さくらの専用サーバPHYのAPIをGoから使う sacloud/phy-go
リリースしました。
なにこれ?
さくらの専用サーバPHYは一部の操作をAPIから行えるようになっています。
APIはOpenAPI 3.0で記述されたAPI定義が公開されており、コードジェネレータさえ対応していればお好きなプログラミング言語から手軽に利用できるようになっています。
sacloud/phy-goはAPI定義から生成されたコードをラップし、より簡素な記述ができるようにしたものです。
Exponential Backoffなリトライやレスポンスのトレースログ出力といった便利機能も持ってます。
どんな感じで使うの?
サーバのACPIシャットダウンを行うコードを例に、API定義から生成したコードをそのまま使う方法とsacloud/phy-goを使う方法を比較してみます。
生成したコードをそのまま使う場合
result, err := client.PostServersServerIdPowerControlWithResponse(
context.Background(),
serverId,
&PostServersServerIdPowerControlParams{
XRequestedWith: "XMLHttpRequest",
},
PostServersServerIdPowerControlJSONRequestBody{
Operation: "soft", // ACPIシャットダウン
})
if err != nil {
return err
}
if result.StatusCode() == http.StatusNoContent {
// ...
}
sacloud/phy-goを使う場合
if err := phy.NewServerOp(client).PowerControl(ctx, serverId, v1.ServerPowerOperationsSoft); err != nil { return err }
より簡潔に書けるようになってると思います。
PHYのAPIを使う上での注意点
専用サーバPHYのAPIにはレートリミットが設けられています。
https://manual.sakura.ad.jp/ds/phy/api/api-spec.html#section/基本的な使い方/API(Rate-Limiting)
あまりAPIを使いすぎると429エラーになってしまいます。
sacloud/phy-goにはFakeサーバが同梱されていますので開発中はこちらを利用しましょう。 利用方法はsacloud/phy-goのREADME.mdを参照してください。
終わりに
ということでGoからPHYのAPIを使う際はsacloud/phy-goを是非ご利用ください。 以上です。
さくらのクラウド: VPCルータのWireGuardサーバ機能を試す(macOS編)
昨日VPCルータにWireGuardサーバ機能が追加されたとのお知らせが出ていました。
動作確認のために手元のmacOSから繋いでみたのでメモを残しておきます。
手順
- (存在しなければ) VPCルータの作成
- WireGuardサーバの有効化
- クライアントの設定/ピアの追加
VPCルータの作成
まずはVPCルータが必要です。WireGuard機能はVPCルータバージョン2のみサポートとのことです。
プランはどれでも構いません。今回はスタンダードプランを利用しました。
作成したらプライベート側インターフェースの設定(スイッチの接続&IPアドレスの設定)をしておきます。
今回はプライベート側アドレスとして192.168.100.1/24を指定しました。

WireGuardサーバの有効化
次に「リモートアクセス」タブの中の「WireGuardサーバ」タブを開きWireGuardサーバを有効化します。
今回はWireGuardサーバのIPアドレスを192.168.101.1/24としました。

設定後は「反映」ボタンを押すのを忘れないようにします。
公開鍵は起動しないと表示されないためこのタイミングで一度起動します。
クライアントの設定/ピアの追加
次にピアを追加していきます。 今回はmacOS版のWireGuardを利用しますので先にそちらの設定を行なっていきます。
以下の情報が必要になりますのであらかじめメモしておきます。
準備ができたらまずはmacOS側の準備を行います。
macOS版のWireGuardをインストール(まだしていない場合)
macOS向けにはMac App Storeで配布されていますのでそちらを利用します。

WireGuardへ設定の追加
インストールしたら起動して「設定が空のトンネルを追加」を選択します。
以下のような画面が表示されますので必要な情報を入力していきます。

今回はこんな感じにしました。
[Interface] PrivateKey = (秘密鍵、最初から入力済みなはず) ListenPort = 51820 Address = 192.168.101.11/24 # クライアント側には192.168.101.11/24を割り当て [Peer] PublicKey = メモしておいたWireGuardサーバの公開鍵 AllowedIPs = 192.168.0.0/16 Endpoint = メモしておいたVPCルータの公開側IPアドレス:51820 PersistentKeepalive = 25
