする
みたいなことが可能です。 この記事ではサーバの起動状態が変わったことを検知してみます。
Actionsを試してみる
まず動きを理解しやすいActionsから取り組んでみます。
Actionとは何かしらのトリガー(Gmailでのメール受信とかSlackでのメッセージ受信とかWebhookとか)を受けた時に実行される処理の事です。
何かしらのトリガーを用意した上でさくらのクラウドAPIを呼ぶ処理を実装してみます。
トリガーの準備(Discord)
トリガーはなんでも良いのですが、今回は手軽に試せるようにDiscordの特定チャンネルに書き込みがあったら何かするようにしてみます。 Discordのサーバを用意し、専用のチャンネルを用意します。
今回チャンネル名はzapier_testとしました。

Integrationの作成
こちらからIntegrationの作成を開始します。 (アカウントがない場合は作っておいてください。無料プランでも問題ないです)
NameやDescriptionなどを適当に入力していきます。
下の方のIntended AudienceとRoleは以下のようにしてください。
Intended Audience: PrivateRole:I have no affiliation with __
Intended Audienceは公開範囲です。Publicにしたい場合にはいくつかの条件をクリアする必要があります。(詳細はToSを要確認)
Roleは統合対象のアプリ(今回はさくらのクラウド)との関係(雇用関係があるか?)です。作成対象のIntegrationを公式ディレクトリで公開したい場合に設定が必要です。
今回はI have no affiliation with __(無関係)を選びます。

Authenticationの作成
次にアクションで使う認証情報を指定します。この設定は後ほどトリガーでも利用可能です。
画面左のメニューからAuthenticationを選び、Basic Authを選択してから保存します。

次に認証情報のテスト用のURLを指定します。 さくらのクラウドには認証情報を確認するAPIが用意されていますのでこちらを利用します。
GET:https://secure.sakura.ad.jp/cloud/zone/is1a/api/cloud/1.1/auth-statusと入力して保存してください。

テスト用のAPIキーの登録
続いて認証情報のテストを行います。
まずはAPIキーを登録します。Sign in to ...というボタンをクリックするとポップアップ画面が表示されますのでさくらのクラウドのAPIキーを入力します。


登録したらTest Authenticationをクリックして動作確認しておきます。

Actionの作成
次にアクションを作成します。 今回はサーバの電源をONにする処理を実装してみます。
左のメニューからActionsを選びAdd Actionボタンから新規作成画面を開きます。
Settingsタブは以下のように入力します。

入力後は一度保存してください。
Inputs
次にInput Designerタブでこのアクションを実行するのに必要な入力項目(Input)を指定していきます。
今回は操作対象のサーバが属するゾーンとサーバのIDを指定可能にします。
手作業で入力すると大変なので、ゾーンとサーバをドロップボックスで選べるようにします。
こんな感じの動きになります。

Zone
まずはZoneを追加します。Input Fieldを追加します。

KeyとLabelにはZoneと入力してください


Dropdown Sourceには以下のJSONを入力します。
[ { "sample": "is1a", "value": "is1a", "label": "石狩第1ゾーン" }, { "sample": "is1b", "value": "is1b", "label": "石狩第2ゾーン" }, { "sample": "tk1a", "value": "tk1a", "label": "東京第1ゾーン" }, { "sample": "tk1b", "value": "tk1b", "label": "東京第2ゾーン" }, { "sample": "tk1v", "value": "tk1v", "label": "Sandbox" } ]
サーバのID
次にサーバのIDを指定可能にします。 Dynamic Fieldを追加し、コードは以下をコピペします。
const options = { url: 'https://secure.sakura.ad.jp/cloud/zone/{{bundle.inputData.Zone}}/api/cloud/1.1/server', method: 'GET' } return z.request(options) .then((response) => { response.throwForStatus(); const results = response.json; return { key: 'ServerID', label: "ServerID", required: true, choices: results.Servers.map(v => { return { label: v.Name , sample: v.Name, value: v.ID } }) } });
{{bundle.inputData.Zone}}で前に指定したZoneのinputの値を参照できます。
その後APIの戻り値からZapierが理解できる形に変換して返しています。
参考: How to add Dynamic and Custom Fields
API設定
さくらのクラウドAPIを呼ぶ設定をしていきます。
API Configurationタブを開きStep1に入力していきます。
以下のように入力してください。
- メソッド:
PUT - URL:
https://secure.sakura.ad.jp/cloud/zone/{{bundle.inputData.Zone}}/api/cloud/1.1/server/{{bundle.inputData.ServerID}}/power
先ほども出てきた{{...}}という記法でInputを参照してURLを組み立てます。
保存したらStep2でテストしてみます。
API設定のテスト
Configure Test Dataでは定義しておいたInputを入力できるのですが、Dynamic Fieldにはうまく対応していないためRawを選んで直接入力します。
以下のJSONを入力します。(ゾーンとIDは各自の値に置き換えてください)
{ "inputData": { "Zone": "is1a", "ServerID": "111111111111" } }

うまくいけば以下の表示が出るはずです。

Integrationを試す
これでActionが出来ましたのでIntegrationを試してみましょう。
ダッシュボードからCreate Zapボタンを押しましょう。
画面左上の入力欄でZap名を指定し、App EventではDiscordを検索して選択します。

Discordトリガーの設定
次にTrigger TypeをNew Message Posted to Channelにします。

次にDiscordにサインインするように促されます(初回のみ)

