続・さくらのクラウド上にMetabaseを構築する【HTTPS対応版】
前回はMetabase環境構築を行いました。
しかし、実運用の際はHTTPS対応は必須だと思いますので対応版を作りました。
Metabase環境構築 on さくらのクラウド(HTTPS版)
今回はLet's encryptにてHTTPS対応を行うバージョンとなっています。 Let's encrypt対応にはsteveltn/https-portalコンテナを利用します。
構築手順は前回とほぼ同じですが、あらかじめさくらのクラウド上にDNSゾーンの登録を行っておく必要があります。
テンプレート
前回との差分は以下の通りです。
- コメントを追加
- Let's encrypt用にDNS関連の記述を追加
- RancherOSのcloud-configにLet's encrypt用のコンテナを記述
### 概要
#
# データベースアプライアンス(PostgreSQL)とRancherOSでMetabase実行環境を構築するテンプレート
#
# このテンプレートはRancherOS上のDockerでMetabaseを実行する構成となっています。
# Metabaseのバックエンドとしてデータベースアプライアンス(PostgreSQL)を利用します。
#
# MetabaseサーバのHTTPS対応としてLet's encryptでの証明書取得も行います。
#
# <事前準備>
#
# 1) さくらのクラウド上にSSH用の公開鍵を登録します。
# 2) さくらのクラウド上にDNSゾーンを登録しネームサーバの設定などを行っておきます。
# (すでに登録済みのゾーンがあればそれを利用可能です。)
#
# <構築手順>
# 1) リソースマネージャーにて新しいテンプレートを作成し、このtffileの内容を貼り付けます。
# 2) tffile編集画面の"変数定義"タブにて以下の値を編集します。
# - サーバ管理者のパスワード(server_password)
# - データベース接続ユーザーのパスワード(database_password)
# - さくらのクラウドに登録済みの公開鍵の名称(ssh_public_key_name)
# - さくらのクラウドに登録済みのDNSゾーン名(dns_zone_name)
# 3) リソースマネージャー画面にて"計画/反映"を実行
#
# <動作確認>
#
# ブラウザから以下のURLにアクセスするとMetabaseの画面が開きます。
# https://<MetabaseサーバのFQDN>/
#
# MetabaseサーバのFQDNは以下の形式です。
# ${server_name}.${dns_zone_name}
#
# FQDNの例:
# - server_name: "metabase"
# - dns_zone_name: "example.com"
# この場合FQDNは以下のようになります。
# FQDN: metabase.example.com
#
# <サーバへのSSH接続>
#
# サーバへのSSH接続は、指定した公開鍵による公開鍵認証のみ許可されるようになっています。
# SSH接続の際は秘密鍵を指定して接続してください。
#
# > usacloudでのSSH接続例
# $ usacloud server ssh -i <your-private-key-file> <your-server-name>
#
# SSH接続後はdocker logsコマンドなどでMetabaseコンテナのログを確認可能です。
#
### 変数定義
locals {
#*********************************************
# パスワード/公開鍵関連(要変更)
#*********************************************
# サーバ管理者のパスワード
server_password = "<put-your-password-here>"
# データベース接続ユーザーのパスワード
database_password = "<put-your-password-here>"
# さくらのクラウドに登録済みの公開鍵の名称
ssh_public_key_name = "<put-your-public-key-name>"
# さくらのクラウドに登録済みのDNSゾーン名
dns_zone_name = "<put-your-zone-name>"
#*********************************************
# サーバ/ディスク
#*********************************************
# サーバ名
server_name = "metabase"
# サーバホスト名
host_name = "${local.server_name}"
# サーバ コア数
server_core = 2
# サーバ メモリサイズ(GB)
server_memory = 4
# ディスクサイズ
disk_size = 20
#*********************************************
# ネットワーク(スイッチ/パケットフィルタ)
#*********************************************
# スイッチ名
switch_name = "metabase-internal"
# パケットフィルタ名
packet_filter_name = "metabase-filter"
#*********************************************
# データベースアプライアンス
#*********************************************
# データベースアプライアンス名
database_name = "metabase-db"
# プラン
database_plan = "30g" # 10g/30g/90g/240g
# 接続ユーザー名
database_user_name = "metabase"
# バックアップ時刻
database_backup_time = "01:00"
}
### サーバ/ディスク
# パブリックアーカイブ(OS)のID参照用のデータソース(RancherOS)
data sakuracloud_archive "rancheros" {
os_type = "rancheros"
}
# 公開鍵のID参照用のデータソース
data "sakuracloud_ssh_key" "ssh_public_key" {
name_selectors = ["${local.ssh_public_key_name}"]
}
# ディスク
resource "sakuracloud_disk" "disk" {
name = "${local.server_name}"
source_archive_id = "${data.sakuracloud_archive.rancheros.id}"
hostname = "${local.host_name}"
password = "${local.server_password}"
note_ids = ["${sakuracloud_note.provisioning.id}"]
ssh_key_ids = ["${data.sakuracloud_ssh_key.ssh_public_key.id}"]
disable_pw_auth = true
lifecycle {
ignore_changes = ["source_archive_id"]
}
}
# サーバ
resource "sakuracloud_server" "server" {
name = "${local.server_name}"
disks = ["${sakuracloud_disk.disk.id}"]
core = "${local.server_core}"
memory = "${local.server_memory}"
packet_filter_ids = ["${sakuracloud_packet_filter.filter.id}"]
additional_nics = ["${sakuracloud_switch.sw.id}"]
}
# スタートアップスクリプト(IP設定、metabaseコンテナ起動)
locals {
fqdn = "${local.server_name}.${local.dns_zone_name}"
}
resource "sakuracloud_note" "provisioning" {
name = "provisioning-metabase"
class = "yaml_cloud_config"
content = <<EOF
#cloud-config
rancher:
console: default
docker:
engine: docker-17.09.1-ce
network:
interfaces:
eth1:
address: 192.168.100.10/28
dhcp: false
services:
https-portal:
image: sacloud/https-portal
ports:
- "80:80"
- "443:443"
volumes:
- https-portal:/var/lib/https-portal
environment:
DOMAINS: "${local.fqdn} -> http://192.168.100.10:3000"
STAGE: production
restart: always
metabase:
image: metabase/metabase:latest
ports:
- "3000:3000"
environment:
MB_DB_TYPE: postgres
MB_DB_DBNAME: ${local.database_user_name}
MB_DB_PORT: 5432
MB_DB_USER: ${local.database_user_name}
MB_DB_PASS: ${local.database_password}
MB_DB_HOST: 192.168.100.2
restart: always
EOF
}
### データベースアプライアンス
resource "sakuracloud_database" "db" {
name = "${local.database_name}"
database_type = "postgresql"
plan = "${local.database_plan}"
user_name = "${local.database_user_name}"
user_password = "${local.database_password}"
allow_networks = ["192.168.100.0/28"]
port = 5432
backup_time = "${local.database_backup_time}"
switch_id = "${sakuracloud_switch.sw.id}"
ipaddress1 = "192.168.100.2"
nw_mask_len = 28
default_route = "192.168.100.1"
}
### パケットフィルタ
resource "sakuracloud_packet_filter" "filter" {
name = "${local.packet_filter_name}"
expressions = {
protocol = "tcp"
dest_port = "22"
description = "Allow external:SSH"
}
expressions = {
protocol = "tcp"
dest_port = "80"
description = "Allow external:HTTP(for Let's encrypt)"
}
expressions = {
protocol = "tcp"
dest_port = "443"
description = "Allow external:HTTPS"
}
expressions = {
protocol = "icmp"
}
expressions = {
protocol = "fragment"
}
expressions = {
protocol = "udp"
source_port = "123"
}
expressions = {
protocol = "tcp"
dest_port = "32768-61000"
description = "Allow from server"
}
expressions = {
protocol = "udp"
dest_port = "32768-61000"
description = "Allow from server"
}
expressions = {
protocol = "ip"
allow = false
description = "Deny ALL"
}
}
### スイッチ
resource sakuracloud_switch "sw" {
name = "${local.switch_name}"
}
### DNS
data sakuracloud_dns "zone" {
filter = {
name = "Name"
values = ["${local.dns_zone_name}"]
}
}
#DNSレコード
resource sakuracloud_dns_record "records" {
dns_id = "${data.sakuracloud_dns.zone.id}"
name = "${local.server_name}"
type = "A"
value = "${sakuracloud_server.server.ipaddress}"
}
後はリソースマネージャーで展開するだけでOKです。
以上です。
【リソースマネージャー対応】さくらのクラウド上にMetabaseを構築する
Metabaseが流行ってきてますね。記事もちらほら見かけるようになりました。
- OSSのデータ可視化ツール「Metabase」が超使いやすい - Qiita
- MetabaseがRedashの苦労を吹き飛ばすくらい熱い
- Metabase BIツールをAWS Elastic Beanstalkで構築してみた - Developers.IO
- Metabaseがすごく良い - itFun.jp
- MetabaseをAzure Web App for Containersで動かしてみた
ということでさくらのクラウド上にMetabaseを構築してみました。
===>【2018/1/30追記】HTTPS対応版について記事書きました。
続・さくらのクラウド上にMetabaseを構築する【HTTPS対応版】
ドメインをお持ちの方はこちらも是非お試しください。
<=== 追記ここまで
Metabase環境構築 on さくらのクラウド
今回はさくらのクラウドのリソースマネージャーを利用して環境構築してみました。
今回の環境
今回MetabaseはDockerで動かします。Docker用のホストはRancherOSを使用します。 Metabase用のデータベースとしてPostgreSQL(さくらのクラウド上のデータベースアプライアンス)を利用します。
構築手順は以下の通りです。
- 1) サーバへのSSH用公開鍵をコンパネから登録
- 2) リソースマネージャでテンプレート作成&反映
1) サーバへのSSH用公開鍵をコンパネから登録
サーバへのSSH接続時に利用する公開鍵をコンパネなどから登録しておきます。 登録時に指定した名前を控えておいてください。
2) リソースマネージャーでテンプレート作成&反映
続いてリソースマネージャーにてテンプレートを作成します。 以下のtfファイルをコピペで登録してください。 なおtfファイルの最初の方にパスワードや先ほど登録した公開鍵の名称を指定している部分があります。 忘れずに各自で置き換えてください。