IPアドレスは192.168.101.11/24を割り当てました。
VPCルータのプライベート側ネットワークとやりとりしたいためにAllowedIPsには192.168.0.0/16を指定します。
必要に応じて適宜変更してください。
ここで表示されている公開鍵がVPCルータ側でピアの追加を行う際に必要になりますのでメモしておきます。
WireGuardサーバ側でピアを追加
次にピアを追加します。

- 名前: 任意
- IPアドレス: 今回は
192.168.101.11 - 公開鍵: 先程控えたクライアントの公開鍵
追加したら「反映」ボタンを忘れずに押しておきましょう。
後は接続して動作確認してみます。うまく設定できていればmacOSとVPCルータのプライベート側ネットワークとで疎通できているはずです。
というわけでmacOSからWireGuardでVPCルータとVPN接続してみました。
WireGuardのMacアプリが提供されていますので手軽でいいですね。
以上です。
作業メモ: さくらのクラウド上のVMにVzLinuxをインストール
VzLinux 8 !?
Twitterを眺めてたらこんなツイートを見かけました。
CentOSの代替に、第三の選択肢が登場しました。Red Hat Enterprise Linuxベースの「VzLinux」です。スイスに拠点をおくVirtuozzo International社が開発し、20年前から有償で提供していたものを、コミュニティエディションとして無償で公開したようです。https://t.co/JCuzDiuJwy pic.twitter.com/5Lv1VDIp5q
— 日経Linux | ラズパイマガジン (@nikkei_Linux) 2021年6月1日
OpenVzのあのVirtuozzoですね!古くからコンテナ型仮想化を触ってきた方は懐かしいと感じる方もいらっしゃるかと思います。
(ずっと現役だったみたいなのですが私個人としてはVirtuozzo/OpenVzにはここ数年触ってませんでした)
そのVirtuozzoからRHEL8とバイナリ互換のあるディストリビューションとしてVzLinux8が一般公開されたそうです。
CentOSの代替を意識しているのか、公式サイトにはCentOSよりも早くn日リリースしたよー的なことが書かれていたりします。
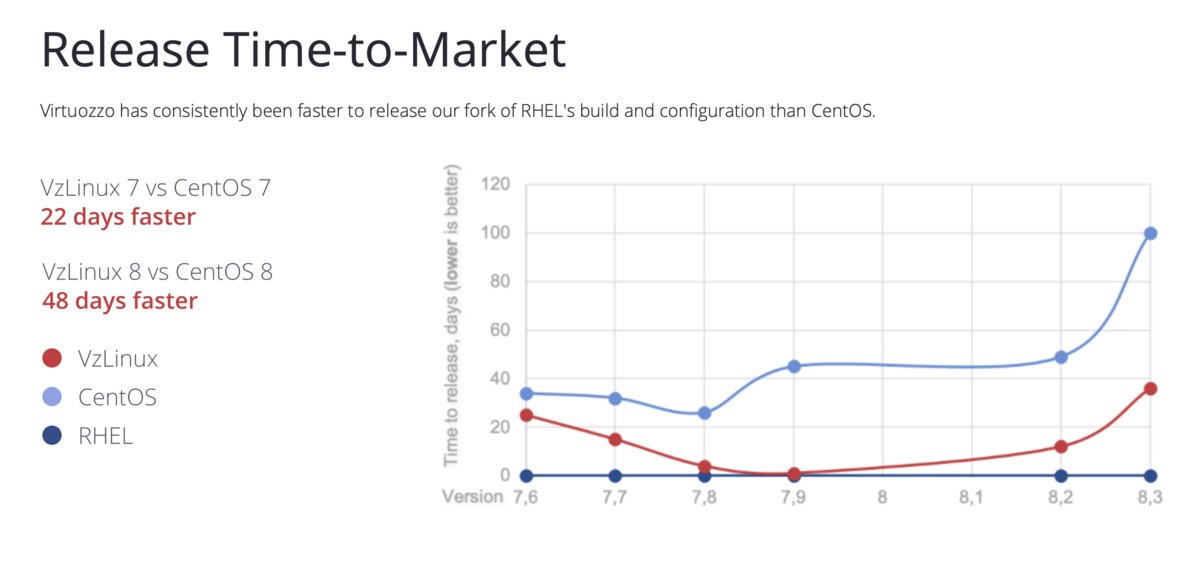
画像の引用元: https://vzlinux.org
とりあえず動かしてみるためにさくらのクラウド上のVMにインストールしてみましたのでそのメモを残しておきます。
VzLinuxのインストール
ISOイメージが以下で公開されています。
ここからダウンロードします。今回はcurlコマンドを使いました。
その後CLIであるusacloudでさくらのクラウド上にリソース作成〜ISOイメージのアップロード〜サーバ作成〜起動を行います。
# ISOイメージのダウンロード $ curl -LO http://repo.virtuozzo.com/vzlinux/8/iso/vzlinux-8-min.iso # さくらのクラウド上でISOイメージ作成&アップロード $ usacloud cdrom create -y --name vzlinux --source-file vzlinux-8-min.iso # ディスクの作成 $ usacloud disk create -y --name vzlinux --size 20 # サーバの作成 $ DISK_ID=`usacloud disk read -q vzlinux` $ CDROM_ID=`usacloud cdrom read -q vzlinux` $ usacloud server create -y --name vzlinux --cpu 2 --memory 4 --boot-after-create --cdrom-id $CDROM_ID --disk-id $DISK_ID --network-interface-upstream shared
作成完了するまで待ってからサーバのコンソールを開きます。
今回はVNCクライアントを使いました。もちろんコントロールパネルからコンソールを開いてもOKです。
$ usacloud server vnc vzlinux
インストーラーはこんな感じでした。
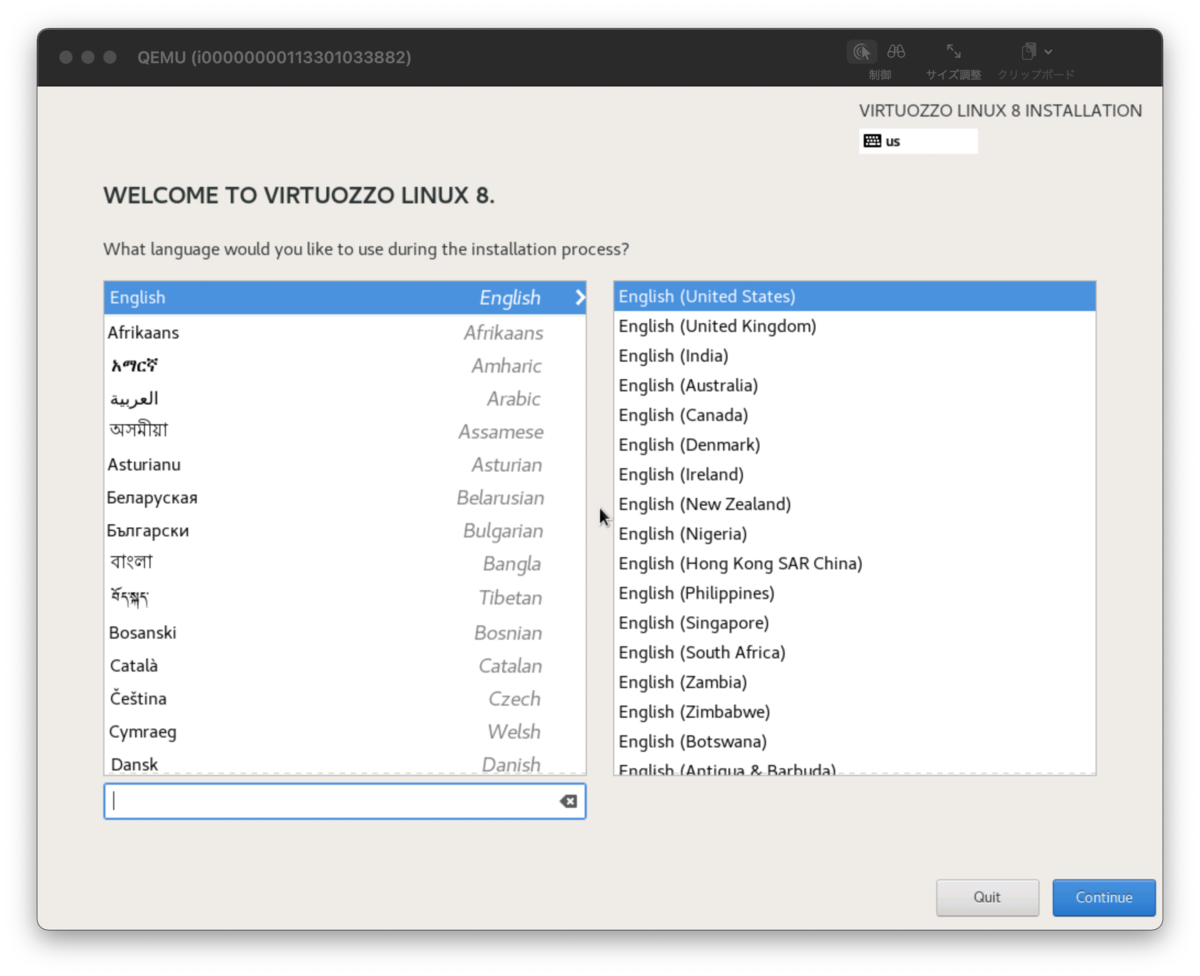

rootユーザーのパスワードなどを適当に設定した上でインストールします。
しばらく待つとインストールできるはずです。
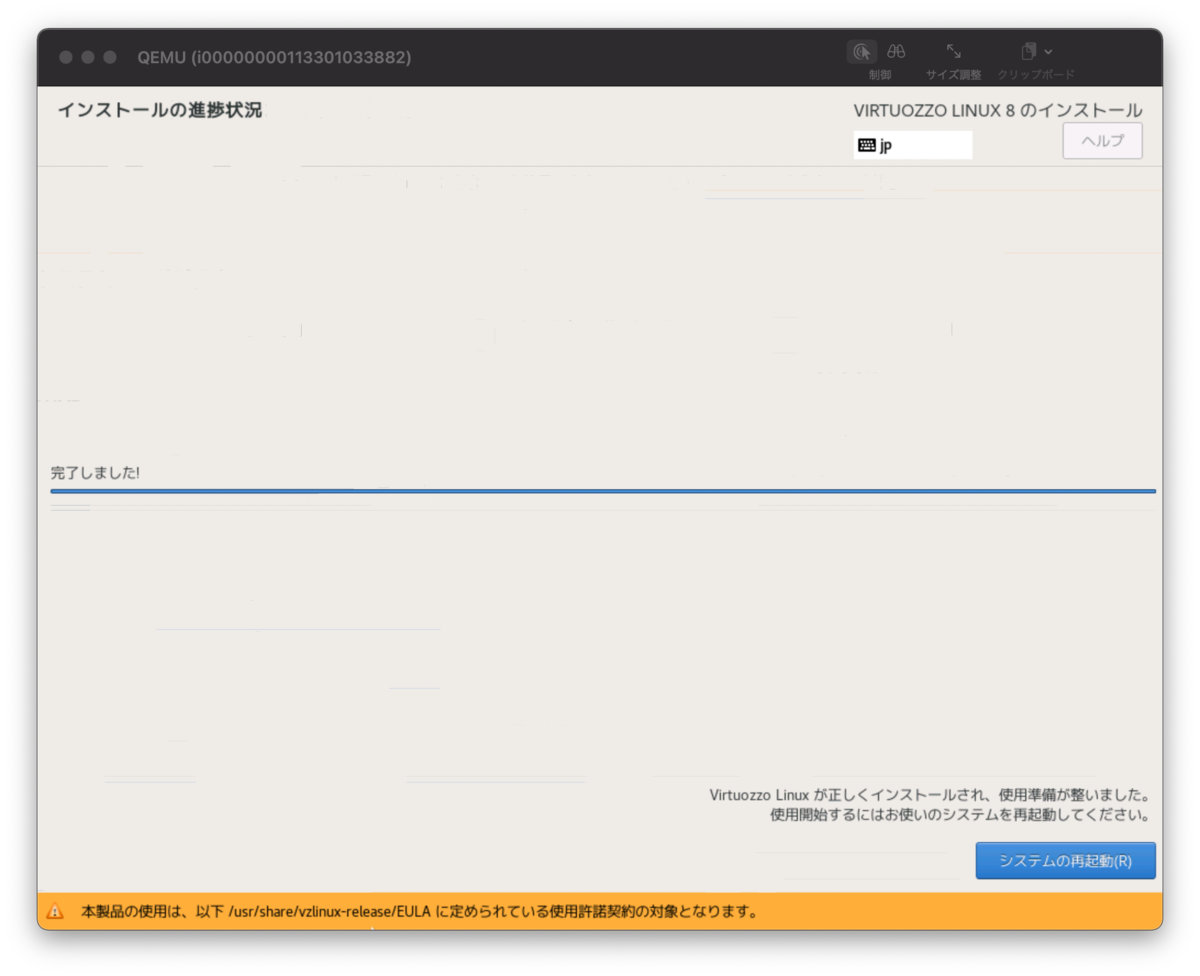
インストールが完了したらボタンを押して再起動しましょう。
SSHで繋いでみる
再起動が完了するとSSHが繋がる状態になっているはずです。
$ usacloud server ssh vzlinux
↓はSSHで繋いだあとに/etc/os-releaseを表示したところです。
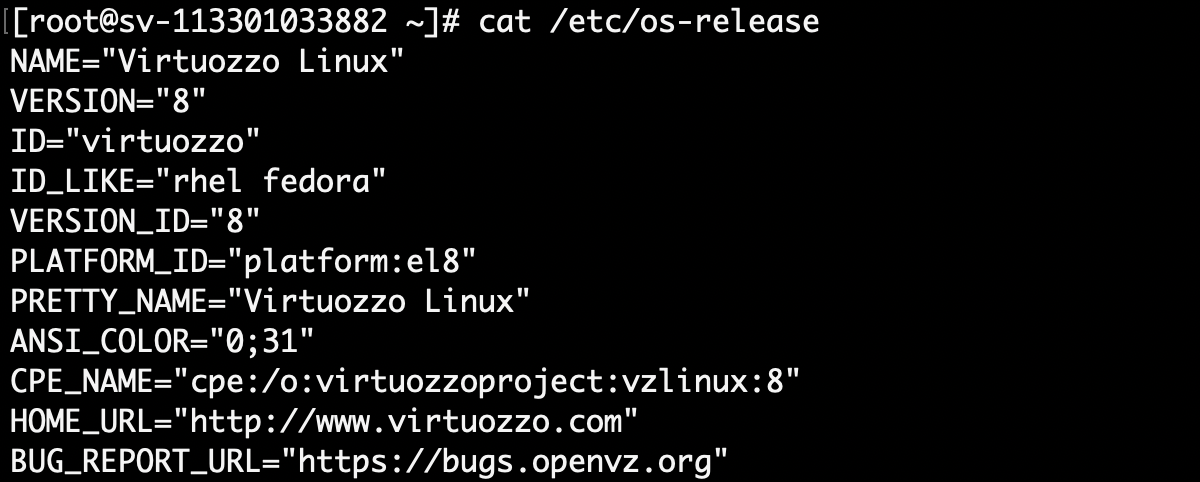
とりあえずこれで色々と触っていけますね!