Discord側で権限の確認画面が出ますのでサーバを間違えないように選択してから許可を出します。

次に対象のチャンネルを選択します。

作成したActionの設定
次に作成したActionの設定を行います。 App Eventに作成したアクションの名前を入れて検索&選択します。

Eventとして先ほど作成したActionが選べるはずです。

Actionを選んだらパラメータを指定します。 Zoneを選んだら該当ゾーンにあるサーバがドロップダウンで選択できるようになります。

テストはスキップしても構いませんしここでテストしてもOKです。

最後にTurn on ZapをクリックしてZapを有効化しておきます。
動作確認
最後に動作確認してみます。Discordの指定チャンネルになんでも良いので書き込みしてみます。 サーバが起動したら成功です!
お好みでサーバ起動後に通知を出したり、Discordで任意の文字列が書き込まれたら起動するように修正するとグッと実用的になるかと思います。
例: Discordからの書き込み内に起動という文字が存在している場合だけ処理するようにフィルターを設定

Triggersでさくらのクラウド上のリソースの変更を検知してみる
続いてTriggersを試してみます。
ZapierのTriggers
Zapierは以下2つのトリガーをサポートしています。
- REST Hook Trigger
- Polling Trigger
REST Hook Trigger
REST Hook Triggerは統合対象のアプリケーションの側から通知をしてもらう方式です。
統合対象のアプリケーション側でデータが増えたり更新された時にZapierに通知することで即時トリガーすることが可能です。
ただし、統合対象のアプリケーション側がREST Hooksに対応している必要があります。
残念ながらさくらのクラウドはREST Hooksに対応していませんので次のPolling Triggerを使用する必要があります。
Polling Trigger
Polling Triggerはその名の通りポーリングでデータの追加/更新を検知する方式です。
統合対象からAPIでデータを定期的に取得し、追加や更新があったかをZapier側で判断してトリガーしてくれます。
ただし、APIでデータを取得する際にデータをZapierが理解できる形に変換しておく必要があります。 platform.zapier.com
具体的には、
- 配列
- 各要素は
idというフィールドを持つオブジェクト - 作成/更新時間の逆順でソートされていること(新しいデータがより前にあること)
という形式である必要があります。
例:
[ { id: 2, name: "example2"}, { id: 1, name: "example1"} ]
例えば1回目のAPIコールで上記のデータを返したとします。Zapierはこれを保持しており、次回リクエスト時の結果と比較して追加/変更を検知してくれます。
例:
[ { id: 3, name: "example3"}, { id: 2, name: "example2"}, { id: 1, name: "example1"} ]
というデータが来たらid:3のデータでトリガーしてくれます。
詳細はこちらを参照してください。 zapier.com
ということで実際にPolling Triggerを作成していきます。
Polling Triggerの作成
では例としてサーバの起動状態が変わったことを検知するPolling Triggerを作成してみます。
まずこんな感じで基本的な項目を入力します。

次にInputは先ほど作ったActionと同じようにZoneを追加しておきます。

API Configuration
次にAPI Configurationです。
ここではAPIでデータを取得した後Zapierが理解できる形にデータを変換します。
コードを用いるため、Switch to Code Modeボタンを押してコード入力モードに切り替え、以下のコードを入力します。
const options = { url: `https://secure.sakura.ad.jp/cloud/zone/${bundle.inputData.Zone}/api/cloud/1.1/server`, method: 'GET' } return z.request(options) .then((response) => { response.throwForStatus(); const results = response.json; return results.Servers.map( (v) => { v.originalId = v.ID; v.id = z.hash('md5', v.ID + v.Instance.StatusChangedAt); return v; }); });
ポイントは以下の部分です。
return results.Servers.map( (v) => { v.originalId = v.ID; v.id = z.hash('md5', v.ID + v.Instance.StatusChangedAt); return v; });
APIからの戻り値のIDフィールドと、起動状態が最後に変わった日時を保持しているフィールドInstance.StatusChangedAtを結合した値からハッシュを算出してidにしています。
こうすることでサーバの起動状態が変わったらidが変更されZapierから変更を検知できるようになります。
あとはActionの時と同じでテストを行い保存しておきます。
Zapを作成して動作確認
ではIntegrationを使ってみます。 今回はサーバの起動状態が変わったらDiscordの特定チャンネルにメッセージを投稿してみます。
Triggerの選択〜編集
Zapの作成画面を開き、Zap名を入力、作成したIntegrationの名前を入力して検索&選択してください。

トリガーとして先ほど作成したものが選択できるようになっているはずです。

アカウント選択〜ゾーンの選択を行いテストまでしておきましょう。 うまくいけばこんな画面が表示されます。

Actionの選択〜編集
次にDiscordの特定チャンネルにメッセージを送るためのアクションを設定します。
Discordを選択し、Action EventとしてSend Channel Messageを選択します。

次に送信先チャンネルの選択やメッセージの設定を行います。 メッセージ本文にはTriggerが取得したサーバの情報が利用可能です。

いい感じに設定しましょう。
投稿するBotの名前やアイコンも変更できますのでお好みで変更してみてください。
あとはTurn on Zapをクリックして有効化しましょう!
動作確認
それではサーバの起動状態を変えるためにシャットダウンしたり起動したりしてみましょう。 うまくいけばDiscordにこんな感じのメッセージが届くはずです。