### 概要
# データベースアプライアンス(PostgreSQL)とRancherOSでMetabase実行環境を構築するテンプレート
#
# このテンプレートはRancherOS上のDockerでMetabaseを実行する構成となっています。
# Metabaseのバックエンドとしてデータベースアプライアンス(PostgreSQL)を利用します。
#
### 変数定義
locals {
#*********************************************
# パスワード/公開鍵関連(!!!要変更!!!)
#*********************************************
# サーバ管理者のパスワード
server_password = "<put-your-password-here>"
# データベース接続ユーザーのパスワード
database_password = "<put-your-password-here>"
# さくらのクラウドに登録済みの公開鍵の名称
ssh_public_key_name = "<put-your-public-key-name>"
#*********************************************
# サーバ/ディスク
#*********************************************
# サーバ名
server_name = "metabase-server"
# サーバホスト名
host_name = "${local.server_name}"
# サーバ コア数
server_core = 2
# サーバ メモリサイズ(GB)
server_memory = 4
# ディスクサイズ
disk_size = 20
#*********************************************
# ネットワーク(スイッチ/パケットフィルタ)
#*********************************************
# スイッチ名
switch_name = "metabase-internal"
# パケットフィルタ名
packet_filter_name = "metabase-filter"
#*********************************************
# データベースアプライアンス
#*********************************************
# データベースアプライアンス名
database_name = "metabase-db"
# プラン
database_plan = "30g" # 10g/30g/90g/240g
# 接続ユーザー名
database_user_name = "metabase"
# バックアップ時刻
database_backup_time = "01:00"
}
### サーバ/ディスク
# パブリックアーカイブ(OS)のID参照用のデータソース(RancherOS)
data sakuracloud_archive "rancheros" {
os_type = "rancheros"
}
# 公開鍵のID参照用のデータソース
data "sakuracloud_ssh_key" "ssh_public_key" {
name_selectors = ["${local.ssh_public_key_name}"]
}
# ディスク
resource "sakuracloud_disk" "disk" {
name = "${local.server_name}"
source_archive_id = "${data.sakuracloud_archive.rancheros.id}"
hostname = "${local.host_name}"
password = "${local.server_password}"
note_ids = ["${sakuracloud_note.provisioning.id}"]
ssh_key_ids = ["${data.sakuracloud_ssh_key.ssh_public_key.id}"]
disable_pw_auth = true
lifecycle {
ignore_changes = ["source_archive_id"]
}
}
# サーバ
resource "sakuracloud_server" "server" {
name = "${local.server_name}"
disks = ["${sakuracloud_disk.disk.id}"]
core = "${local.server_core}"
memory = "${local.server_memory}"
packet_filter_ids = ["${sakuracloud_packet_filter.filter.id}"]
additional_nics = ["${sakuracloud_switch.sw.id}"]
}
# スタートアップスクリプト(IP設定、metabaseコンテナ起動)
resource "sakuracloud_note" "provisioning" {
name = "provisioning-metabase"
class = "yaml_cloud_config"
content = <<EOF
#cloud-config
rancher:
console: default
docker:
engine: docker-17.09.1-ce
network:
interfaces:
eth1:
address: 192.168.100.10/28
dhcp: false
services:
metabase:
image: metabase/metabase:latest
ports:
- "80:3000"
environment:
MB_DB_TYPE: postgres
MB_DB_DBNAME: metabase
MB_DB_PORT: 5432
MB_DB_USER: ${local.database_user_name}
MB_DB_PASS: ${local.database_password}
MB_DB_HOST: 192.168.100.2
restart: always
EOF
}
### データベースアプライアンス
resource "sakuracloud_database" "db" {
name = "${local.database_name}"
database_type = "postgresql"
plan = "${local.database_plan}"
user_name = "${local.database_user_name}"
user_password = "${local.database_password}"
allow_networks = ["192.168.100.0/28"]
port = 5432
backup_time = "${local.database_backup_time}"
switch_id = "${sakuracloud_switch.sw.id}"
ipaddress1 = "192.168.100.2"
nw_mask_len = 28
default_route = "192.168.100.1"
}
### ネットワーク(パケットフィルタ)
resource "sakuracloud_packet_filter" "filter" {
name = "${local.packet_filter_name}"
expressions = {
protocol = "tcp"
dest_port = "22"
description = "Allow external:SSH"
}
expressions = {
protocol = "tcp"
dest_port = "80"
description = "Allow external:HTTP"
}
expressions = {
protocol = "icmp"
}
expressions = {
protocol = "fragment"
}
expressions = {
protocol = "udp"
source_port = "123"
}
expressions = {
protocol = "tcp"
dest_port = "32768-61000"
description = "Allow from server"
}
expressions = {
protocol = "udp"
dest_port = "32768-61000"
description = "Allow from server"
}
expressions = {
protocol = "ip"
allow = false
description = "Deny ALL"
}
}
### ネットワーク(スイッチ)
resource sakuracloud_switch "sw" {
name = "${local.switch_name}"
}
tfファイル編集画面で「タブ分割/統合」ボタンを押すと以下のようにtfファイルをタブで分割してわかりやすく表示してくれます。 変更すべき内容は「変数定義」タブにまとめていますので目を通しておくのがオススメです。

登録後はリソースマネージャーのコマンドから計画/反映を実行するだけです。
なお、手元の環境では2分ほどで構築完了しました。
動作確認
構築が完了したらhttp://<サーバのグローバルIP>にアクセスするとmetabaseの画面が開くはずです。

後は画面に従って初期ユーザーの作成などを行うだけです。
終わりに
Metabaseいいですね! 以上です。
moby / linuxkit をさくらのクラウド対応させました

Linuxコンテナを実行できるコンテナプラットフォームを簡単に構築/展開できるmobyとlinuxkitをさくらのクラウドに対応させてみましたのでご紹介します。
(2017/10/23追記): システム要件としてDockerとGNU Makeのインストールが必要な旨を追記しました
TL; DR
以下のようにすればmobyとlinuxkitでさくらのクラウド上に簡単にコンテナプラットフォームを構築できます。
※あらかじめDockerとGNU Makeをインストールしておく必要があります。
# sacloud/linuxkitのインストール $ brew tap sacloud/linuxkit $ brew install --HEAD moby $ brew install --HEAD linuxkit # さくらのクラウドAPIキーを環境変数に設定 $ export SAKURACLOUD_ACCESS_TOKEN="your-token" $ export SAKURACLOUD_ACCESS_TOKEN_SECRET="your-secret" $ export SAKURACLOUD_ZONE="tk1a" # mobyコマンドでraw形式のイメージ作成 $ moby build -format raw -size 256M sakuracloud.yml # linuxkit pushでさくらのクラウド上にアップロード $ linuxkit push sakuracloud sakuracloud.raw # linuxkit runでさくらのクラウド上にサーバ作成/起動 $ linuxkit run sakuracloud sakuracloud
moby/linuxkitとは?
mobyとlinuxkitについてはPublickeyの以下の記事にわかりやすくまとめられています。
Publickey: Docker、「LinuxKit」を発表。コンテナランタイムのためだけにゼロから開発されたセキュアなLinux Subsystem。DockerCon 2017
全てがコンテナで実行される軽量でimmutableなLinuxイメージを作成できるツールとなっています。
どうやって使うの?