終わりに
ということでとりあえずVzLinuxをインストールしてみました。
これから色々触ってみようかと思います。
以上です。
Terraform CDK + Java + コミュニティプロバイダーを使ってみる
Terraform CDK + Java + コミュニティプロバイダー(さくらのクラウド)という組み合わせを試してみます。
概要
Terraform CDKとは
Terraform CDKとは汎用のプログラミング言語を用い、Terraform(+エコシステム)を通じてクラウドなどの各種プラットフォームを操作するためのツールです。
サポートされているプログラミング言語としては以下のようなものがあります。
Terraform CDKの位置付け/立ち位置
AWS CDKが汎用のプログラミング言語での定義からCloudFormationのコンフィグレーションを生成するのと同じく、 Terraform CDKは汎用のプログラミング言語での定義からTerraformのコンフィグレーションを生成します。
こちらの図にある通り、Terraformへの入力の一つという位置付けです。
 (出典: https://www.hashicorp.com/blog/cdk-for-terraform-enabling-python-and-typescript-support)
(出典: https://www.hashicorp.com/blog/cdk-for-terraform-enabling-python-and-typescript-support)
Terraformへの入力という位置付けなため、定義(dev)->プラン(plan)->適用(apply)というTerraformを用いたワークフローはそのまま利用する形です。
先ほどの記事にもThe goal of Terraform is to provide a consistent workflow for provisioning infrastructure(著者訳: Terraformのゴールはインフラのプロビジョニングに対し一貫したワークフローを提供することです)と章のはじめに書かれており、The Tao of HashiCorpにも書かれているワークフローへのこだわり(テクノロジーじゃない、ワークフローだ)を感じさせられます。
利用者は次に紹介するCLI cdktf を介してTerraformの各種コマンドを利用したり、Terraform向けのコードを(cdktf CLIで)生成して手動でTerraform CLIを実行するということも可能です。
Terraform CDKのツール
主に2つのパッケージが提供されています。
いずれもTypeScriptで実装されています。
CLIのヘルプはこんな感じです。
$ cdktf --help cdktf [command] Commands: cdktf deploy [OPTIONS] Deploy the given stack cdktf destroy [OPTIONS] Destroy the given stack cdktf diff [OPTIONS] Perform a diff (terraform plan) for the given stack cdktf get [OPTIONS] Generate CDK Constructs for Terraform providers and modules. cdktf init [OPTIONS] Create a new cdktf project from a template. cdktf login Retrieves an API token to connect to Terraform Cloud. cdktf synth [OPTIONS] Synthesizes Terraform code for the given app in a directory. [aliases: synthesize] Options: --version Show version number [boolean] --disable-logging Dont write log files. Supported using the env CDKTF_DISABLE_LOGGING. [boolean] [default: true] --disable-plugin-cache-env Dont set TF_PLUGIN_CACHE_DIR automatically. This is useful when the plugin cache is configured differently. Supported using the env CDKTF_DISABLE_PLUGIN_CACHE_ENV. [boolean] [default: false] --log-level Which log level should be written. Only supported via setting the env CDKTF_LOG_LEVEL [string] -h, --help Show help [boolean] Options can be specified via environment variables with the "CDKTF_" prefix (e.g. "CDKTF_OUTPUT")
CLIを用いた開発〜デプロイ(リソース作成)の基本的な流れは以下のようになります。
cdktf initで言語別のテンプレートからTerraform CDKプロジェクトを生成- 構成ファイル
cdktf.jsonに必要なTerraformプロバイダー/モジュールなどを定義 cdktf getでプロバイダー/モジュールの取得〜TypeScriptのコード生成(jsii向け)
(Note: Terraform CDKは多言語サポートのためにjsiiを利用しているため、一旦TypeScriptのコードが生成される)- 生成されたコードとライブラリの方の
cdktfを用いてインフラのリソース定義 cdktf deployして適用(またはcdktf synthでJSONを出力してterraform apply)
主要プロバイダー向けにはあらかじめコード生成済みのPrebuilt Providersも提供されています。
https://github.com/hashicorp/terraform-cdk/blob/main/docs/working-with-cdk-for-terraform/using-providers-and-modules.md#prebuilt-providers
例えばTypeScriptでリソース定義を行う場合以下のようなコードになります。
import { Construct } from "constructs"; import { App, TerraformStack } from "cdktf"; import { AwsProvider, Instance } from "./.gen/providers/aws"; class MyStack extends TerraformStack { constructor(scope: Construct, id: string) { super(scope, id); new AwsProvider(this, "aws", { region: "us-east-1", }); new Instance(this, "Hello", { ami: "ami-2757f631", instanceType: "t2.micro", }); } } const app = new App(); new MyStack(app, "hello-terraform"); app.synth();
細かな解説は省きますが、ポイントは以下のとおりです。
- aws/constructsを利用している
- ライブラリの方の
cdktfを利用している - 生成されたコードは
./.gen配下に格納される
利用するプロバイダーの定義とリソースの定義だけのシンプルな例となっています。
コードを追加すればステートの保存先としてリモート(Terraform CloudやS3など)を利用することも可能です。
Terraform Cloud利用時の注意点
現時点ではTerraform Cloud上でterraformコマンドを実行するExecution Mode=Remoteは利用できず、ステートだけをTerraform Cloudに保存するExecution Mode=Localのみ利
用可能です。
参考: terraform-cdk/remote-backend.md at 342b4cc71568cc73be93954901265f753e8709b4 · hashicorp/terraform-cdk · GitHub
利用例: Terraform CDK + さくらのクラウド + Java
ここでは例としてJavaを用いてさくらのクラウド上にリソースを作成してみます。
余談ですが類似プロダクトのPulumiではJavaはまだサポートされていません
事前準備(Javaのみ、今だけの暫定処置)
現時点ではTerraform CDK周りのライブラリがMavenセントラルに登録されておらずGitHub Packages(https://maven.pkg.github.com/hashicorp/terraform-cdk)での提供となります。
このため、事前にMavenからGitHub Packagesを利用できるようにするための設定が必要になります。
(この問題は将来的に解消予定とのこと)
UPDATE: 2021/10/20 久しぶりに確認したらすでにMaven Centralで公開されていました。
https://search.maven.org/artifact/com.hashicorp/cdktf
なので以下の~/.m2/settings.xmlの編集は不要になっています。
=== UPDATE ここまで
事前にGitHubのPersonal Access Tokenを取得した上で~/.m2/settings.xmlファイルを以下のようにしておいてください。(ファイルがなければ作成する)
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0 http://maven.apache.org/xsd/settings-1.0.0.xsd"> <activeProfiles> <activeProfile>github</activeProfile> </activeProfiles> <profiles> <profile> <id>github</id> <repositories> <repository> <id>central</id> <url>https://repo1.maven.org/maven2</url> </repository> <repository> <id>cdktf</id> <url>https://<GitHubユーザー名>:<アクセストークン>@maven.pkg.github.com/hashicorp/terraform-cdk</url> <snapshots> <enabled>true</enabled> </snapshots> </repository> </repositories> </profile> </profiles> </settings>
参考: Working with the Apache Maven registry - GitHub Docs