良さそうですね!!
ポーリングの間隔は?
ポーリングの間隔はプランごとに決まっているようです。

Free/Starterプランで15分ごと、Professionalプランで2分ごと、Team/Companyプランで毎分となっています。
用途に合わせて適切なプランを選びましょう。
(個人的にはProfessionalがもうちょっと安くなってくれれば、、、と感じてます)
まとめ
ということで今回はZapierとさくらのクラウドを組み合わせてみました。
日々の運用に、レポート作成にと様々な用途で利用できるかと思います。夢が広がりますね!
ただIntegrationの作成で若干のコードを書かないといけないのが不満です。
これはさくらのクラウド向けPublic Integrationを作成して公開すると解決できそうです。
例えばDigitalOceanであればこんな形でPublic Integrationが公開されておりすぐに利用できるようになっています。 zapier.com
今はこの記事で試したことをベースにCLIによるIntegrationの作成を試してみているところですので、それが上手くいったら公開したいと思っています。
何とか今年中には公開したいですね。開発を頑張ります…
ということでZapier+さくらのクラウドはなかなかに便利だと思いますので是非お試しくださいー!
以上です。

おまけ: 他のiPaaS的なもの
今回の記事を書くにあたりZapier以外のいくつかのiPaaS(的なものも含む)でもさくらのクラウドのAPIを使って連携できるか試してみました。
IFTTTはAPIをポーリングして変更を検知というのが難しかったです(結構ガッツリとコード書く必要がありそう)。
またWorkatoについては最終的なお値段は問い合わせないとわからないということだったので途中で試すのをやめちゃいました(なかなかいいお値段との情報もちらほら…)。
残るPower Automateやn8n.ioはそれぞれZapierとは違った魅力を感じました。
Zapierだと結構いいお値段ですので、割と手軽なお値段のPower Automateやオンプレにも立てられるn8n.ioは環境/状況次第では選択肢になりそうでした。
この辺についてはまた機会があれば記事にしようかと思っています。
最後のRed Hat Fuse Online/Syndesisについてですが、個人的にはApache Camel大好きなので是非試したかったところなのですが時間がなくて今回は試せませんでした。また時間を見つけてチャレンジしてみるつもりです。
それでは今度こそ以上です。

さくらの専用サーバPHYのAPIをGoから使う sacloud/phy-go
リリースしました。
なにこれ?
さくらの専用サーバPHYは一部の操作をAPIから行えるようになっています。
APIはOpenAPI 3.0で記述されたAPI定義が公開されており、コードジェネレータさえ対応していればお好きなプログラミング言語から手軽に利用できるようになっています。
sacloud/phy-goはAPI定義から生成されたコードをラップし、より簡素な記述ができるようにしたものです。
Exponential Backoffなリトライやレスポンスのトレースログ出力といった便利機能も持ってます。
どんな感じで使うの?
サーバのACPIシャットダウンを行うコードを例に、API定義から生成したコードをそのまま使う方法とsacloud/phy-goを使う方法を比較してみます。
生成したコードをそのまま使う場合
result, err := client.PostServersServerIdPowerControlWithResponse(
context.Background(),
serverId,
&PostServersServerIdPowerControlParams{
XRequestedWith: "XMLHttpRequest",
},
PostServersServerIdPowerControlJSONRequestBody{
Operation: "soft", // ACPIシャットダウン
})
if err != nil {
return err
}
if result.StatusCode() == http.StatusNoContent {
// ...
}
sacloud/phy-goを使う場合
if err := phy.NewServerOp(client).PowerControl(ctx, serverId, v1.ServerPowerOperationsSoft); err != nil { return err }
より簡潔に書けるようになってると思います。
PHYのAPIを使う上での注意点
専用サーバPHYのAPIにはレートリミットが設けられています。
https://manual.sakura.ad.jp/ds/phy/api/api-spec.html#section/基本的な使い方/API(Rate-Limiting)
あまりAPIを使いすぎると429エラーになってしまいます。
sacloud/phy-goにはFakeサーバが同梱されていますので開発中はこちらを利用しましょう。 利用方法はsacloud/phy-goのREADME.mdを参照してください。
終わりに
ということでGoからPHYのAPIを使う際はsacloud/phy-goを是非ご利用ください。 以上です。
さくらのクラウド: VPCルータのWireGuardサーバ機能を試す(macOS編)
昨日VPCルータにWireGuardサーバ機能が追加されたとのお知らせが出ていました。
動作確認のために手元のmacOSから繋いでみたのでメモを残しておきます。
手順
- (存在しなければ) VPCルータの作成
- WireGuardサーバの有効化
- クライアントの設定/ピアの追加
VPCルータの作成
まずはVPCルータが必要です。WireGuard機能はVPCルータバージョン2のみサポートとのことです。
プランはどれでも構いません。今回はスタンダードプランを利用しました。
作成したらプライベート側インターフェースの設定(スイッチの接続&IPアドレスの設定)をしておきます。
今回はプライベート側アドレスとして192.168.100.1/24を指定しました。

WireGuardサーバの有効化
次に「リモートアクセス」タブの中の「WireGuardサーバ」タブを開きWireGuardサーバを有効化します。
今回はWireGuardサーバのIPアドレスを192.168.101.1/24としました。