LinuxKitを使ってLinuxイメージを作成するためにmobyコマンドが提供されています。
mobyコマンドは、使用するカーネルやinitプロセス、動かしたいコンテナといった構成情報をyaml形式のファイルで定義し、定義に沿ったLinuxイメージを作成してくれます。
出力形式は以下のようなものがサポートされており、AWS/Azure/GCPといったクラウド上で利用できるイメージだけでなくOpenStackやオンプレのベアメタルサーバなどに対応できる形式のイメージが作成できます。
mobyコマンドで作成できるイメージの形式
作成したイメージはブータブルとなっており、自分でクラウド上にアップロードしたりオンプレの仮想化基盤に登録したりすることでイメージを利用したサーバを起動できるようになっています。
(ISOイメージで出力してCD/DVDなどのメディアを用意する方法も可能)
自分で(各クラウドの)コントロールパネルなどからアップロードしても良いですしCLIなどを利用してもよいですが、これらを簡単に行えるようにlinuxkitコマンドが用意されています。
linuxkitコマンドは何をするもの?
linuxkitコマンドは主にmobyコマンドで作成したイメージをクラウド(など)へアップロードし、そのイメージを用いて起動するサーバの作成を行ってくれます。
メタデータ用ISOイメージ作成や構成要素として利用できるパッケージ作成などの補助機能もあります。
イメージ作成〜サーバ起動までの利用イメージは以下のようになります。
# mobyコマンドでイメージ作成(example.rawファイルが作成される) $ moby build -format raw example.yml # linuxkit pushでアップロード $ linuxkit push aws -bucket bucketname example.raw # linuxkit runでアップロードしたイメージを利用したサーバを作成/起動 $ linuxkit run aws example
定義ファイル(yaml)の作り方についてはこちらのドキュメントに詳しく記載されています。
linuxkitドキュメント: Yaml Configuration Document
現時点では以下のクラウド(など)に対応しています。
イメージのアップロード(linuxkit push)対応先の一覧
イメージからのサーバ作成/起動(linuxkit run)対応先の一覧
標準ではさくらのクラウドに対応していませんので今回対応させてみました。
linuxkitのさくらのクラウド対応
以下のリポジトリにlinuxkitをforkしてさくらのクラウド対応を行っています。
このリポジトリを利用することでlinuxkitでさくらのクラウド上にイメージのアップロードを行いサーバ起動を行うことが可能となります。
sacloud/linuxkitのインストール
まずはforkしたsacloud/linuxkitのインストールを行う必要があります。 以下2つの方法があります。
- 方法1) homebrewを利用してインストール
- 方法2) 上記リポジトリをクローンして自分でビルド
方法1) homebrewでsacloud/linuxkitをインストール
本家linuxkitと同じくhomebrewでのインストールを行えるようにしています。
# まずはtap $ brew tap sacloud/linuxkit # インストール実施 $ brew install --HEAD moby $ brew install --HEAD linuxkit
もしすでにlinuxkit/linuxkitをtapしている場合は名前が衝突しますのでbrew install時に以下のように完全名で指定する必要があります。
$ brew install --HEAD sacloud/linuxkit/moby $ brew install --HEAD sacloud/linuxkit/linuxkit
方法2) sacloud/linuxkitをクローンして自分でビルド
ビルドにはGo言語の開発環境が必要です。$GOPATHの設定なども行っておく必要があります。
$GOPATH/src/github.com/linuxkit/linuxkitディレクトリにsacloud/linuxkitをクローンしてmakeを実行すればOKです。
# ディレクトリ作成 $ mkdir -p $GOPATH/src/github.com/linuxkit # クローン $ git clone https://github.com/sacloud/linuxkit.git $GOPATH/src/github.com/linuxkit/linuxkit # 移動 $ cd $GOPATH/src/github.com/linuxkit/linuxkit # ビルド(binディレクトリ配下にlinuxkit/mobyコマンドが作成される) $ make
必要に応じて$PATHの設定を行ってください。
sacloud/linuxkitの実行
あとは通常のmobyとlinuxkitと同様の手順でOKです。
システム要件もmobyとlinuxkitと同じく以下がインストールされていること、となっています。
なお、linuxkitでAzureを利用する場合などと同じくログイン情報(APIキー)を環境変数に登録しておく必要があります。
sacloud/linuxkitでは以下の環境変数の設定を行っておく必要があります。
さくらのクラウドのコントロールパネルでAPIキーを発行しておいてください。
(環境変数はusacloudやTerraform for さくらのクラウドと共通となっています)
# APIキー(アクセストークン) $ export SAKURACLOUD_ACCESS_TOKEN="your-access-token" # APIキー(アクセスシークレット) $ export SAKURACLOUD_ACCESS_TOKEN_SECRET="your-access-secret" # 対象ゾーン(石狩第1: is1a / 石狩第2: is1b / 東京第1: tk1a / サンドボックス: tk1v) $ export SAKURACLOUD_ZONE="tk1a"
イメージのビルド
定義ファイルを用意した上でmobyコマンドでビルドを行います。
定義ファイルの例をGitHub上で公開していますのでそれを元に作成してください。
さくらのクラウドでの定義ファイルの例: GitHub: sacloud/linuxkit/examples/sakuracloud.yml
kernel: image: linuxkit/kernel:4.9.56 cmdline: "console=tty0 console=ttyS0 console=ttyAMA0" init: - linuxkit/init:6b3755e47f00d6027321d3fca99a19af6504be75 - linuxkit/runc:52f92cb577879ce4cfe4e89be2d63af82523fc92 - linuxkit/containerd:ed8e8f92e24dd4b94260cf147594ae3fd13a2182 - linuxkit/ca-certificates:ea3c4c120f929f4f07ac8535d75933365b5e9582 onboot: - name: sysctl image: linuxkit/sysctl:1644bf07edbcaf5ce0bb764fa925b544183547f9 - name: rngd1 image: linuxkit/rngd:45ed7759dd927f4cce3863073ea2e0da1d52a427 command: ["/sbin/rngd", "-1"] services: - name: getty image: linuxkit/getty:7abaf7b276c59f80891d92e9279e3e3ee8e2f512 env: - INSECURE=true - name: rngd image: linuxkit/rngd:45ed7759dd927f4cce3863073ea2e0da1d52a427 - name: dhcpcd image: linuxkit/dhcpcd:aa685261ceb2557990dcfe9dd8824c6b9ec416e2 - name: sshd image: linuxkit/sshd:4a2fc7be31fa57dcade391de6173e0af55296e7f files: - path: root/.ssh/authorized_keys source: ~/.ssh/id_rsa.pub mode: "0600" optional: true trust: org: - linuxkit
この例はSSHDを起動するイメージの例となっています。
SSH用のキーペアをssh-keygenなどで作成し定義ファイルに公開鍵のファイルパスを記載してください。(デフォルトでは~/.ssh/id_rsa.pubが指定されています)
定義ファイルを作成したらmobyコマンドを実行します。
さくらのクラウドではAWSなどと同じく-formatオプションにrawを指定する必要があります。
# mobyコマンドでraw形式のイメージ作成 $ moby build -format raw -size 256M sakuracloud.yml
デフォルトでは定義ファイルの拡張子を除いたもの+.rawというファイル名でイメージが作成されます。
これは-nameオプションで上書き可能です。
また、イメージのサイズはデフォルトで1024M(1GB)となっています。
SSHを実行する程度のイメージであれば256Mもあれば十分ですので-sizeオプションでサイズを明示しています。
定義ファイルの内容によってこの値は調節する必要があります。
うまくいくとsakuracloud.rawというファイルが作成されるはずです。
イメージのアップロード
次にlinuxkit pushコマンドでアップロードを行います。
# 作成したイメージをさくらのクラウドへアップロード $ linuxkit push sakuracloud sakuracloud.raw
デフォルトではイメージファイル名の拡張子を除いたものがさくらのクラウドのアーカイブ名として利用されます。
この例ではsakuracloudという名前でアーカイブが作成されます。
実行!!