CLIのインストール
まずTerraform CDKのCLIをインストールしておきます。
通常はstable版をインストールするのですが、今回はこの記事執筆段階でTerraform CDK側の問題を見つけたため、その問題が解消されたv0.2.3以降が必要です。
本日(2021/4/16)時点ではv0.2.3は未リリースですのでstable版ではなく開発版をインストールします。
$ npm install --global cdktf-cli@next
開発用のディレクトリの作成 & 初期コードの生成
次にcdktfでプロジェクトの雛形を生成します。
適当なディレクトリを作成しcdktf initを実行してください。
# ステートの管理はローカル + 開発言語にはJavaを利用する $ cdktf init --local --template java
うまくいくと以下のようなファイル構成になっているはずです。
$ tree . . ├── cdktf.json ├── help ├── pom.xml ├── src │ └── main │ └── java │ └── com │ └── mycompany │ └── app │ └── Main.java └── target ├── cdk-work-java2-0.1.jar ├── classes │ └── com │ └── mycompany │ └── app │ └── Main.class ├── generated-sources │ └── annotations ├── maven-archiver │ └── pom.properties └── maven-status └── maven-compiler-plugin └── compile └── default-compile ├── createdFiles.lst └── inputFiles.lst
cdktf.jsonに依存プロバイダーを記載
次にカレントディレクトリに生成されているcdktf.jsonを編集します。
今回はさくらのクラウド向けプロバイダーを利用するのでterraformProvidersにsacloud/sakuracloud@~> 2.8と追記してください。
{ "language": "java", "app": "mvn -e -q compile exec:java", "terraformProviders": [ "sacloud/sakuracloud@~> 2.8" ], "terraformModules": [], "context": { "excludeStackIdFromLogicalIds": "true", "allowSepCharsInLogicalIds": "true" } }
cdktf getの実行
次にプロバイダーの取得~コード生成を行うためにcdktf getを実行します。
$ cdktf get
Generated java constructs in the output directory: .gen
通常は生成されたコードが.genディレクトリ配下にあるのですが、Javaの場合はsrc/main/java/imports.sakuracloud配下などに配置されています。
Javaでリソース定義
次にsrc/main/java/com/mycompany/app/Main.javaにコードを書いていきます。
今回はシンプルにスイッチを作るだけの例です。
package com.mycompany.app; import imports.sakuracloud.SakuracloudProvider; import imports.sakuracloud.Switch; import software.constructs.Construct; import com.hashicorp.cdktf.App; import com.hashicorp.cdktf.TerraformStack; public class Main extends TerraformStack { public Main(final Construct scope, final String id) { super(scope, id); // プロバイダーの定義 SakuracloudProvider.Builder.create(this, "default").build(); // リソースの定義 Switch.Builder.create(this, "testSwitch") .name("from-terraform-cdk-with-java") .description("this resource is created by terraform-cdk with java") .build(); } public static void main(String[] args) { final App app = new App(); new Main(app, "cdk-work-java"); app.synth(); } }
Terraformのコンフィギュレーションの生成(省略可能)
次に先ほど書いたコードからTerraformのコンフィギュレーションを生成してみます。
$ cdktf synth
Generated Terraform code in the output directory: cdktf.out
うまくいくとcdktf.outというディレクトリにcdk.tf.jsonというJSONファイルが生成されます。
$ tree cdktf.out/ cdktf.out/ └── cdk.tf.json 0 directories, 1 file
このファイルはTerraform CLIに直接渡せるものとなっています。
なお次のcdktf deployを実行するとsynthも実行されますのでこの工程は省略可能です。
cdktf deployでデプロイ
いよいよデプロイです。cdktf deployを実行します。
途中で実行して良いか聞かれますのでyesを入力します。
$ cdktf deploy Stack: cdk-work-java Resources + SAKURACLOUD_SWITCH testSwitch sakuracloud_switch.testSwitch Diff: 1 to create, 0 to update, 0 to delete. Do you want to perform these actions? CDK for Terraform will perform the actions described above. Only 'yes' will be accepted to approve. Enter a value: # yesと入力する # しばらく待つ Resources ✔ SAKURACLOUD_SWITCH testSwitch sakuracloud_switch.testSwitch Summary: 1 created, 0 updated, 0 destroyed.
デプロイできましたね!
今回はステートをローカルに保存するようにしましたので、カレントディレクトリにterraform.tfstateファイルが作成されているはずです。
後片付け: cdktf destroy
最後に忘れずに作成したリソースの削除を行っておきます。
こちらも途中で実行して良いか聞かれますのでyesと入力します。
$ cdktf destroy
これで削除されるはずです。
終わりに
今回はTerraform CDKの紹介とTerraform CDK+さくらのクラウドプロバイダーを利用する方法について紹介しました。
またまだ開発段階ということでちらほら気になる挙動があったりしますが、Pulumiと比べると既存のTerraformプロバイダーが利用しやすいと感じました。
(Pulumiの場合はブリッジを書く必要がある)
Terraformへの入力が変わるだけで既存のワークフロー(CI/CDなど)はそのまま利用できるのも嬉しいですね。
今後もう少し使い込んでみようかと思います。以上です。
: Developer Guide (English Edition)")
Packer v1.7 - initコマンドでプラグインをインストール
Packer v1.7からプラグインを特定のルールに沿って作成されたGitHub Releasesからダウンロード〜インストールできるpacker initコマンドが追加されました。
最近さくらのクラウド向けPackerプラグイン sacloud/packer-plugin-sakuracloudでこのpacker initに対応しましたので今回はその紹介をしていきます。
packer initコマンド
Packer v1.7からpacker initコマンドが追加されました。
従来はPackerに組み込まれていないビルダーやプロビジョナーなどのプラグインは手動でインストールしていましたが、packer initを実行することでプラグインのダウンロード〜インストールを行ってくれるようになりました。
Terraformにおけるterraform initみたいな感じです。
ただ、Packerには今の所状態を管理する機能はありませんのでpacker initはプラグインのインストールのみを行います。
また、プラグインのダウンロードは今の所GitHub上の公開リポジトリからのみ可能とのことです。
なおpacker initのドキュメントでは Currently って書いてあるのが目につくので、将来的にいろいろ拡張されそうな気配を感じます。
packer initの使い方
ドキュメントはこちらです。
まずpacker initを行うためにはいくつかの条件があります。
古くからあるJSONテンプレートでは利用できない点に注意が必要です。
これらの条件を満たすプラグインであれば、以下のようなrequired_pluginsブロックをテンプレートファイルに記載した上でpacker initでインストール可能です。
packer { required_plugins { sakuracloud = { version = ">= 0.7.0" source = "github.com/sacloud/sakuracloud" } } }
# プラグインのインストール
$ packer init template.pkr.hcl
なお、v1.7時点では従来Packer本体に組み込まれていたビルダーやプロビジョナーはまだ別リポジトリに分離されておらず、packer initなしで利用可能です。
また、packer initに対応していないプラグインでも手動インストールすることで利用は可能です。
ただし、Packer v1.7ではPacker本体とプラグインとの間の通信プロトコルのバージョンが変更されている(マイナーバージョンという概念が追加された)ため、古いプラグインはそのままだと利用できないケースもあります。
プラグインとの通信プロトコルバージョンによるエラーメッセージの例:
Error: Failed to load source type The protocol of this plugin (protocol version 4 and lower) was deprecated, please use a newer version of this plugin.Or use an older version of Packer (pre 1.7) with this plugin.