設定後は「反映」ボタンを押すのを忘れないようにします。
公開鍵は起動しないと表示されないためこのタイミングで一度起動します。
クライアントの設定/ピアの追加
次にピアを追加していきます。 今回はmacOS版のWireGuardを利用しますので先にそちらの設定を行なっていきます。
以下の情報が必要になりますのであらかじめメモしておきます。
準備ができたらまずはmacOS側の準備を行います。
macOS版のWireGuardをインストール(まだしていない場合)
macOS向けにはMac App Storeで配布されていますのでそちらを利用します。

WireGuardへ設定の追加
インストールしたら起動して「設定が空のトンネルを追加」を選択します。
以下のような画面が表示されますので必要な情報を入力していきます。

今回はこんな感じにしました。
[Interface] PrivateKey = (秘密鍵、最初から入力済みなはず) ListenPort = 51820 Address = 192.168.101.11/24 # クライアント側には192.168.101.11/24を割り当て [Peer] PublicKey = メモしておいたWireGuardサーバの公開鍵 AllowedIPs = 192.168.0.0/16 Endpoint = メモしておいたVPCルータの公開側IPアドレス:51820 PersistentKeepalive = 25
IPアドレスは192.168.101.11/24を割り当てました。
VPCルータのプライベート側ネットワークとやりとりしたいためにAllowedIPsには192.168.0.0/16を指定します。
必要に応じて適宜変更してください。
ここで表示されている公開鍵がVPCルータ側でピアの追加を行う際に必要になりますのでメモしておきます。
WireGuardサーバ側でピアを追加
次にピアを追加します。

- 名前: 任意
- IPアドレス: 今回は
192.168.101.11 - 公開鍵: 先程控えたクライアントの公開鍵
追加したら「反映」ボタンを忘れずに押しておきましょう。
後は接続して動作確認してみます。うまく設定できていればmacOSとVPCルータのプライベート側ネットワークとで疎通できているはずです。
というわけでmacOSからWireGuardでVPCルータとVPN接続してみました。
WireGuardのMacアプリが提供されていますので手軽でいいですね。
以上です。
作業メモ: さくらのクラウド上のVMにVzLinuxをインストール
VzLinux 8 !?
Twitterを眺めてたらこんなツイートを見かけました。
CentOSの代替に、第三の選択肢が登場しました。Red Hat Enterprise Linuxベースの「VzLinux」です。スイスに拠点をおくVirtuozzo International社が開発し、20年前から有償で提供していたものを、コミュニティエディションとして無償で公開したようです。https://t.co/JCuzDiuJwy pic.twitter.com/5Lv1VDIp5q
— 日経Linux | ラズパイマガジン (@nikkei_Linux) 2021年6月1日
OpenVzのあのVirtuozzoですね!古くからコンテナ型仮想化を触ってきた方は懐かしいと感じる方もいらっしゃるかと思います。
(ずっと現役だったみたいなのですが私個人としてはVirtuozzo/OpenVzにはここ数年触ってませんでした)
そのVirtuozzoからRHEL8とバイナリ互換のあるディストリビューションとしてVzLinux8が一般公開されたそうです。
CentOSの代替を意識しているのか、公式サイトにはCentOSよりも早くn日リリースしたよー的なことが書かれていたりします。
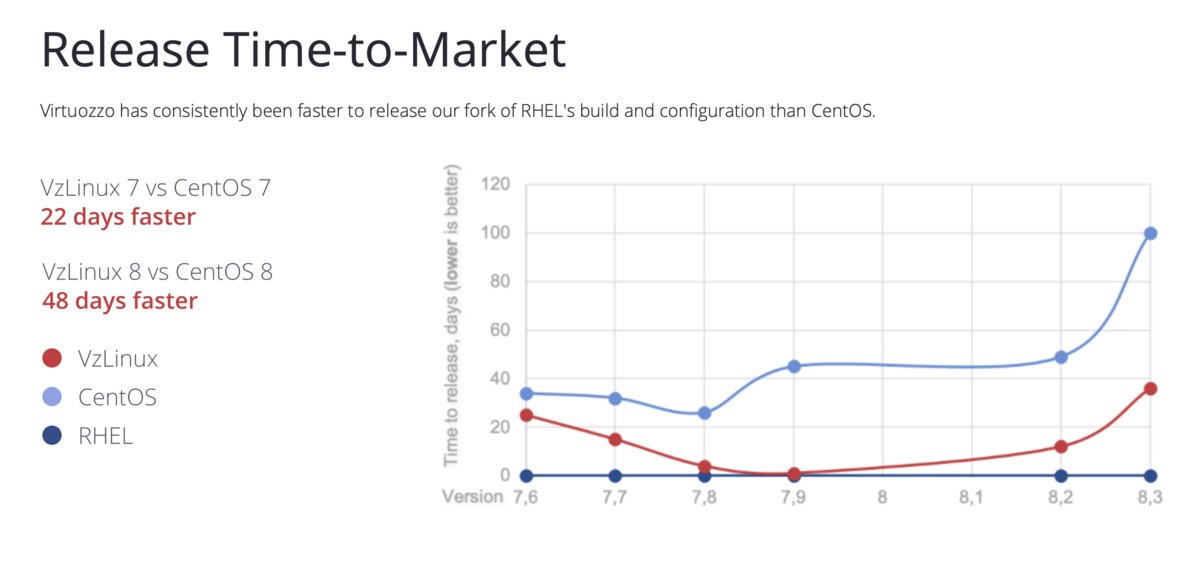
画像の引用元: https://vzlinux.org
とりあえず動かしてみるためにさくらのクラウド上のVMにインストールしてみましたのでそのメモを残しておきます。
VzLinuxのインストール
ISOイメージが以下で公開されています。
ここからダウンロードします。今回はcurlコマンドを使いました。
その後CLIであるusacloudでさくらのクラウド上にリソース作成〜ISOイメージのアップロード〜サーバ作成〜起動を行います。
# ISOイメージのダウンロード $ curl -LO http://repo.virtuozzo.com/vzlinux/8/iso/vzlinux-8-min.iso # さくらのクラウド上でISOイメージ作成&アップロード $ usacloud cdrom create -y --name vzlinux --source-file vzlinux-8-min.iso # ディスクの作成 $ usacloud disk create -y --name vzlinux --size 20 # サーバの作成 $ DISK_ID=`usacloud disk read -q vzlinux` $ CDROM_ID=`usacloud cdrom read -q vzlinux` $ usacloud server create -y --name vzlinux --cpu 2 --memory 4 --boot-after-create --cdrom-id $CDROM_ID --disk-id $DISK_ID --network-interface-upstream shared
作成完了するまで待ってからサーバのコンソールを開きます。
今回はVNCクライアントを使いました。もちろんコントロールパネルからコンソールを開いてもOKです。
$ usacloud server vnc vzlinux
インストーラーはこんな感じでした。