いよいよサーバの作成/起動です。
linuxkit runコマンドにアップロードしたアーカイブ名を指定することで起動できます。
# アップロードしたアーカイブを利用してサーバ作成/起動 $ linuxkit run sakuracloud sakuracloud
現在は以下のオプションが利用可能です。
-name: 作成されるサーバの名称(デフォルトではアーカイブ名と同じになる)-core: 作成されるサーバのコア数(デフォルト1)-memory: 作成されるサーバのメモリサイズ、単位はGB(デフォルト1)-disk-size: 作成されるサーバのディスクサイズ、単位はGB(デフォルト20)
-coreと-memoryの組み合わせによってはサーバ作成時にエラーとなりますので、以下のドキュメントを参考にサポートされている組み合わせを指定してください。
作成されたら以下のコマンドでSSH接続可能です。
(定義ファイルの内容によってはSSH接続できない場合もあります)
$ ssh -i your-private-key-path root@サーバのグローバルIP
もしSSH接続できないイメージを作成した場合、SSH接続の代わりにさくらのクラウドCLIであるusacloudを用いてVNC接続を行うことも可能です。
# usacloudでVNC接続 $ usacloud server vnc [サーバ名 or サーバID]
終わりに
今回はmobyとlinuxkitを用いてさくらのクラウド上でコンテナプラットフォームを簡単に構築する方法をご紹介しました。
linuxkitを用いれば特定機能に特化したイメージを簡単に作成でき、アップロード/サーバ作成と起動も手軽に行えますね。
ぜひお試しください。以上です。
Docker/InfraKitのインスタンスプラグインの作り方
今回はDocker/InfraKitのインスタンスプラグインの書き方について扱います。
はじめに
今回のゴール
当記事では以下2点をゴールとしています。
これらの解説のために、最小限の機能しか持たないインスタンスプラグインを(Go言語を用いて)ステップバイステップで作成してみます。
想定読者
- InfraKitのチュートリアルを一通りこなした方
- Go言語(初心者レベル)の開発スキルをお持ちの方
なお、インスタンスプラグインの作成に関しては、Dockerについての知識は不要です。
執筆時点でのInfraKitのバージョン
当記事執筆時点での最新版を利用しました。
InfraKitはガンガンとバージョンが上がり、SPIの定義も頻繁に変わります。
あくまで現時点での情報という点は留意ください。
0. 準備編
まずはInfraKitそのものについて全体像を簡単に押さえておきましょう。
InfraKitの役割
InfraKitとは一言で言うとインフラストラクチャのオーケストレーションを行うためのツールキットとのことです。
分散システムの構築や、インフラストラクチャの上流でコンテナなどのオーケストレーションを行うために、
- インフラストラクチャの状態を、
- ユーザがあらかじめ定義した状態に「保つ」こと
を目的としています。
状態を保つために、
- インフラストラクチャの現在の状態を把握
- 必要に応じて作成/破棄
を行います。
InfraKit = Group/Flavor/Instanceの3つのプラグイン(役割)の協調動作
以下の3つのプラグイン(役割)から構成されています。
Group(グループ)
個々のインスタンスをなんらかのルールで束ねたグループとして管理する役割を持ちます。
以下のような操作が行えるようになっています。
- グループの定義を受け取り、グループの管理を開始する
- グループの状態を把握する
- グループを破棄する
Instance(インスタンス)
グループのメンバーとなるインスタンスの操作/管理を行う役割を持ちます。
グループからの指示を受け、以下のような作業を行います。
Flavor(フレーバー)
グループ内のメンバーがどう動作をすべきかを定義する役割を持ちます。
- メンバーが実行すべきサービス(コマンド)の定義
- サービス(コマンド)が動作しているかの確認(ヘルスチェック)
なお、NTTの大嶋さん(InfraKitのコアメンテナ!!)が以下のような全体図を書かれています。
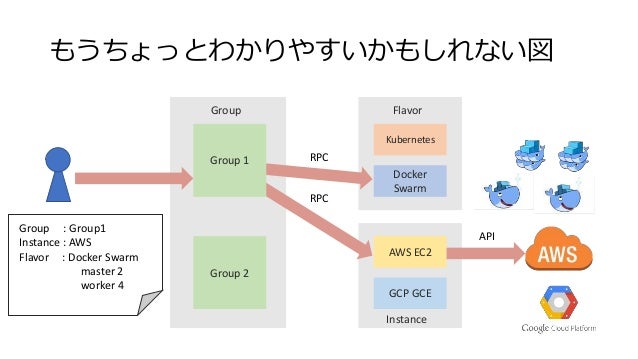
インフラ構成を定義としてグループに与えたら、構築や監視をよしなにやってくれるという感じですね。
各プラグインの実体
各プラグインは特定のAPIを持ったHTTPサーバで、UNIXドメインソケットでリッスンし、JSON-RPC2.0でやり取りします。
プラグインは共通のディレクトリ(通常は~/.infrakit/plugins)にソケットファイルを作成することで、
お互いに発見/呼び出しを行えるようになっています。
各プラグインが持つべきAPIは以下にドキュメントがあります。
各プラグインはGoで書く必要はなく、お好きなプログラミング言語を用いて作成することが可能です。
なお、Goを用いてプラグインを作成する場合、InfraKit側から提供されている便利なユーティリティ/ライブラリが利用可能です。
参考: https://github.com/docker/infrakit/tree/master/pkg/rpc
infrakitCLIについて
プラグインの状態確認や操作を簡単にするために、開発用CLI(コマンド)であるinfrakitが提供されています。
参考: https://github.com/docker/infrakit/blob/master/cmd/infrakit/README.md
InfraKitの実行自体に必須というわけではないのですが、あると便利ですので当記事でも利用していきます。
もしまだお手元にinfrakitコマンドがない場合はInfraKitのチュートリアルを参考にビルドしておいてください。
参考: InfraKitチュートリアル
ということで、これらの知識を持った上で早速プラグインの作成をしてみましょう。
今回作成するインスタンスプラグインについて
今回は最小限の機能しか持たないインスタンスプラグインをinfrakit-instance-minimumという名前で作成してみます。
GitHub: infrakit-instance-minimum
このプラグインは以下のような機能を持っています。
InfraKitが提供しているインスタンスプラグインのサンプル実装のfileインスタンスプラグインを参考にしていますが、
より機能を削り必要最低限のコードしか持たないものになっています。
1. 何もしないプラグインの作成
最初の段階として、何もしないプラグインを実装しInfraKitで認識できるところまでを実装してみます。
infrakitコマンドで起動しているプラグインを確認
まずはinfrakitコマンドで起動しているプラグインを確認してみます。
$ build/infrakit plugin ls
INTERFACE LISTEN NAME
現時点では何も起動していませんので何も表示されないのが正解です。
もし何かプラグインを起動しておいた場合は以下のような表示になります。
$ build/infrakit plugin ls
INTERFACE LISTEN NAME
Instance/0.6.0 ~/.infrakit/plugins/instance-file instance-file
プラグインの作成
GoでInfraKitのプラグインを作成する場合、InfraKit側から提供されているユーティリティを用いることで楽に実装可能です。
具体的には以下の実装を行うだけでインスタンスプラグインとして動作させることが可能です。
SPIとはService Provider Interfaceの略です。
以下のようにGoのインターフェースとして定義されていますので、これを満たす実装を行なっていきます。
// Plugin is a vendor-agnostic API used to create and manage resources with an infrastructure provider. type Plugin interface { // Validate performs local validation on a provision request. Validate(req *types.Any) error // Provision creates a new instance based on the spec. Provision(spec Spec) (*ID, error) // Label labels the instance Label(instance ID, labels map[string]string) error // Destroy terminates an existing instance. Destroy(instance ID, context Context) error // DescribeInstances returns descriptions of all instances matching all of the provided tags. // The properties flag indicates the client is interested in receiving details about each instance. DescribeInstances(labels map[string]string, properties bool) ([]Description, error) }
ソース: https://github.com/docker/infrakit/blob/master/pkg/spi/instance/spi.go
開発用にディレクトリ作成
まず、作成するプラグイン用のソースを格納するディレクトリを作成します。
mkdir infrakit-instance-minimum; cd infrakit-instance-minimum
以降はこのディレクトリ内で作業します。
インスタンスプラグインのSPIを実装(空の実装)
次にSPIの実装をplugin.goとして以下のように作成します。
plugin.go
package main import ( "github.com/docker/infrakit/pkg/types" "github.com/docker/infrakit/pkg/spi/instance" ) type plugin struct{} func NewMinimumInstancePlugin() instance.Plugin { return &plugin{} } func (p *plugin) Validate(req *types.Any) error { return nil } func (p *plugin) Provision(spec instance.Spec) (*instance.ID, error) { return nil, nil } func (p *plugin) Label(instance instance.ID, labels map[string]string) error { return nil } func (p *plugin) Destroy(instance instance.ID, context instance.Context) error { return nil } func (p *plugin) DescribeInstances(labels map[string]string, properties bool) ([]instance.Description, error) { return []instance.Description{}, nil }
SPIを実装したプラグインを起動するためのエントリーポイント作成
次に、プラグインを起動するエントリーポイントとしてmain.goを以下のように作成します。
main.go
package main import ( "github.com/docker/infrakit/pkg/cli" instance_plugin "github.com/docker/infrakit/pkg/rpc/instance" ) func main() { cli.RunPlugin("instance-minimum", instance_plugin.PluginServer(NewMinimumInstancePlugin())) }
ビルド & 起動
これだけでInfraKitのインスタンスプラグインとしての最低限の体裁が整っています。
早速ビルドして起動し、infrakitコマンドから認識できているか確認してみましょう。
(GOPATHの設定とかは適当にやっておいてくださいね。)
#ビルド $ go build #起動(フォアグラウンド起動) $ ./infrakit-instance-minimum INFO[0000] Listening at: ~/.infrakit/plugins/instance-minimum INFO[0000] PID file at ~/.infrakit/plugins/instance-minimum.pid
起動できたら、別のコンソールなどからinfrakitコマンドで確認してみましょう。
$ build/infrakit plugin ls
INTERFACE LISTEN NAME
Instance/0.6.0 ~/.infrakit/plugins/instance-minimum instance-minimum
無事に確認できましたね?おめでとうございます!これでインスタンスプラグインが作成できました!!!