利用例: さくらのクラウド向けプラグイン
packer initの利用例としてさくらのクラウド向けプラグインでの利用方法を紹介します。
packer-plugin-sakuracloud v0.7からpacker initに対応しています。
(packer initに対応するために名称をpacker-builder-sakuracloudから変更しました)
以下のようなテンプレートを用意することでプラグインのインストール〜packer buildの実行が可能です。
# template.pkr.hcl # required_pluginブロックで利用するプラグインを宣言 packer { required_plugins { sakuracloud = { version = ">= 0.7.0" source = "github.com/sacloud/sakuracloud" } } } source "sakuracloud" "example" { zone = "is1a" os_type = "centos8" password = "input-your-password" disk_size = 20 disk_plan = "ssd" core = 1 memory_size = 1 archive_name = "packer-example-centos" archive_description = "description of archive" } build { sources = [ "source.sakuracloud.example" ] provisioner "shell" { inline = [ "echo 'hello!'", ] } }
テンプレートを用意し以下のコマンドで実行していきます。
# APIキーを環境変数に設定 $ export SAKURACLOUD_ACCESS_TOKEN=xxx $ export SAKURACLOUD_ACCESS_TOKEN_SECRET=xxx # プラグインのインストール $ packer init template.pkr.hcl Installed plugin github.com/sacloud/sakuracloud v0.7.0 in "~/.packer.d/plugins/github.com/sacloud/sakuracloud/packer-plugin-sakuracloud_v0.7.0_x5.0_darwin_amd64" # buildの実行 $ packer build template.pkr.hcl
従来の手動インストールと比べると手軽に利用できるようになりました。
GitHub Container Registryでのpacker-plugin-sakuracloudのDockerイメージの配布
なおpacker-plugin-sakuracloud v0.7からDockerHubに加えGitHub Container RegistryでのDockerイメージ配布も行われるようになりました。
Dockerで利用する場合は次のようなコマンドで実行します。
$ docker run -it --rm \ -e SAKURACLOUD_ACCESS_TOKEN \ -e SAKURACLOUD_ACCESS_TOKEN_SECRET \ -v $PWD:/work \ -w /work \ ghcr.io/sacloud/packer:latest build template.pkr.hcl
ベースイメージにhashicorp/packer:lightを使うようになりました。
従来通りのsacloud/packerも継続して利用可能です。
(プラグイン開発者向け)プラグイン側がpacker initに対応するには
Packerプラグインがpacker initに対応するにはいくつかの条件があります。
- Packer Plugin SDKに対応していること
(かつmulti-component RPC serverであること) - プラグインのバイナリの名前が
packer-plugin-*という形式(従来はpacker-builder-*やpacker-provisioner-*だった)であること
(これはmulti-component pluginsと呼ばれる。従来のものはsingle-component plugins) - 所定の手順でGitHub Releasesでリリースすること
詳細は以下のドキュメントに記載されています。
新しくプラグインを作成する場合はscaffoldが提供されています。
Packer v1.6以前にプラグインを提供していた場合向けの移行ガイドやPacker Plugin SDKへのマイグレーションツールも提供されています。
packer initに対応するかはともかくとしても、Packer Plugin SDKへの移行はしておかないとPacker v1.7でエラー(The protocol of this plugin~)がでるようですので
Packer v1.6以前のプラグインは早めにマイグレーションした方が良さそうです。
以上です。
BBC micro:bit v2でmruby/cを動かしてみる
最近息子と一緒にBBC micro:bitを触って遊んでいます。
今日はこのmicro:bit上でmruby/cを動かしてみましたのでメモを残しておきます。
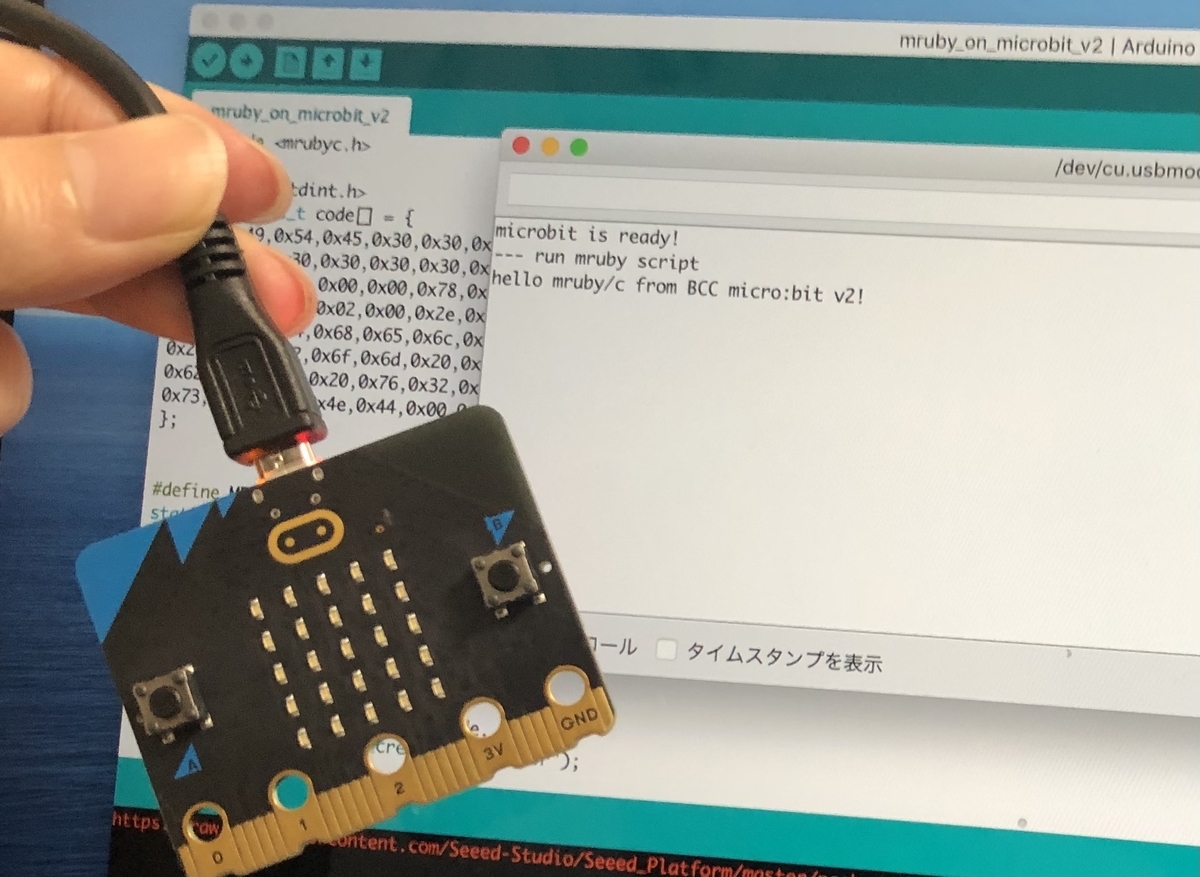
(写真撮ったあとにBBCをBCCにtypoしてるのに気付きました。。。)
はじめに
micro:bitとは
micro:bitはBBC(英国放送協会)が主体となって開発されたシングルボードコンピューターです。学校での情報教育(プログラミング)などで利用されているとのことです。
バージョンアップ版 正規品!")
MICRO-BIT V2 (マイクロビット)バージョンアップ版 正規品!
- メディア: エレクトロニクス
こちらのスイッチエデュケーションさんのサイトに特徴がまとめられています。
micro:bit の特徴
- LEDやボタン、センサーなどをあらかじめ搭載しています
- パソコンやタブレット、さまざまな環境でプログラミングできます
- 段階的にプログラミングを学ぶことができます
- 拡張パーツをつなげれば、さまざまな作品を作ることができます
値段も2,000円程度(執筆時点)と手ごろな価格になっており、手軽に触り始めることが出来ます。


こちらはRaspberry Piと比べてみた写真です。手のひらサイズですね。

ブロックを用いたビジュアルプログラミングができるMakeCodeやMicroPythonを利用可能なので子供のプログラミング&電子工作入門に良さそうと思い購入しました。
mruby/cとは
mruby/cとは、軽量Rubyであるmrubyをさらに組み込み機器向けに軽量化したmrubyの実装とのことです。
こちらの記事でWio LTE上で動かしているのを読んでmicro:bit上でも動かせるんじゃないか?と思ったのが今回のきっかけです。
magazine.rubyist.net
ということで早速micro:bit上でmruby/cを動かしてみます。
準備
先ほどのRubyist Magagineの記事を参考に、開発環境にはArduino IDEを利用します。
必要なもの
Arduino IDEでmicro:bit v2を使えるようにする
まずはArduino IDEでmicro:bit v2を使えるようにするためにsandeepmistry/arduino-nRF5をインストールします。
Arduinoの環境設定ダイアログを開き、追加のボードマネージャのURLに以下を入力します。
https://sandeepmistry.github.io/arduino-nRF5/package_nRF5_boards_index.json
注: 既に他のURLが入力されている場合、カンマ区切りで後ろに追記してください。
これでツール -> ボード -> Nordic Semiconductor nRF5 boardsという項目の中からBBC micro:bit V2が選べるようになっているはずです。
mruby/cをmicro:bit v2へ移植
次にmruby/cをmicro:bit v2へ移植します。
- mruby/cのソースを取得
- HALを実装
- Arduinoのライブラリにする
mruby/cのソースを取得
次にmruby/cのソースを取得します。
git clone https://github.com/mrubyc/mrubyc.git
今回は何も考えずmasterを利用しました。エラーが出るようならタグが付けられたバージョンを使おうと思ったのですが、幸い特にエラーは起きなかったのでそのままmasterを使いました。
HAL(Hardware Abstraction Layer)の実装
mruby/cにはHALとして以下のものが用意されていました。
- hal_esp32
- hal_pic24
- hal_posix
- hal_psoc5lp
これらを参照しつつmicro:bit(nRF52833)向けにHALを実装します。
実装手順
既存のsrc/hal_*ディレクトリを削除
まずsrc/hal_*ディレクトリを削除してしまいます。
(残しておくとArduino IDEでエラーが出たため。原因を調べるのが面倒だったので削除しちゃいました)
既存のsrc/hal_selector.hの修正
次にsrc/hal_selector.hを以下のように修正します。
/*! @file <pre> Copyright (C) 2016-2020 Kyushu Institute of Technology. Copyright (C) 2016-2020 Shimane IT Open-Innovation Center. This file is distributed under BSD 3-Clause License. </pre> */ // 以下をごっそり削りhal/hal.hのincludeだけにする #include "hal/hal.h"
本来はどのHALを使うのかの判定が入っているのですが、今回はごっそり削ってhal/hal.hを決め打ちしました。
src/halディレクトリの作成 & hal.h/hal.c/hal.cppの作成
次にsrc/halディレクトリを作成し、その中にhal.h/hal.c/hal.cppを作成していきます。
hal.h