rootユーザーのパスワードなどを適当に設定した上でインストールします。
しばらく待つとインストールできるはずです。
インストールが完了したらボタンを押して再起動しましょう。
SSHで繋いでみる
再起動が完了するとSSHが繋がる状態になっているはずです。
$ usacloud server ssh vzlinux
↓はSSHで繋いだあとに/etc/os-releaseを表示したところです。
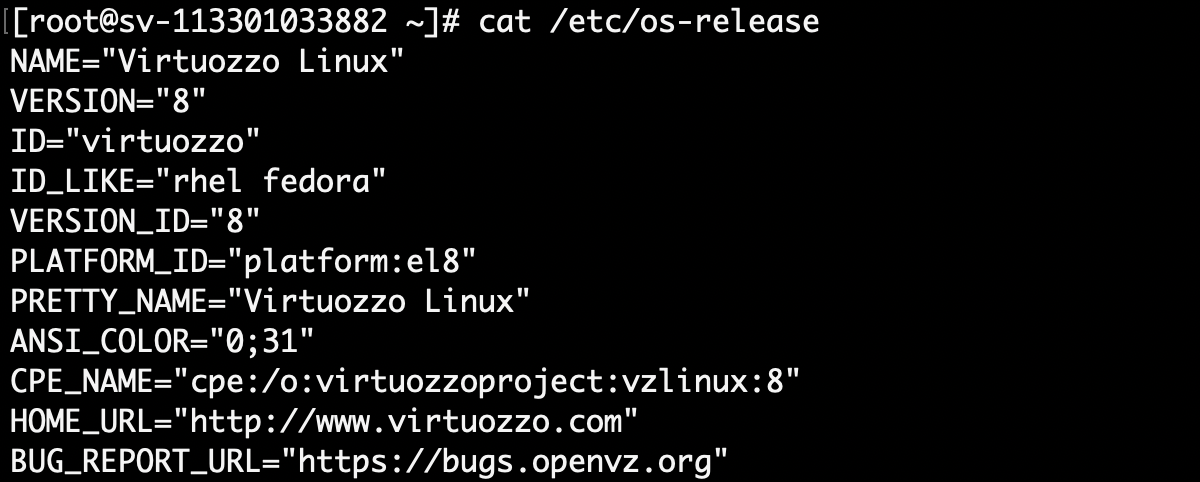
とりあえずこれで色々と触っていけますね!
終わりに
ということでとりあえずVzLinuxをインストールしてみました。
これから色々触ってみようかと思います。
以上です。
Terraform CDK + Java + コミュニティプロバイダーを使ってみる
Terraform CDK + Java + コミュニティプロバイダー(さくらのクラウド)という組み合わせを試してみます。
概要
Terraform CDKとは
Terraform CDKとは汎用のプログラミング言語を用い、Terraform(+エコシステム)を通じてクラウドなどの各種プラットフォームを操作するためのツールです。
サポートされているプログラミング言語としては以下のようなものがあります。
Terraform CDKの位置付け/立ち位置
AWS CDKが汎用のプログラミング言語での定義からCloudFormationのコンフィグレーションを生成するのと同じく、 Terraform CDKは汎用のプログラミング言語での定義からTerraformのコンフィグレーションを生成します。
こちらの図にある通り、Terraformへの入力の一つという位置付けです。
 (出典: https://www.hashicorp.com/blog/cdk-for-terraform-enabling-python-and-typescript-support)
(出典: https://www.hashicorp.com/blog/cdk-for-terraform-enabling-python-and-typescript-support)
Terraformへの入力という位置付けなため、定義(dev)->プラン(plan)->適用(apply)というTerraformを用いたワークフローはそのまま利用する形です。
先ほどの記事にもThe goal of Terraform is to provide a consistent workflow for provisioning infrastructure(著者訳: Terraformのゴールはインフラのプロビジョニングに対し一貫したワークフローを提供することです)と章のはじめに書かれており、The Tao of HashiCorpにも書かれているワークフローへのこだわり(テクノロジーじゃない、ワークフローだ)を感じさせられます。
利用者は次に紹介するCLI cdktf を介してTerraformの各種コマンドを利用したり、Terraform向けのコードを(cdktf CLIで)生成して手動でTerraform CLIを実行するということも可能です。
Terraform CDKのツール
主に2つのパッケージが提供されています。
いずれもTypeScriptで実装されています。
CLIのヘルプはこんな感じです。
$ cdktf --help cdktf [command] Commands: cdktf deploy [OPTIONS] Deploy the given stack cdktf destroy [OPTIONS] Destroy the given stack cdktf diff [OPTIONS] Perform a diff (terraform plan) for the given stack cdktf get [OPTIONS] Generate CDK Constructs for Terraform providers and modules. cdktf init [OPTIONS] Create a new cdktf project from a template. cdktf login Retrieves an API token to connect to Terraform Cloud. cdktf synth [OPTIONS] Synthesizes Terraform code for the given app in a directory. [aliases: synthesize] Options: --version Show version number [boolean] --disable-logging Dont write log files. Supported using the env CDKTF_DISABLE_LOGGING. [boolean] [default: true] --disable-plugin-cache-env Dont set TF_PLUGIN_CACHE_DIR automatically. This is useful when the plugin cache is configured differently. Supported using the env CDKTF_DISABLE_PLUGIN_CACHE_ENV. [boolean] [default: false] --log-level Which log level should be written. Only supported via setting the env CDKTF_LOG_LEVEL [string] -h, --help Show help [boolean] Options can be specified via environment variables with the "CDKTF_" prefix (e.g. "CDKTF_OUTPUT")
CLIを用いた開発〜デプロイ(リソース作成)の基本的な流れは以下のようになります。
cdktf initで言語別のテンプレートからTerraform CDKプロジェクトを生成- 構成ファイル
cdktf.jsonに必要なTerraformプロバイダー/モジュールなどを定義 cdktf getでプロバイダー/モジュールの取得〜TypeScriptのコード生成(jsii向け)
(Note: Terraform CDKは多言語サポートのためにjsiiを利用しているため、一旦TypeScriptのコードが生成される)- 生成されたコードとライブラリの方の
cdktfを用いてインフラのリソース定義 cdktf deployして適用(またはcdktf synthでJSONを出力してterraform apply)
主要プロバイダー向けにはあらかじめコード生成済みのPrebuilt Providersも提供されています。
https://github.com/hashicorp/terraform-cdk/blob/main/docs/working-with-cdk-for-terraform/using-providers-and-modules.md#prebuilt-providers