とはいえ、実装は空ですのでこのままでは何もできません。次の段階ではもう少し実装を足してみましょう。
2. インスタンスの作成処理の実装
続いて、もう少しインスタンスプラグインらしくするために、インスタンスの生成処理を実装してみます。
具体的には、以下のような定義をグループプラグインに与えることでインスタンスの生成が行えるようにしてみます。
{
"ID": "example",
"Properties": {
"Allocation": {
"Size": 3
},
"Instance": {
"Plugin": "instance-minimum",
"Properties": {}
},
"Flavor": {
"Plugin": "flavor-vanilla",
"Properties": {}
}
}
}
グループプラグインの起動と定義ファイル(JSON)の作成
まずはグループプラグインを起動しておきましょう。
グループプラグインの実装には、InfraKitが提供するデフォルト実装であるinfrakit-group-defaultを利用します。
また、フレーバープラグインも必要となりますので起動しておきます。
フレーバープラグインの実装には、InfraKitが提供するサンプルであるinfrakit-flavor-vanillaを利用します。
#グループプラグイン(default)の起動 $ build/infrakit-group-default #フレーバープラグイン(vanilla)の起動 $ build/infrakit-flavor-vanilla
起動後、infrakit plugin lsの結果が以下のようになるはずです。
$ build/infrakit plugin ls
INTERFACE LISTEN NAME
Flavor/0.1.0 ~/.infrakit/plugins/flavor-vanilla flavor-vanilla
Group/0.1.0 ~/.infrakit/plugins/group group
Metadata/0.1.0 ~/.infrakit/plugins/group group
Instance/0.6.0 ~/.infrakit/plugins/instance-minimum instance-minimum
続いて定義ファイル(JSON)を以下のように作成しておきます。
$ vi example.json #以下の内容を記述 { "ID": "example", "Properties": { "Allocation": { "Size": 3 }, "Instance": { "Plugin": "instance-minimum", "Properties": {} }, "Flavor": { "Plugin": "flavor-vanilla", "Properties": {} } } }
infrakitコマンドでグループプラグインに定義を渡す
作成した定義ファイルをグループプラグインに渡してみましょう。 定義ファイルの内容は以下のようになっています。
以下のコマンドでグループプラグインに定義を渡せます。
$ build/infrakit group commit example.json [...省略...] INFO[0021] Committing group example (pretend=false) Committed example: Managing 3 instances INFO[0021] Adding 3 instances to group to reach desired 3 panic: runtime error: invalid memory address or nil pointer dereference [signal SIGSEGV: segmentation violation code=0x1 addr=0x0 pc=0x140c474] goroutine 40 [running]: github.com/docker/infrakit/pkg/plugin/group.(*scaledGroup).CreateOne(0xc4201f2460, 0x0) /go/src/github.com/docker/infrakit/pkg/plugin/group/scaled.go:102 +0x6d4 github.com/docker/infrakit/pkg/plugin/group.(*scaler).converge.func2(0xc42016e9e0, 0xc420170730) /go/src/github.com/docker/infrakit/pkg/plugin/group/scaler.go:277 +0x63 created by github.com/docker/infrakit/pkg/plugin/group.(*scaler).converge /go/src/github.com/docker/infrakit/pkg/plugin/group/scaler.go:278 +0x6c2
3つのインスタンスを追加しようとしていますが、エラーが出ていますね。
これはインスタンスプラグインの実装が空だからです。また実装後に改めて試すことにしましょう。
なお、グループプラグインが異常終了してしまうために~/.infrakit/plugin/groupにファイルが残ったままになっています。
このままだと、次回グループプラグインを起動するときにエラーとなりますので手動で削除し、改めてグループプラグインを起動しておきましょう。
$ rm ~/.infrakit/plugins/group #あらためてグループプラグインを起動 $ build/infrakit-group-default
インスタンスの作成処理(Provision)の実装
ではもう少し実装を進めます。まずはインスタンスの作成処理を担当するProvisionメソッドを実装します。
plugin.goに追記していくのですが、追記内容が若干多いため、詳しい内容は以下の変更差分を参照してください。
- ソース: https://github.com/yamamoto-febc/infrakit-instance-minimum/blob/2e035ef8b1e0b99293cd5d76f6265b9a41818366/plugin.go
- 変更差分
Provisionメソッドは以下のように修正されています。
plugin.goのProvisionメソッド
func (p *plugin) Provision(spec instance.Spec) (*instance.ID, error) { // ランダムなIDを生成 id := instance.ID(fmt.Sprintf("instance-%d", rand.Int63())) path := filepath.Join(instanceDir, string(id)) // ディレクトリ(/tmp/infrakit-dummy-instances)がなければ作成 _, err := os.Stat(instanceDir) if err != nil { err := os.MkdirAll(instanceDir, os.FileMode(0777)) if err != nil { return nil, err } } // ファイル作成 if _, err := os.Stat(path); err != nil { f, err := os.Create(path) if err != nil { return nil, err } defer f.Close() } return &id, nil }
引数のinstance.Spec経由でグループプラグインに与えた設定内容を参照できるのですが、今回は利用していません。
本来はここで与えられた設定を読み込み、必要なインスタンス生成処理を行います。
今回はインスタンス生成の代わりに"instance-“+ランダムな数値という名前のファイルを作成するだけにしています。
次にProvisionの戻り値についてですが、instance.IDへの参照を返すことになっています。
今回はファイル名をそのままIDとして利用しています。
本来はインスタンスを一意に特定できるIDを生成または取得して返すように実装します。 (例:AWSだったらEC2のリソースIDを返す、など)
実行!!
ではビルドして実行してみましょう。古いインスタンスプラグインは一旦停止(ctrl+cでOK)し、改めてビルド&起動してください。
起動したら以下のコマンドを実行してみましょう。
Provisionを実装したインスタンスプラグインを実行
#グループプラグインへ設定ファイルを受け渡し $ build/infrakit group commit example.json [...省略...] INFO[2638] Committing group example (pretend=false) Committed example: Managing 3 instances INFO[2638] Adding 3 instances to group to reach desired 3 INFO[2638] Created instance instance-4559224122183623453 with tags map[infrakit.config_sha:cvb62mzivlzgdtja24rczqhdtktqx2sn infrakit.group:example] INFO[2638] Created instance instance-3099390593271315395 with tags map[infrakit.config_sha:cvb62mzivlzgdtja24rczqhdtktqx2sn infrakit.group:example] INFO[2638] Created instance instance-4785619793559779603 with tags map[infrakit.config_sha:cvb62mzivlzgdtja24rczqhdtktqx2sn infrakit.group:example]
うまくいきましたね!!/tmp/infrakit-dummy-instances/配下にファイルが3つ作成されていることが確認できるはずです。
ですが、、、少々問題があることに気づくかもしれません。
問題: ファイルがどんどん増えていく!?!?
しばらく待つと以下のようなログが表示され、/tmp/infrakit-dummy-instances/配下にファイルがどんどん増えていっているはずです。
INFO[2648] Created instance instance-1391249888231321150 with tags map[infrakit.config_sha:cvb62mzivlzgdtja24rczqhdtktqx2sn infrakit.group:example] INFO[2648] Created instance instance-4551305389484104975 with tags map[infrakit.config_sha:cvb62mzivlzgdtja24rczqhdtktqx2sn infrakit.group:example] INFO[2648] Created instance instance-102084934595871505 with tags map[infrakit.group:example infrakit.config_sha:cvb62mzivlzgdtja24rczqhdtktqx2sn]
原因: InfraKitがインスタンスの状態を知らないから
これは、InfraKitが現在インスタンスがどのような状態かを知らない = 存在しないと思っているために、毎回インスタンスを作ろうとしてしまうことが原因です。
まあそんな処理は実装してないから当たり前ですね。
ということで、次はこの「インスタンスの状態を調べる」 = DescribeInstancesメソッドを実装していきます。
後片付け
このままではファイルが延々と増え続けてしまいます。このため、グループプラグインにこのグループの破棄を指示しておきましょう。
ついでに今回インスタンスプラグインが作成したファイルも削除しておきます。
# group destroyを実施(引数にはグループのIDを指定) $ build/infrakit group destroy example # インスタンスプラグインが作成したダミーファイルを削除しておく $ rm /tmp/infrakit-dummy-instances/*
3. インスタンスの状態を調べるDescribeInstancesの実装
続いてDescribeInstancesを実装しましょう。
plugin.goに追記していくのですが、追記内容が若干多いため、詳しい内容は以下の変更差分を参照してください。
- ソース:https://github.com/yamamoto-febc/infrakit-instance-minimum/blob/ef5f497a23021cab9a04aefac87b3749e3639de2/plugin.go
- 変更差分
plugin.goのDescribeInstanceメソッド
func (p *plugin) DescribeInstances(labels map[string]string, properties bool) ([]instance.Description, error) { // ディレクトリ(/tmp/infrakit-dummy-instances)配下のファイルを取得 entries, err := ioutil.ReadDir(instanceDir) if err != nil { return nil, err } result := []instance.Description{} // インスタンス情報の組み立て for _, entry := range entries { result = append(result, instance.Description{ ID: instance.ID(entry.Name()), }) } return result, nil }
ここでは/tmp/infrakit-dummy-instancesディレクトリ配下に存在するファイルを参照し、インスタンス情報を組み立てています。
本来は、DBを参照したり、APIを呼び出すなどで現在のインスタンスたちの情報を組み立ててあげる処理となります。
実行!!