/*! @file https://github.com/mrubyc/mrubyc/blob/master/src/hal_posix/hal.hを参考に実装 オリジナルのライセンス表記は以下のとおり Copyright (C) 2016-2020 Kyushu Institute of Technology. Copyright (C) 2016-2020 Shimane IT Open-Innovation Center. This file is distributed under BSD 3-Clause License. */ #ifndef MRBC_SRC_HAL_H_ #define MRBC_SRC_HAL_H_ #ifdef __cplusplus extern "C" { #endif /***** Macros ***************************************************************/ #if !defined(MRBC_TICK_UNIT) #define MRBC_TICK_UNIT_1_MS 1 #define MRBC_TICK_UNIT_2_MS 2 #define MRBC_TICK_UNIT_4_MS 4 #define MRBC_TICK_UNIT_10_MS 10 // You may be able to reduce power consumption if you configure // MRBC_TICK_UNIT_2_MS or larger. #define MRBC_TICK_UNIT MRBC_TICK_UNIT_1_MS // Substantial timeslice value (millisecond) will be // MRBC_TICK_UNIT * MRBC_TIMESLICE_TICK_COUNT (+ Jitter). // MRBC_TIMESLICE_TICK_COUNT must be natural number // (recommended value is from 1 to 10). #define MRBC_TIMESLICE_TICK_COUNT 10 #endif #if !defined(MRBC_NO_TIMER) // use hardware timer. # define hal_init() ((void)0) # define hal_enable_irq() ((void)0) # define hal_disable_irq() ((void)0) # define hal_idle_cpu() ((void)0) #else // MRBC_NO_TIMER # define hal_init() ((void)0) # define hal_enable_irq() ((void)0) # define hal_disable_irq() ((void)0) # define hal_idle_cpu() ((void)0) #endif /***** Function prototypes **************************************************/ int hal_write(int fd, const void *buf, int nbytes); int hal_flush(int fd); #ifdef __cplusplus } #endif #endif // ifndef MRBC_SRC_HAL_H_
本来はhal_*()達を実装すべきなのですが、今回はとりあえず動かすことが目的なので((void)0)で済ませてます。
動作確認のためにシリアル出力は行いたいのでhal_write()とhal_flush()だけは実装します。
hal.c
/* https://github.com/kishima/libmrubycForWioLTEArduino/blob/master/src/hal/hal.cを参考に実装 オリジナルのライセンス表記: https://github.com/kishima/libmrubycForWioLTEArduino/blob/master/LICENSE */ #include "hal.h" int hal_write(int fd, const void *buf, int nbytes) { char* t = (char*)buf; char tbuf[2]; if(nbytes==1){ tbuf[0]=*t; tbuf[1]='\0'; hal_write_string(tbuf); return nbytes; } hal_write_string(t); return nbytes; } int hal_flush(int fd) { hal_serial_flush(); }
前述のRubyist Magazineの記事を参考に実装してみました。
hal_write_string()とhal_serial_flush()はこのあとhal.cppで実装します。
hal.cpp
/* https://github.com/kishima/libmrubycForWioLTEArduino/blob/master/src/hal/hal.cppを参考に実装 オリジナルのライセンス表記: https://github.com/kishima/libmrubycForWioLTEArduino/blob/master/LICENSE Copyright (c) 2018, katsuhiko kageyama All rights reserved. */ #include <Arduino.h> extern "C" void hal_write_string(char* text){ Serial.write(text); } extern "C" void hal_serial_flush(char* text){ Serial.flush(); }
こちらも最低限の実装となってます。
とりあえずこれで最低限動くはずです。
Arduinoのライブラリにする
次にmruby/cをArduinoから使うために先ほど移植したソースをArduinoのライブラリにします。
ここもほぼ前述のRubyist Magazineの記事の通りに進めます。
Arduinoのライブラリディレクトリ(macの場合~/Documents/Arduino/libraries、Windowsの場合はC:¥Users¥ユーザー名¥Documents¥Arduino¥librariesなど)にlibmrubycなどという名前でディレクトリを作成します。
そのディレクトリ内に先ほど修正したソース達とlibrary.propertiesというテキストファイルを格納します。
library.propertiesの作成
以下のような内容にします。
name=mruby/c for Micro:Bit v2 version=0.0.1 author=yamamoto-febc maintainer=yamamoto-febc sentence=mruby/c implementation for BBC Micro:Bit v2. paragraph= category=Communication url=https://github.com/yamamoto-febc/libmrubyc architectures=* includes=mrubyc.h
修正したmruby/cのsrcディレクトリをコピー
次にmruby/cのsrcディレクトリをコピーします。
最終的に以下のようなファイル構成になっているはずです。
(~/Documents/Arduino/など)/libraries/
├── library.properties // 作成したファイル
└── src // mruby/cのsrcからコピーしたもの
これでArduino IDEを再起動するとライブラリとして認識されているはずです。
mruby/cのコード作成〜バイトコード生成〜Arduinoのスケッチ作成
Arduinoの準備が出来たのでいよいよmruby/cのコードを書いてみます。
今回は以下のようにputsするだけです。
puts "hello mruby/c from BBC micro:bit v2!"
これをhello.rbとして作成します。
そしてこのファイルをmrbcコマンドに渡してmruby/cに渡すバイトコードを生成します。
$ mrbc -E -B code hello.rb
これでカレントディレクトリにhello.cが作成されているはずです。
これを後ほどArduinoスケッチに貼り付けます。
TIPS: mrbcコマンドで-e/-E option no longer neededというエラーが出る
おそらくmruby v2.1.2以降を利用しています。
参考: https://github.com/mruby/mruby/commit/48c473a0c4abc67614a00d282d24d18089908449
mruby v2.1.1を利用するようにしてください。
次にArduinoのスケッチを作成します。
/* https://github.com/kishima/libmrubycForWioLTEArduino/blob/master/examples/controlLED/controlLED.inoを参考に実装 オリジナルのライセンス表記: https://github.com/kishima/libmrubycForWioLTEArduino/blob/master/LICENSE */ #include <mrubyc.h> /* ここに先ほど生成したhello.cの内容を貼り付ける */ void setup() { delay(100); Serial.begin(9600); Serial.println("microbit is ready!"); mrbc_init(mempool, MEMSIZE); if(NULL == mrbc_create_task( code, 0 )){ Serial.println("mrbc_create_task error"); return; } Serial.println("--- run mruby script"); mrbc_run(); } void loop() { delay(1000); }
スケッチの中に先ほど生成したhello.cの内容をそのまま貼り付けてください。
私の手元の環境では最終的なスケッチは以下のようになりました。
/* https://github.com/kishima/libmrubycForWioLTEArduino/blob/master/examples/controlLED/controlLED.inoを参考に実装 オリジナルのライセンス表記: https://github.com/kishima/libmrubycForWioLTEArduino/blob/master/LICENSE */ #include <mrubyc.h> #include <stdint.h> const uint8_t code[] = { 0x52,0x49,0x54,0x45,0x30,0x30,0x30,0x36,0xef,0x0a,0x00,0x00,0x00,0x7a,0x4d,0x41, 0x54,0x5a,0x30,0x30,0x30,0x30,0x49,0x52,0x45,0x50,0x00,0x00,0x00,0x5c,0x30,0x30, 0x30,0x32,0x00,0x00,0x00,0x78,0x00,0x01,0x00,0x04,0x00,0x00,0x00,0x00,0x00,0x0c, 0x10,0x01,0x4f,0x02,0x00,0x2e,0x01,0x00,0x01,0x37,0x01,0x67,0x00,0x00,0x00,0x01, 0x00,0x00,0x24,0x68,0x65,0x6c,0x6c,0x6f,0x20,0x6d,0x72,0x75,0x62,0x79,0x2f,0x63, 0x20,0x66,0x72,0x6f,0x6d,0x20,0x42,0x43,0x43,0x20,0x6d,0x69,0x63,0x72,0x6f,0x3a, 0x62,0x69,0x74,0x20,0x76,0x32,0x21,0x00,0x00,0x00,0x01,0x00,0x04,0x70,0x75,0x74, 0x73,0x00,0x45,0x4e,0x44,0x00,0x00,0x00,0x00,0x08, }; #define MEMSIZE (1024*50) static uint8_t mempool[MEMSIZE]; void setup() { // 省略 } void loop() { // 省略 }
実機で動かしてみる