例えばTypeScriptでリソース定義を行う場合以下のようなコードになります。
import { Construct } from "constructs"; import { App, TerraformStack } from "cdktf"; import { AwsProvider, Instance } from "./.gen/providers/aws"; class MyStack extends TerraformStack { constructor(scope: Construct, id: string) { super(scope, id); new AwsProvider(this, "aws", { region: "us-east-1", }); new Instance(this, "Hello", { ami: "ami-2757f631", instanceType: "t2.micro", }); } } const app = new App(); new MyStack(app, "hello-terraform"); app.synth();
細かな解説は省きますが、ポイントは以下のとおりです。
- aws/constructsを利用している
- ライブラリの方の
cdktfを利用している - 生成されたコードは
./.gen配下に格納される
利用するプロバイダーの定義とリソースの定義だけのシンプルな例となっています。
コードを追加すればステートの保存先としてリモート(Terraform CloudやS3など)を利用することも可能です。
Terraform Cloud利用時の注意点
現時点ではTerraform Cloud上でterraformコマンドを実行するExecution Mode=Remoteは利用できず、ステートだけをTerraform Cloudに保存するExecution Mode=Localのみ利
用可能です。
参考: terraform-cdk/remote-backend.md at 342b4cc71568cc73be93954901265f753e8709b4 · hashicorp/terraform-cdk · GitHub
利用例: Terraform CDK + さくらのクラウド + Java
ここでは例としてJavaを用いてさくらのクラウド上にリソースを作成してみます。
余談ですが類似プロダクトのPulumiではJavaはまだサポートされていません
事前準備(Javaのみ、今だけの暫定処置)
現時点ではTerraform CDK周りのライブラリがMavenセントラルに登録されておらずGitHub Packages(https://maven.pkg.github.com/hashicorp/terraform-cdk)での提供となります。
このため、事前にMavenからGitHub Packagesを利用できるようにするための設定が必要になります。
(この問題は将来的に解消予定とのこと)
UPDATE: 2021/10/20 久しぶりに確認したらすでにMaven Centralで公開されていました。
https://search.maven.org/artifact/com.hashicorp/cdktf
なので以下の~/.m2/settings.xmlの編集は不要になっています。
=== UPDATE ここまで
事前にGitHubのPersonal Access Tokenを取得した上で~/.m2/settings.xmlファイルを以下のようにしておいてください。(ファイルがなければ作成する)
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0 http://maven.apache.org/xsd/settings-1.0.0.xsd"> <activeProfiles> <activeProfile>github</activeProfile> </activeProfiles> <profiles> <profile> <id>github</id> <repositories> <repository> <id>central</id> <url>https://repo1.maven.org/maven2</url> </repository> <repository> <id>cdktf</id> <url>https://<GitHubユーザー名>:<アクセストークン>@maven.pkg.github.com/hashicorp/terraform-cdk</url> <snapshots> <enabled>true</enabled> </snapshots> </repository> </repositories> </profile> </profiles> </settings>
参考: Working with the Apache Maven registry - GitHub Docs
CLIのインストール
まずTerraform CDKのCLIをインストールしておきます。
通常はstable版をインストールするのですが、今回はこの記事執筆段階でTerraform CDK側の問題を見つけたため、その問題が解消されたv0.2.3以降が必要です。
本日(2021/4/16)時点ではv0.2.3は未リリースですのでstable版ではなく開発版をインストールします。
$ npm install --global cdktf-cli@next
開発用のディレクトリの作成 & 初期コードの生成
次にcdktfでプロジェクトの雛形を生成します。
適当なディレクトリを作成しcdktf initを実行してください。
# ステートの管理はローカル + 開発言語にはJavaを利用する $ cdktf init --local --template java
うまくいくと以下のようなファイル構成になっているはずです。
$ tree . . ├── cdktf.json ├── help ├── pom.xml ├── src │ └── main │ └── java │ └── com │ └── mycompany │ └── app │ └── Main.java └── target ├── cdk-work-java2-0.1.jar ├── classes │ └── com │ └── mycompany │ └── app │ └── Main.class ├── generated-sources │ └── annotations ├── maven-archiver │ └── pom.properties └── maven-status └── maven-compiler-plugin └── compile └── default-compile ├── createdFiles.lst └── inputFiles.lst
cdktf.jsonに依存プロバイダーを記載
次にカレントディレクトリに生成されているcdktf.jsonを編集します。
今回はさくらのクラウド向けプロバイダーを利用するのでterraformProvidersにsacloud/sakuracloud@~> 2.8と追記してください。