ではビルドして実行してみましょう。先ほどと同じく、古いインスタンスプラグインは一旦停止(ctrl+cでOK)し、改めてビルド&起動してください。
起動したら以下のコマンドを実行してみましょう。
Provisionを実装したインスタンスプラグインを実行
#グループプラグインへ設定ファイルを受け渡し $ build/infrakit group commit example.json [...省略...] INFO[3889] Committing group example (pretend=false) Committed example: Managing 3 instances INFO[3889] Adding 3 instances to group to reach desired 3 INFO[3889] Created instance instance-377673683573739334 with tags map[infrakit.group:example infrakit.config_sha:cvb62mzivlzgdtja24rczqhdtktqx2sn] INFO[3889] Created instance instance-8516032680601656640 with tags map[infrakit.group:example infrakit.config_sha:cvb62mzivlzgdtja24rczqhdtktqx2sn] INFO[3889] Created instance instance-6082236286152429340 with tags map[infrakit.group:example infrakit.config_sha:cvb62mzivlzgdtja24rczqhdtktqx2sn]
今度はしばらく待ってもファイルがどんどん増えなくなっているはずです。
動作確認: インスタンス(の代わりのファイル)を消してみる
それではInfraKit自体の動作確認になるのですが、/tmp/infrakit-dummy-instances配下のファイルを消してみましょう。
InfraKitは変更を検知し、あらかじめ決められたインスタンス数(今回は3)を保つために新たなインスタンスの作成を行います。
$ rm /tmp/infrakit-dummy-instances/いずれかのファイル # 数秒待つと、InfraKitが自動的に検知し、インスタンス(ファイル)が新たに作成される
問題: ファイルが消えない??
今度は逆にインスタンス(の代わりのファイル)を増やしてみましょう。 先ほどと同じように、あらかじめ決められたインスタンス数(今回は3)を保つためにインスタンスの削除が行われるはずです。
$ touch /tmp/infrakit-dummy-instances/instance-00000000 # 数秒待つと、InfraKitが自動的に検知するが、、、 INFO[4882] Removing 1 instances from group to reach desired 3 INFO[4882] Destroying instance instance-000000000 INFO[4892] Removing 1 instances from group to reach desired 3 INFO[4892] Destroying instance instance-000000000 INFO[4902] Removing 1 instances from group to reach desired 3 INFO[4902] Destroying instance instance-000000000 [...以降延々と続く...]
原因: インスタンスの削除処理を実装していないから
今回は予想がつくかと思いますが、インスタンスの削除処理を実装していないからですね。
ということで、次はこの「インスタンスを削除する」 = Destroyメソッドを実装していきます。
後片付け
先ほどと同じく後片付けを実行しておいてください。
# group destroyを実施(引数にはグループのIDを指定) $ build/infrakit group destroy example # インスタンスプラグインが作成したダミーファイルを削除しておく $ rm /tmp/infrakit-dummy-instances/*
4. インスタンスを削除するDestroyの実装
続いてDestroyを実装しましょう。
plugin.goに追記していくのですが、追記内容が若干多いため、詳しい内容は以下の変更差分を参照してください。
- ソース: https://github.com/yamamoto-febc/infrakit-instance-minimum/blob/1d8e324d53585321136699a375e83c2d473f2f1c/plugin.go
- 変更差分
plugin.goのDestroyメソッド
func (p *plugin) Destroy(instance instance.ID, context instance.Context) error { path := filepath.Join(instanceDir, string(instance)) _, err := os.Stat(path) if err == nil { //ファイルが存在する場合は削除 return os.Remove(path) } return nil }
完成!実行してみましょう!!
先ほどまでと同じです。
#グループプラグインへ設定ファイルを受け渡し $ build/infrakit group commit example.json [...省略...] INFO[3889] Committing group example (pretend=false) Committed example: Managing 3 instances INFO[3889] Adding 3 instances to group to reach desired 3 INFO[3889] Created instance instance-377673683573739334 with tags map[infrakit.group:example infrakit.config_sha:cvb62mzivlzgdtja24rczqhdtktqx2sn] INFO[3889] Created instance instance-8516032680601656640 with tags map[infrakit.group:example infrakit.config_sha:cvb62mzivlzgdtja24rczqhdtktqx2sn] INFO[3889] Created instance instance-6082236286152429340 with tags map[infrakit.group:example infrakit.config_sha:cvb62mzivlzgdtja24rczqhdtktqx2sn]
今度はインスタンスの削除処理が正常に行われるはずです。
$ touch /tmp/infrakit-dummy-instances/instance-00000000 # しばらく待つとInfraKitが検知してインスタンス削除処理を実施 INFO[5398] Removing 1 instances from group to reach desired 3 INFO[5398] Destroying instance instance-000000000
これで最低限の機能を持つインスタンスプラグインが作成できました。
本来はフレーバープラグインでの設定の反映なども行わないといけないのですが、その辺は必要に応じて既存のプラグインのソースを解析してみてください。
最後に、plugin.goのソース全体を載せておきます。
package main import ( "fmt" "github.com/docker/infrakit/pkg/spi/instance" "github.com/docker/infrakit/pkg/types" "math/rand" "os" "path/filepath" "io/ioutil" ) var ( instanceDir = "/tmp/infrakit-dummy-instances" ) type plugin struct{} func NewMinimumInstancePlugin() instance.Plugin { return &plugin{} } func (p *plugin) Validate(req *types.Any) error { return nil } func (p *plugin) Provision(spec instance.Spec) (*instance.ID, error) { // ランダムなIDを生成 id := instance.ID(fmt.Sprintf("instance-%d", rand.Int63())) path := filepath.Join(instanceDir, string(id)) // ディレクトリ(/tmp/infrakit-dummy-instances)がなければ作成 _, err := os.Stat(instanceDir) if err != nil { err := os.MkdirAll(instanceDir, os.FileMode(0777)) if err != nil { return nil, err } } // ファイル作成 if _, err := os.Stat(path); err != nil { f, err := os.Create(path) if err != nil { return nil, err } defer f.Close() } return &id, nil } func (p *plugin) Label(instance instance.ID, labels map[string]string) error { return nil } func (p *plugin) Destroy(instance instance.ID, context instance.Context) error { path := filepath.Join(instanceDir, string(instance)) _, err := os.Stat(path) if err == nil { //ファイルが存在する場合は削除 return os.Remove(path) } return nil } func (p *plugin) DescribeInstances(labels map[string]string, properties bool) ([]instance.Description, error) { // ディレクトリ(/tmp/infrakit-dummy-instances)配下のファイルを取得 entries, err := ioutil.ReadDir(instanceDir) if err != nil { return nil, err } result := []instance.Description{} // インスタンス情報の組み立て for _, entry := range entries { result = append(result, instance.Description{ ID: instance.ID(entry.Name()), }) } return result, nil }
おまけ: 今回未実装のメソッド/追加で実装した方が良いメソッド
今回未実装のメソッド
今回はインスタンスプラグインのSPIのうち、以下を実装しませんでした。
- Validate(req *types.Any) error
- Label(instance instance.ID, labels map[string]string) error
それぞれ簡単に役割を説明しておきます。
Validate(req *types.Any) error
その名の通り検証を行うメソッドです。
グループプラグイン経由で定義したインスタンスプロパティ関連の値が渡ってくるため、ここで検証処理を行います。
Label(instance instance.ID, labels map[string]string) error
インスタンスに"ラベル"をつけるためのメソッドです。
具体的にはキーと値がlabelsに入ってくるため、これをインスタンスと紐付けます。
自前のDBに保持したり、クラウド上のインスタンスであればメタデータとして登録したりします。
なお、拙作infrakit.sakuracloudでは、さくらのクラウドのサーバのDescriptionという文字列を格納するための属性に保持するように実装しました。
さくらのクラウドではサーバにメタデータを紐づける仕組みがなかったために苦肉の策というところでした。
(なお、さくらのクラウドにはタグという機能もあるのですが、文字数の制限があるために利用できませんでした)
追加で実装した方が良いメソッド
全てのプラグインは以下のインターフェースについても実装しておいた方が良さそうです。
github.com/docker/infrakit/pkg/spiパッケージの
VendorインターフェースInputExampleインターフェース
それぞれCLIなどに対し情報を返すためのメソッドです。
Vendorインターフェースは各プラグインの名称やバージョンなどを返すためのメソッドです。
今の所InfraKit側でこの情報を使っている部分はなさそうなのですが、AWS/GCP/DigitalOceanなどのインスタンスプラグインでも実装されていますので、なるべく実装しておいた方が良さそうな感じがしています。
InputExampleインターフェースは、そのプラグインがどのようなプロパティが設定できるのかの例を定義するメソッドです。
cliなどから利用されています(infoサブコマンドなど)。
終わりに
当記事では最低限の機能を持つInfraKitのインスタンスプラグインをステップバイステップで作成しました。
実際にプラグインを作成する際はInfraKitのリポジトリ内にある他のインスタンスプラグインの実装も参考にするのが良いかと思います。
手始めにexamplesのfileプラグインのソースを読むことをお勧め致します。
これは当記事と同じようにインスタンスとしてダミーのファイルを作成する処理を行っています。
VendorインターフェースやInputExampleインターフェースの実装もされていますし、短いソースですので一度眼を通してみてください。
以上です。Enjoy!!