あとはmicro:bitに転送して動かすだけです。 うまくいけばシリアルモニタに文字が表示されるはずです。
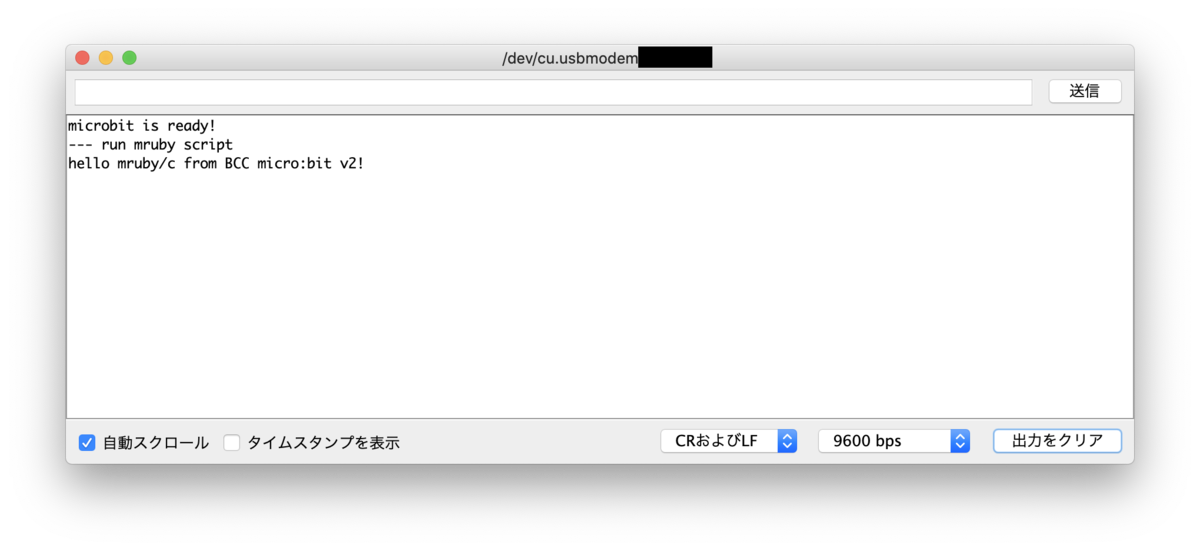
TIPS: Error: Illegal bytecodeというエラーが出る
hello.cのコピペミスやmrubyのバージョン違いの可能性があります。
最初mrubyの最新版(2.1.2)を使ってたらこのエラーが出ました。
mruby/c側が(記事執筆時点のmasterでは)mruby v2.1.1のバイトコード(RITE0006)を期待してるんですね。
参考: https://github.com/mrubyc/mrubyc/blob/228645971e0005cc743cfa653c99ff2b78ae02a0/src/load.c#L54-L57
終わりに
ということでmicro:bit v2上でmruby/cを動かしてみました。
このままだとシリアル出力しか出来ないのでもうちょっと色々書く必要がありますが、とりあえずmruby/cを使っていくためのスタートラインには立てたんじゃないかなと思います。
参考にした記事/サイト
- mruby/c | しまねソフト研究開発センター
- mruby/cで始めるオリジナルIoTデバイス作り
- GitHub - sandeepmistry/arduino-nRF5: Arduino Core for Nordic Semiconductor nRF5 based boards
↓↓この辺はこの記事書いてる時に見つけました。書き始める前に読みたかった。。。
以上です。
MICRO-BIT V2 (マイクロビット)バージョンアップ版 正規品!
- メディア: エレクトロニクス
Goで書いたWASMでfmt.Println()してからブラウザのコンソールに出力するまでを追う
先日さくらのクラウド向けCLI Usacloudをブラウザ上で動かせるChrome拡張UsaConをリリースしました。
このUsaConを作る際にいろいろ調べたことを備忘をかねて書いておきます。
(もし間違えている箇所などあったらご指摘いただけると嬉しいです。)
今回はfmt.Println()でHello WorldするだけのWASMを題材に、fmt.Println()からWebブラウザで出力されるまでのコードを追ってみます。
今回の環境
- Go: 1.15.6
- ブラウザ(動作確認用): Chrome 87
今回の題材アプリ
Hello Worldするだけの単純なアプリをWASMをしてビルドして実行します。
コードは↓↓だけの非常に単純なものです。
package main import "fmt" func main() { fmt.Println("hello wasm!") }
あとはこれをビルドしてブラウザから実行可能にします。
実行にはGoに付属しているwasm_exec.htmlとwasm_exec.jsを利用します。
この辺は以下のページに手順が書いてますので気になる方は参照してください。
WebAssembly · golang/go Wiki · GitHub
ビルドして実行可能にするまでの詳細はこちら(読み飛ばし可)
GOOSとGOARCHをセットしてビルド
$ GOOS=js GOARCH=wasm go build -o test.wasm main.go
Goに付属しているwasm_exec.htmlとwasm_exec.jsをコピー
$ cp `go env GOPATH`/misc/wasm/wasm_exec.html ./ $ cp `go env GOPATH`/misc/wasm/wasm_exec.js ./
適当なWebサーバを起動
ここでは前述のWikiに従いgoexecを利用する形にしています。
既存のWebサーバを使う形やnpmでserveを使ったりする形でもOKです。
# install goexec $ go get -u github.com/shurcooL/goexec
$ goexec 'http.ListenAndServe(`:8080`, http.FileServer(http.Dir(`.`)))'
ブラウザで開く
$ open http://localhost:8080/wasm_exec.html
画面上のRunボタンをクリックするとブラウザのコンソールにhello wasm!を表示されるはずです。

fmt.Println()の中を追う
早速fmt.Println()の中身を追ってみます。
func Println(a ...interface{}) (n int, err error) { return Fprintln(os.Stdout, a...) } func Fprintln(w io.Writer, a ...interface{}) (n int, err error) { p := newPrinter() p.doPrintln(a) n, err = w.Write(p.buf) p.free() return }
os.Stdout(標準出力)のWrite()を呼んでますね。
ではWASMにした際の標準出力はどういう扱いになっているのでしょうか? まずこの辺をみていきます。
GOOS=js GOARCH=wasmの場合のos.Stdout
os.Stdoutの定義
os.Stdoutは*os.File型で、以下のように定義されています。
var ( Stdin = NewFile(uintptr(syscall.Stdin), "/dev/stdin") Stdout = NewFile(uintptr(syscall.Stdout), "/dev/stdout") Stderr = NewFile(uintptr(syscall.Stderr), "/dev/stderr") )
ソース: https://github.com/golang/go/blob/9b955d2d3fcff6a5bc8bce7bafdc4c634a28e95b/src/os/file.go#L62-L66
syscall.Stdoutは以下のとおりです。
const ( Stdin = 0 Stdout = 1 Stderr = 2 )
別段変わったところはないですね。
NewFile()で何か変わったことをしているのでしょうか?
こちらも追ってみます。
os.NewFile()の実装の中身
// +build aix darwin dragonfly freebsd js,wasm linux netbsd openbsd solaris func NewFile(fd uintptr, name string) *File { kind := kindNewFile if nb, err := unix.IsNonblock(int(fd)); err == nil && nb { kind = kindNonBlock } return newFile(fd, name, kind) } func newFile(fd uintptr, name string, kind newFileKind) *File { fdi := int(fd) // ...中略... f := &File{&file{ pfd: poll.FD{ Sysfd: fdi, IsStream: true, ZeroReadIsEOF: true, }, name: name, stdoutOrErr: fdi == 1 || fdi == 2, }} // ...中略... // poll.FDのInitを呼んできる if err := f.pfd.Init("file", pollable); err != nil { // ...中略... } }
ソース: https://github.com/golang/go/blob/go1.15.6/src/os/file_unix.go
こちらはビルドタグ(ソース先頭のやつ)が+build aix darwin dragonfly freebsd js,wasm linux netbsd openbsd solarisとなっていますので、WASM用に特別なことをしてるわけじゃないですね。
もう少し中の方ではWASM向けに分岐しているのですが、今回は省略します。
次は*os.FileのWrite()がどう実装されているか見ていきます。
*os.FileのWrite()の実装
*os.FileのWrite()
go/src/os/file.goで実装されています。
func (f *File) Write(b []byte) (n int, err error) { // ...中略... n, e := f.write(b) // ...中略... }
ソース: https://github.com/golang/go/blob/9b955d2d3fcff6a5bc8bce7bafdc4c634a28e95b/src/os/file.go#L173
write()が呼ばれてるのでそちらを見てみます。
*os.Fileのwrite()
今度はgo/src/os/file_posix.go
func (f *File) write(b []byte) (n int, err error) { // poll.FDのWriteを呼んでいる n, err = f.pfd.Write(b) // ...中略... }
ソース: https://github.com/golang/go/blob/9b955d2d3fcff6a5bc8bce7bafdc4c634a28e95b/src/os/file_posix.go#L48
f.pfd.Write()が呼ばれています。
*os.Fileのpfdフィールドはos.NewFile()の中でこっそり登場していましたね。
ソース: https://github.com/golang/go/blob/9b955d2d3fcff6a5bc8bce7bafdc4c634a28e95b/src/os/file_unix.go#L114-L118
次にpoll.FDのWrite()を見てみます。
poll.FDのWrite()
// +build aix darwin dragonfly freebsd js,wasm linux netbsd openbsd solaris // Write implements io.Writer. func (fd *FD) Write(p []byte) (int, error) { // ...中略... // syscall.Writeを呼んでいる n, err := ignoringEINTR(func() (int, error) { return syscall.Write(fd.Sysfd, p[nn:max]) }) // ...中略...
syscall.Write()が呼ばれています。
GOOS=js GOARCH=wasmの場合のsyscall.Write()
go/src/syscall/fs_js.goで実装されています。
func Write(fd int, b []byte) (int, error) { // ...中略... // jsに値を渡す js.CopyBytesToJS(buf, b) // fsCall?? n, err := fsCall("write", fd, buf, 0, len(b), nil) // ...中略... }
ここでようやくWASMっぽい部分が出てきました。
js.CopyBytesToJS()でバッファに値を入れてfsCall("write", ...)してます。
ちょっと寄り道: GoでビルドしたWASMとJavaScriptの値のやりとりはどうやってるの?