{ "language": "java", "app": "mvn -e -q compile exec:java", "terraformProviders": [ "sacloud/sakuracloud@~> 2.8" ], "terraformModules": [], "context": { "excludeStackIdFromLogicalIds": "true", "allowSepCharsInLogicalIds": "true" } }
cdktf getの実行
次にプロバイダーの取得~コード生成を行うためにcdktf getを実行します。
$ cdktf get
Generated java constructs in the output directory: .gen
通常は生成されたコードが.genディレクトリ配下にあるのですが、Javaの場合はsrc/main/java/imports.sakuracloud配下などに配置されています。
Javaでリソース定義
次にsrc/main/java/com/mycompany/app/Main.javaにコードを書いていきます。
今回はシンプルにスイッチを作るだけの例です。
package com.mycompany.app; import imports.sakuracloud.SakuracloudProvider; import imports.sakuracloud.Switch; import software.constructs.Construct; import com.hashicorp.cdktf.App; import com.hashicorp.cdktf.TerraformStack; public class Main extends TerraformStack { public Main(final Construct scope, final String id) { super(scope, id); // プロバイダーの定義 SakuracloudProvider.Builder.create(this, "default").build(); // リソースの定義 Switch.Builder.create(this, "testSwitch") .name("from-terraform-cdk-with-java") .description("this resource is created by terraform-cdk with java") .build(); } public static void main(String[] args) { final App app = new App(); new Main(app, "cdk-work-java"); app.synth(); } }
Terraformのコンフィギュレーションの生成(省略可能)
次に先ほど書いたコードからTerraformのコンフィギュレーションを生成してみます。
$ cdktf synth
Generated Terraform code in the output directory: cdktf.out
うまくいくとcdktf.outというディレクトリにcdk.tf.jsonというJSONファイルが生成されます。
$ tree cdktf.out/ cdktf.out/ └── cdk.tf.json 0 directories, 1 file
このファイルはTerraform CLIに直接渡せるものとなっています。
なお次のcdktf deployを実行するとsynthも実行されますのでこの工程は省略可能です。
cdktf deployでデプロイ
いよいよデプロイです。cdktf deployを実行します。
途中で実行して良いか聞かれますのでyesを入力します。
$ cdktf deploy Stack: cdk-work-java Resources + SAKURACLOUD_SWITCH testSwitch sakuracloud_switch.testSwitch Diff: 1 to create, 0 to update, 0 to delete. Do you want to perform these actions? CDK for Terraform will perform the actions described above. Only 'yes' will be accepted to approve. Enter a value: # yesと入力する # しばらく待つ Resources ✔ SAKURACLOUD_SWITCH testSwitch sakuracloud_switch.testSwitch Summary: 1 created, 0 updated, 0 destroyed.
デプロイできましたね!
今回はステートをローカルに保存するようにしましたので、カレントディレクトリにterraform.tfstateファイルが作成されているはずです。
後片付け: cdktf destroy
最後に忘れずに作成したリソースの削除を行っておきます。
こちらも途中で実行して良いか聞かれますのでyesと入力します。
$ cdktf destroy
これで削除されるはずです。
終わりに
今回はTerraform CDKの紹介とTerraform CDK+さくらのクラウドプロバイダーを利用する方法について紹介しました。
またまだ開発段階ということでちらほら気になる挙動があったりしますが、Pulumiと比べると既存のTerraformプロバイダーが利用しやすいと感じました。
(Pulumiの場合はブリッジを書く必要がある)
Terraformへの入力が変わるだけで既存のワークフロー(CI/CDなど)はそのまま利用できるのも嬉しいですね。
今後もう少し使い込んでみようかと思います。以上です。
: Developer Guide (English Edition)")
Packer v1.7 - initコマンドでプラグインをインストール
Packer v1.7からプラグインを特定のルールに沿って作成されたGitHub Releasesからダウンロード〜インストールできるpacker initコマンドが追加されました。
最近さくらのクラウド向けPackerプラグイン sacloud/packer-plugin-sakuracloudでこのpacker initに対応しましたので今回はその紹介をしていきます。
packer initコマンド
Packer v1.7からpacker initコマンドが追加されました。
従来はPackerに組み込まれていないビルダーやプロビジョナーなどのプラグインは手動でインストールしていましたが、packer initを実行することでプラグインのダウンロード〜インストールを行ってくれるようになりました。
Terraformにおけるterraform initみたいな感じです。
ただ、Packerには今の所状態を管理する機能はありませんのでpacker initはプラグインのインストールのみを行います。
また、プラグインのダウンロードは今の所GitHub上の公開リポジトリからのみ可能とのことです。