参考資料
パッケージ管理ツール「whalebrew」〜透過的にDocker上でコマンドを実行する環境を作る〜
「whalebrew」という素晴らしいプロダクトが出ていました。
Homebrewのような感じでコマンドをインストールし、かつそのコマンドをDocker上で実行できるように環境を整えてくれるツールです。
# whalebrewコマンドで"whalesay"コマンドをインストールしてみる
$ whalebrew install whalebrew/whalesay
# DockerHubからイメージのダウンロードが行われる
Unable to find image 'whalebrew/whalesay' locally
Using default tag: latest
latest: Pulling from whalebrew/whalesay
e190868d63f8: Extracting [=======================> ] 30.64 MB/65.77 MB
909cd34c6fd7: Download complete
0b9bfabab7c1: Download complete
a3ed95caeb02: Waiting
00bf65475aba: Waiting
c57b6bcc83e3: Waiting
8978f6879e2f: Waiting
8eed3712d2cf: Waiting
# ダウンロードしたイメージを実行できるように、/usr/local/bin配下にエイリアスが作成される
# 最終的に以下のようなコマンドでDocker上で実行されることになる
# docker run -it -v "$(pwd)":/workdir -w /workdir $IMAGE "$@"
🐳 Installed whalebrew/whalesay to /usr/local/bin/whalesay
# インストールしたコマンドは作成されたエイリアスを通じ実行できる
$ whalesay 'hello'
_________
< hello!! >
---------
\
\
\
## .
## ## ## ==
## ## ## ## ===
/""""""""""""""""___/ ===
~~~ {~~ ~~~~ ~~~ ~~~~ ~~ ~ / ===- ~~~
\______ o __/
\ \ __/
\____\______/
以下、簡単に使い方などをメモしておきます。
インストール
今の所はWindowsは非対応のようです。Linux/Macなら動くと思います。
以下のようにバイナリをダウンロードして実行権を付与するだけです。
curl -L "https://github.com/bfirsh/whalebrew/releases/download/0.0.1/whalebrew-$(uname -s)-$(uname -m)" -o /usr/local/bin/whalebrew; chmod +x /usr/local/bin/whalebrew
使い方
コマンドのインストール
$ whalebrew install オーガニゼーション/イメージ名
オーガニゼーション/イメージ名にはDockerHub上のものを指定します。

検索
検索は現状ではwhalebrewオーガニゼーション配下のイメージに対してのみ有効みたいです。
$ whalebrew search イメージ名
whalebrewでインストール済みのコマンド一覧表示
$ whalebrew list
更新(upgrade)
$ whalebrew upgrade オーガニゼーション/イメージ名
動作設定
現在はエイリアスを作成する先のディレクトリを変更できるようです。
デフォルトは/usr/local/binですが、以下の環境変数で変更可能です。
WHALEBREW_INSTALL_PATH
パスの通ったディレクトリを指定しましょう。
内部動作
コマンドをインストールすると、WHALEBREW_INSTALL_PATH(デフォルト/usr/local/bin)配下に以下のようなファイルが作成されます。
例: whalebrew/whalesayコマンドをインストールした場合
#!/usr/bin/env whalebrew image: whalebrew/whalesay
これを実行すると、以下のようなDockerコマンドが(whalebrewを通じて)実行されます。
docker run -it -v "$(pwd)":/workdir -w /workdir $IMAGE "$@"
注意点は、dockerでのWORKDIRが/workdirに固定となっている点です。
コマンド実行時のカレントディレクトリの内容がコンテナ内の/workdirにボリュームとして割り当てられます。
なお、後述しますが、Dockerイメージ側でラベルが指定されている場合はこのパスが変更できるようです。
注:dockerクライアント実行環境にもよりますが、~/配下など、コンテナにバインドマウント可能なディレクトリでないとコマンド実行できないっぽいですね。
公開するイメージの作り方
以下の2つの条件を満たすだけです。
- DockerHub上に公開すること
- イメージに
ENTRYPOINTが設定されていること
以下のLABELをイメージに設定(Dockerfileに記述)しておくことで、動作のカスタマイズができるようです。
io.whalebrew.name : whalebrewでインストールした場合のコマンド名。デフォルトではイメージ名となる。
io.whalebrew.config.environment : コンテナに渡す環境変数。以下のように指定する。
# コマンド実行時に$TERMと$FOOBAR_NAMEを引き渡しする(-eオプション) LABEL io.whalebrew.config.environment '["TERM", "FOOBAR_NAME"]'
io.whalebrew.config.volumes : コンテナに割り当てるボリューム。以下のように指定する。
# ~/.dockerをコンテナの/root/.dockerに読み取り専用で割り当て(-vオプション) LABEL io.whalebrew.config.volumes '["~/.docker:/root/.docker:ro"]'
まとめ
これまでDockerイメージで配布されていたアプリの場合、whalebrewを使えば楽に配布〜実行設定できますね。
dockerコマンドを直接叩いてもらわなくてよくなる、aliasを張る必要がなくなるなど嬉しいですね!
ぜひ流行って欲しいところです。
公開されたばかりのプロダクトですのでバグもあるかと思いますが積極的に使っていきたいです。
以上です。 Enjoy!!
【golang】vendoring時はビルドタグでのフィルタリングは使わない方がいい
English version:【golang】Don't use filtering by build tags to vendoring
TL;DR
govendorではvendoringする際に無視するビルドタグが指定できる- しかし、ビルドに必要なファイルがvendorディレクトリ配下にコピーされないケースがある
- 必要なファイルがコピーされないことにより、クロスコンパイルできなくなるといった問題が起こるかもしれない
- なので、vendorディレクトリのサイズは増えてしまうが、ビルドタグでのフィルタリングはしない方がシンプルで良い
Introduction
現在、Go言語には次のようにたくさんのパッケージ管理(vendoring)ツールがあります。
こちらのページでは他にもたくさんのツールが紹介されています。
PackageManagementTools · golang/go Wiki · GitHub
私はその中でも、govendorをよく利用しています。
govendor は簡単/手軽に利用できるため、これまでたくさんのプロジェクトで利用してきました。
でもある時、govendorの設定次第では面倒な問題が発生することがわかりました。。。
What is the problem?
先月(2016/12)、Terraformに対して以下のPullRequestを作成しました。
このPRは、Arukasプロバイダを追加するものです。
この新しいプロバイダは以下のリポジトリにてサードパーティープラグインとしてリリース済みであったものを
Terraform本体に取り込んでもらうためのものでした。
このPRはすぐにマージされ、Terraform v0.8.3としてリリースされました。
しかしその時、、、

Windowsでビルドできなくなった!?!?
What's!? What's happened!?!?
Arukasプロバイダーはサードパーティープラグインとしてのリリース時にWindows版を含んでおり、(Windows上でも)問題なくビルドできていました。
Terraform本体に取り込んでもらう際、ソースコードへの変更は行われていないのに、なぜビルドが壊れてしまったのでしょうか?
Who broke the build on Windows?
原因を探るため、@jbardinからのメッセージで指摘されているライブラリgopkg.in/alecthomas/kingpin.v2から調査を始めることにしました。
ライブラリgopkg.in/alecthomas/kingpin.v2はArukasプロバイダによってimportされているものです。
このライブラリは、Arukasプロバイダをサードパーティープラグインとしてリリースしていた頃から利用しているため、Windowsでも問題なく利用できることが判明しています。
かつ、Terraform本体 / サードパーティープラグインとしてリリースしていたArukasプロバイダ共にvendoringにはgovendorを利用しています。
このため、(govendorによって)vendorディレクトリ配下にコピーされたgopkg.in/alecthomas/kingpin.v2ライブラリのファイルを比較してみることにしました。
Compare gopkg.in/alecthomas/kingpin.v2 files under vendor directory
比較結果は以下の通りです。

guesswidth.goがなんらかの理由でコピーされていないようです。
なぜでしょうか???
Answer: govendor was setted to ignore some build tags
(Terraformにおける)govendorの設定ファイルvendor/vendor.json で以下のような設定が行われています。
https://github.com/hashicorp/terraform/blob/v0.8.4/vendor/vendor.json#L3
"ignore": "appengine test",
govendorはvendor/vendor.jsonの"ignore"に設定された各値とソースファイルの接尾詞 or ソースコード中のビルドタグを比較し、
対象のファイルを無視すべきか判定しています。
この設定ではappengineとtestというタグが無視対象として設定されているということです。
そして、今回コピーされていなかったguesswidth.goのビルドタグは以下のようになっていました。
https://github.com/alecthomas/kingpin/blob/v2.2.3/guesswidth.go#L1
// +build appengine !linux,!freebsd,!darwin,!dragonfly,!netbsd,!openbsd
なお、*nix系プラットフォーム(Linx/BSD/MacOSなど)ではこのファイルの代わりにguesswidth_unix.goが利用されます。
こちらのファイルのビルドタグは以下のようになっています。
https://github.com/alecthomas/kingpin/blob/v2.2.3/guesswidth_unix.go#L1
// +build !appengine,linux freebsd darwin dragonfly netbsd openbsd
これらのビルドタグが与えられている場合、(対象プラットフォームが)Windowsでのビルドではguesswidth.goの方が利用されます。
しかし、vendor.jsonの"ignore"にてappengineが指定されているため、govendorはguesswidth.goを無視してしまうのです!!!