WASM/JavaScript両方からアクセスできるメモリ領域を介して値のやりとりをしています。
参考: WebAssembly.Memory
GoでビルドしたWASMの場合は、memという名前でこのMemoryがエクスポートされています。

先ほど出てきたjs.CopyBytesToJS()はこの共有メモリ領域への書き込みを行なっています。
jsからも読み書きできるところにデータを書いておいてfsCall("write", ...)を呼んでいるということですね。
次にfsCall("write", ...)を追ってみます。
fsCall("write", ...)の実装
fsCallは以下のように実装されています。
func fsCall(name string, args ...interface{}) (js.Value, error) { // ...中略... // jsFSのCallを呼んでる jsFS.Call(name, append(args, f)...) // ...中略... }
jsFSはこちらです。
var jsFS = js.Global().Get("fs")
ソース: https://github.com/golang/go/blob/9b955d2d3fcff6a5bc8bce7bafdc4c634a28e95b/src/syscall/fs_js.go#L20
syscall.jsパッケージのGlobal()経由でGet("fs")してます。
syscal/js
syscall.jsでGlobal()は以下のように定義されています。
func Global() Value { return valueGlobal } var ( // valueGlobalは106行目で定義されている valueGlobal = predefValue(5, typeFlagObject)
syscall/jsのValue型ですね。ValueのGet()は以下のように実装されています。
func (v Value) Get(p string) Value { // ...中略... r := makeValue(valueGet(v.ref, p)) // ...中略... } func valueGet(v ref, p string) ref
最終的にvalueGet()を呼んでいます。
funcのボディがないですが、これはasmで実装されています。
TEXT ·valueGet(SB), NOSPLIT, $0 CallImport RET
CallImportというやつがいますね。これは最終的にWebAssemblyにインポートしているfuncを呼ぶようになっているみたいです。
(この辺はまだちゃんと追えていません…)
インポートしてるfuncというのは、JavaScriptでWebAssemblyのインスタンスを作る時に使うWebAssembly.instantiateStreaming()の引数で渡すやつですね。
参考: MDN: WebAssembly.instantiateStreaming()
GoでビルドしたWASMの場合は、wasm_exec.jsの中で定義されているものを利用することになります。
global.Go = class {
constructor() {
// ...中略...
this.importObject = {
go: {
// func valueGet(v ref, p string) ref
"syscall/js.valueGet": (sp) => {
const result = Reflect.get(loadValue(sp + 8), loadString(sp + 16));
sp = this._inst.exports.getsp();
storeValue(sp + 32, result);
},
// func copyBytesToJS(dst ref, src []byte) (int, bool)
"syscall/js.copyBytesToJS": (sp) => {
const dst = loadValue(sp + 8);
const src = loadSlice(sp + 16);
if (!(dst instanceof Uint8Array || dst instanceof Uint8ClampedArray)) {
this.mem.setUint8(sp + 48, 0);
return;
}
const toCopy = src.subarray(0, dst.length);
dst.set(toCopy);
setInt64(sp + 40, toCopy.length);
this.mem.setUint8(sp + 48, 1);
},
}
};
}
// ...中略...
先ほど出てきたcopyBytesToJSもここで定義されていますね。
ということで最終的にjs上で定義されたfuncを呼ぶということがわかりました。
fsCall("write", ...)の実装(再び)
ということで改めてfsCall("write", ...)の実装を見てみます。
func fsCall(name string, args ...interface{}) (js.Value, error) { // ...中略... // jsFS.Call("write", ...)という引数になっている jsFS.Call(name, append(args, f)...) // ...中略... } var jsFS = js.Global().Get("fs")
js.Global().Get("fs")はjs上で定義されたvalueGet()を呼んでいました。 ここでjs上のglobal.jsを取得しています。取得したglobal.jsに対してCall("write", ...)してます。
これによりjs上のglobal.fsのwrite()を呼ぶようになっています。
ゴール: js上でconsole.log()を呼ぶ部分
global.fsには何が入ってる?
ブラウザ上で実行している場合は前述のwasm_exec.jsにより以下のように定義されています。
if (!global.fs) {
let outputBuf = "";
global.fs = {
constants: { O_WRONLY: -1, O_RDWR: -1, O_CREAT: -1, O_TRUNC: -1, O_APPEND: -1, O_EXCL: -1 }, // unused
writeSync(fd, buf) {
outputBuf += decoder.decode(buf);
const nl = outputBuf.lastIndexOf("\n");
if (nl != -1) {
console.log(outputBuf.substr(0, nl));
outputBuf = outputBuf.substr(nl + 1);
}
return buf.length;
},
write(fd, buf, offset, length, position, callback) {
if (offset !== 0 || length !== buf.length || position !== null) {
callback(enosys());
return;
}
const n = this.writeSync(fd, buf);
callback(null, n);
},
chmod(path, mode, callback) { callback(enosys()); },
chown(path, uid, gid, callback) { callback(enosys()); },
close(fd, callback) { callback(enosys()); },
fchmod(fd, mode, callback) { callback(enosys()); },
fchown(fd, uid, gid, callback) { callback(enosys()); },
fstat(fd, callback) { callback(enosys()); },
fsync(fd, callback) { callback(null); },
ftruncate(fd, length, callback) { callback(enosys()); },
lchown(path, uid, gid, callback) { callback(enosys()); },
link(path, link, callback) { callback(enosys()); },
lstat(path, callback) { callback(enosys()); },
mkdir(path, perm, callback) { callback(enosys()); },
open(path, flags, mode, callback) { callback(enosys()); },
read(fd, buffer, offset, length, position, callback) { callback(enosys()); },
readdir(path, callback) { callback(enosys()); },
readlink(path, callback) { callback(enosys()); },
rename(from, to, callback) { callback(enosys()); },
rmdir(path, callback) { callback(enosys()); },
stat(path, callback) { callback(enosys()); },
symlink(path, link, callback) { callback(enosys()); },
truncate(path, length, callback) { callback(enosys()); },
unlink(path, callback) { callback(enosys()); },
utimes(path, atime, mtime, callback) { callback(enosys()); },
};
}
global.fsが未定義だったら最低限の実装で埋めています。
write()は以下の部分です。
writeSync(fd, buf) {
outputBuf += decoder.decode(buf);
const nl = outputBuf.lastIndexOf("\n");
if (nl != -1) {
console.log(outputBuf.substr(0, nl));
outputBuf = outputBuf.substr(nl + 1);
}
return buf.length;
},
write(fd, buf, offset, length, position, callback) {
if (offset !== 0 || length !== buf.length || position !== null) {
callback(enosys());
return;
}
const n = this.writeSync(fd, buf);
callback(null, n);
},
write()はwriteSync()を呼び、最終的にconsole.log()されていますね。
長かったですがこれでGoのfmt.Println()からコンソール出力されるところまでたどり着きました。
まとめ
無理やりまとめると
fmt.Println()はsyscall.Write()を呼ぶsyscall(のGOOS=js GOARCH=wasm向けの実装)やsyscall/jsはjs側と協調して動作するようになっている- js側の基本的な実装は
wasm_exec.jsで行われている wasm_exec.jsでのglobal.fsの実装は最低限しかない
みたいな感じでしょうか。
ひとまずGoから標準出力に出力することでブラウザのコンソールに出力できることはわかりました。
でも上記の通りglobal.fsは最低限の実装しかないです。CLIの場合は標準入力から読んだり、その他のファイルを開いたりしたいことがあるかと思います。
CLIを動かしたい場合は自分で実装しないといけない部分が結構ありそうです。
次回以降の記事でUsaConでこの辺の問題をどう解決していったかを取り上げたいと思います。
今回は以上です。