なおpacker initのドキュメントでは Currently って書いてあるのが目につくので、将来的にいろいろ拡張されそうな気配を感じます。
packer initの使い方
ドキュメントはこちらです。
まずpacker initを行うためにはいくつかの条件があります。
古くからあるJSONテンプレートでは利用できない点に注意が必要です。
これらの条件を満たすプラグインであれば、以下のようなrequired_pluginsブロックをテンプレートファイルに記載した上でpacker initでインストール可能です。
packer { required_plugins { sakuracloud = { version = ">= 0.7.0" source = "github.com/sacloud/sakuracloud" } } }
# プラグインのインストール
$ packer init template.pkr.hcl
なお、v1.7時点では従来Packer本体に組み込まれていたビルダーやプロビジョナーはまだ別リポジトリに分離されておらず、packer initなしで利用可能です。
また、packer initに対応していないプラグインでも手動インストールすることで利用は可能です。
ただし、Packer v1.7ではPacker本体とプラグインとの間の通信プロトコルのバージョンが変更されている(マイナーバージョンという概念が追加された)ため、古いプラグインはそのままだと利用できないケースもあります。
プラグインとの通信プロトコルバージョンによるエラーメッセージの例:
Error: Failed to load source type The protocol of this plugin (protocol version 4 and lower) was deprecated, please use a newer version of this plugin.Or use an older version of Packer (pre 1.7) with this plugin.
利用例: さくらのクラウド向けプラグイン
packer initの利用例としてさくらのクラウド向けプラグインでの利用方法を紹介します。
packer-plugin-sakuracloud v0.7からpacker initに対応しています。
(packer initに対応するために名称をpacker-builder-sakuracloudから変更しました)
以下のようなテンプレートを用意することでプラグインのインストール〜packer buildの実行が可能です。
# template.pkr.hcl # required_pluginブロックで利用するプラグインを宣言 packer { required_plugins { sakuracloud = { version = ">= 0.7.0" source = "github.com/sacloud/sakuracloud" } } } source "sakuracloud" "example" { zone = "is1a" os_type = "centos8" password = "input-your-password" disk_size = 20 disk_plan = "ssd" core = 1 memory_size = 1 archive_name = "packer-example-centos" archive_description = "description of archive" } build { sources = [ "source.sakuracloud.example" ] provisioner "shell" { inline = [ "echo 'hello!'", ] } }
テンプレートを用意し以下のコマンドで実行していきます。
# APIキーを環境変数に設定 $ export SAKURACLOUD_ACCESS_TOKEN=xxx $ export SAKURACLOUD_ACCESS_TOKEN_SECRET=xxx # プラグインのインストール $ packer init template.pkr.hcl Installed plugin github.com/sacloud/sakuracloud v0.7.0 in "~/.packer.d/plugins/github.com/sacloud/sakuracloud/packer-plugin-sakuracloud_v0.7.0_x5.0_darwin_amd64" # buildの実行 $ packer build template.pkr.hcl
従来の手動インストールと比べると手軽に利用できるようになりました。
GitHub Container Registryでのpacker-plugin-sakuracloudのDockerイメージの配布
なおpacker-plugin-sakuracloud v0.7からDockerHubに加えGitHub Container RegistryでのDockerイメージ配布も行われるようになりました。
Dockerで利用する場合は次のようなコマンドで実行します。
$ docker run -it --rm \ -e SAKURACLOUD_ACCESS_TOKEN \ -e SAKURACLOUD_ACCESS_TOKEN_SECRET \ -v $PWD:/work \ -w /work \ ghcr.io/sacloud/packer:latest build template.pkr.hcl
ベースイメージにhashicorp/packer:lightを使うようになりました。
従来通りのsacloud/packerも継続して利用可能です。
(プラグイン開発者向け)プラグイン側がpacker initに対応するには
Packerプラグインがpacker initに対応するにはいくつかの条件があります。
- Packer Plugin SDKに対応していること
(かつmulti-component RPC serverであること) - プラグインのバイナリの名前が
packer-plugin-*という形式(従来はpacker-builder-*やpacker-provisioner-*だった)であること
(これはmulti-component pluginsと呼ばれる。従来のものはsingle-component plugins) - 所定の手順でGitHub Releasesでリリースすること
詳細は以下のドキュメントに記載されています。
新しくプラグインを作成する場合はscaffoldが提供されています。
Packer v1.6以前にプラグインを提供していた場合向けの移行ガイドやPacker Plugin SDKへのマイグレーションツールも提供されています。
packer initに対応するかはともかくとしても、Packer Plugin SDKへの移行はしておかないとPacker v1.7でエラー(The protocol of this plugin~)がでるようですので
Packer v1.6以前のプラグインは早めにマイグレーションした方が良さそうです。
以上です。