(日本語版注 : govendorはビルドタグを解析し、一つでもignoreに設定されたタグとマッチするタグが指定されている場合は該当ファイルをvendor配下にコピーしないのです)
この状況では、*nix系プラットフォームではビルド出来ても、Windowsではビルド出来ないのです。
ではどうすれば良いのでしょうか??
Conclusion
vendoring時にビルドタグでフィルタリングすることは、vendorディレクトリのサイズ削減ができるという利点はありますが、
いくつかのプラットフォームでビルドできなくなるといった問題が発生する可能性があります。
さらに、これらの問題解決の際は、importしている各ファイルのビルドタグの確認といった面倒な調査が必要になるでしょう。
このため、vendoring時のビルドタグによるフィルタは利用しない方が良いです。
(注:ただし、ignoreタグとtestタグについてはフィルタしても問題なく動くと思います)
これらの問題があってもビルドタグによるフィルタリングを利用するユースケースはあるのでしょうか?
少なくとも私は思いつきませんでした。
あなたはどう思いますか?
もし良い方法があればこの記事にコメントをください!
2016年 活動まとめ
2016年も残すところ僅かとなりました。
今年は実り多い年だったので、忘れないうちに活動内容をまとめておきます。
全体的には?
オープンソース活動、記事執筆ともに順調な1年でした。
- アプリ開発 : 合計30本以上のリリース
- 記事執筆:Qiita / さくらのナレッジ / ブログ 、合計42本を執筆
- イベントでの発表: 1回/月程度の頻度で勉強会/イベントへ参加、うち3イベントで発表あり
GitHubのcontributionはこんな感じです。

傾向として、土日は家族と過ごすことが多いため、平日のコミットが多めとなっておりました。
アプリ開発の実績
アプリ単体でリリースしたものだけで15アプリ、記事連動したアプリやDockerイメージなどの細々したものを含めると30以上のアプリのリリースを行いました。
ライブラリ関連
さくらのクラウド用APIライブラリ「libsacloud」
docker-machine-sakuracloudで得た、Go言語でのさくらのクラウドAPI操作のノウハウを他のプロダクトでも利用できるようにするために
APIライブラリとしてスクラッチ開発を行いました。
このライブラリは現在でもバンバン開発しており、公式のAPIライブラリ:saklientよりも機能が充実していたりします。
さくらのクラウドへ新たな機能が追加された場合、概ね1週間以内には対応しています。
2016年に開発したプロダクトの多くがこのlibsacloudを利用する形となっているため、本年の本格的な活動開始がこのプロダクトで正解だったと思っています。
さくらのIoT Platform用APIライブラリ「sakuraio-api」
さくらのIoT Platform用のAPIライブラリです。
主に「Terraform for さくらのIoT Platform」での利用のために開発しました。
こちらは来年も順次充実させていく予定です。
なお、さくらのIoT Platform用のライブラリとしては、WebHook関連のライブラリとして以下のようなものもあります。
こちらは先の「sakuraio-api」に統合を予定しています。おそらく来年上旬あたりの対応となると思います。
Terraform関連
Terraform for さくらのクラウド
Terraform for Arukas
Terraform for さくらのIoT Platform
さくらのクラウド、Arukas、さくらのIoT Platformへの対応を行いました。
特にさくらのクラウドについてはさくらのナレッジにて入門記事の連載を執筆中ですので、引き続き対応を強化していきます。
Packer関連
Packer for さくらのクラウド
さくらのクラウド上にマシンイメージを作成するためのツール「Packer for さくらのクラウド」を作りました。 こちらは開発はひと段落させたつもりですので、来年は大きな機能追加などは行わずバグフィックス中心になる予定です。
Docker関連
Infrakit - さくらのクラウド用プラグイン
2016年10月に発表されたDockerの新しいアーキテクチャへの挑戦「infrakit」のプラグインとして、
さくらのクラウド対応を試験的に行ってみたものです。
infrakit対応プラグインとしては世界最速での開発/発表を行うことができました。
infrakit自体のDockerへの取り込みはまだまだ見えない要素も多いのですが、
infrakit.awsの実装など、具体的な実装ができつつありますので、様子を見ながらさくらのクラウド対応を行うことを視野に入れています。
WordPress関連
WordPress + オブジェクトストレージ用プラグイン「wp-sacloud-ojs」
WordPress + ウェブアクセラレータ用プラグイン「wp-sacloud-webaccel」
依然シェアNo.1であり続けているCMSの王様「WordPress」にて、さくらのクラウドのプロダクトを利用するためのプラグインを作りました。
こちらは開発はひと段落ついたかなーと感じているため、来年はバージョンアップ対応やバグフィックス中心になりそうです。
監視関連
Mackerelとさくらのクラウドのインテーグレーションツール「Sackerel」
はてなさんのイケてる監視ツール「Mackerel」とさくらのクラウドをインテグレーションするツールを作りました。
今後はMackerelだけでなく、もっと汎用的に利用できるようにすべくアイディアを練っている段階です。
PrometheusやZabbixなど他の監視ツールともうまく連携できる仕組みにできればいいなーと漠然と考えています。
その他:さくらのクラウド関連の細々したツール類
さくらのクラウド上の全リソース削除コマンド「sacloud-delete-all」
さくらのクラウドへのISOイメージアップロードコマンド「sacloud-upload-image」
さくらのクラウドへのアーカイブアップロードコマンド「sacloud-upload-archive」
細かいCLIツールを作成しました。
各ツールがバラバラに存在してしまっていることや、公式CLIである「sacloud」の開発が停滞していることもあり、
そろそろさくらのクラウド関連のCLIツールをまとめて再編してコミュニティーツールとして提供するのがいいかな?とも考えています。
この辺りは考えがまとまっていないので来年はじっくり取り組むつもりです。
その他:Arukas関連のツール類
プルリクエスト駆動開発用デプロイパイプラインツール「arukas-ship」
GitHub〜DockerHub〜Arukasとデプロイパイプラインを形成するためのツールです。
GitHubにpushするだけでArukasへデプロイできます。
このツールはQiitaに紹介記事を書いたのですが、
投稿から半年近く経っても徐々にストック/PVが伸びている息の長いプロダクトだったりします。
Arukas関連のプロダクトについては、来年4月の正式リリースに合わせ、見直し/更新などを行う予定です。
その他:オープンソースプロダクト開発への参加
docker-machineやpackerなどへのコントリビューションを行いました。
記事の執筆(全42本)
Qiitaへの投稿(34本)
Qiitaへは大小合わせて34本記事を投稿しました。
特に印象深い記事をいくつかピックアップしておきます。
DockerBlogからの翻訳&紹介記事なのですが、非常に興味深い内容でした。
CGIのように、リクエストを受けたらDockerコンテナを起動し処理するという内容ですが、
Dockerを用いたサーバーレスな構成の一例として非常にインスピレーションを刺激してくれました。
Docker + infrakitについての紹介です。
未だにinfrakitについて国内のみならず海外でも情報が少ないです。貴重な日本語記事ではあるのですが、
すでに若干コードの更新などが行われていますので、もしinfrakitに大きめな動きがあるようであれば新たに記事を投稿するつもりです。
HashicorpのNomadを利用した環境構築例です。
Nomadはもっと流行ってもいい気はするのですが、、コンテナ界隈、特にオーケストレーション周りの熾烈な争いの中で
Nomadは今ひとつ突き抜けられない感じがしていますので、しばらくは概要を軽く様子見する程度で良いかなーと感じてます。
さくらのナレッジへの投稿(6本)
月に1本程度のペースで投稿しています。
現在はTerraformについての連載を行なっています。
連載中ではありますが、面白いものを思い付いたら連載の合間でも差し込みで投稿する予定です。
その他(2本)
Qiitaでのさくらのアドベントカレンダーに2本記事を投稿しました。
イベント参加などのコミュニティー活動
月に1回程度のペースで各種勉強会への参加など行いました。
その中で、発表を行ったのは以下3つでした。
「さくらインターネット」のDockerホスティング「Arukas」と「Docker Machine」ドライバについてのイベント
4/27 にArukasの発表のついでにdocker-machine-sakuracloudについてお話しさせていただきました。
この時の資料はこちらです。
さくらじまハウス
資料はこちらです。
東京で消耗したくない!」西日本にいながら”IT界隈の人”になったエンジニアと交流する会in北九州
発表の場がちょっと少なかったので、来年はどなたかぜひ招待してください!どこかで喋りたいです!
まとめ
ということで1年を振り返ってみました。
割と濃い開発/執筆活動ができたかなと思います。
来年はもっと喋る機会が増やせればいいなーと思っています。
イベントを企画中の方がいらっしゃいましたらぜひ招待してください!喜んで参加します!
以上です。